




最后

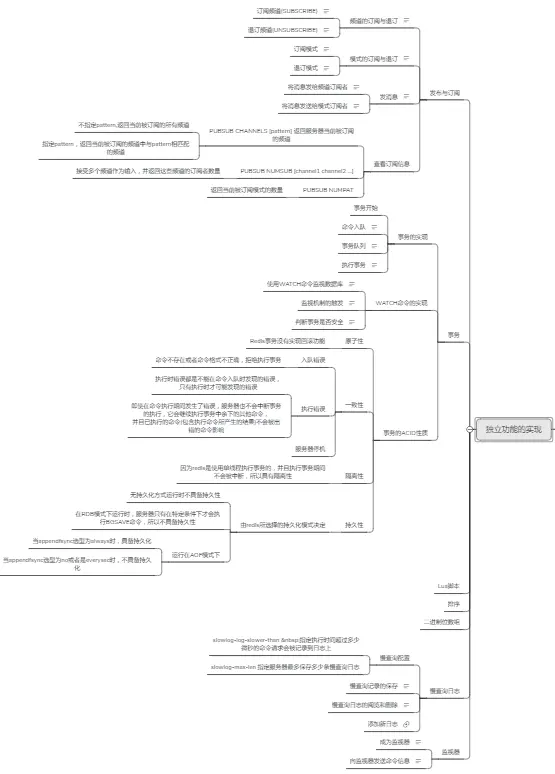
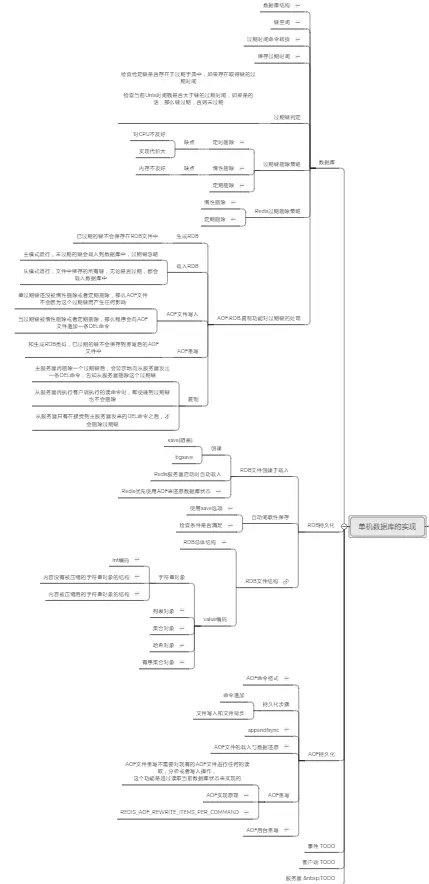
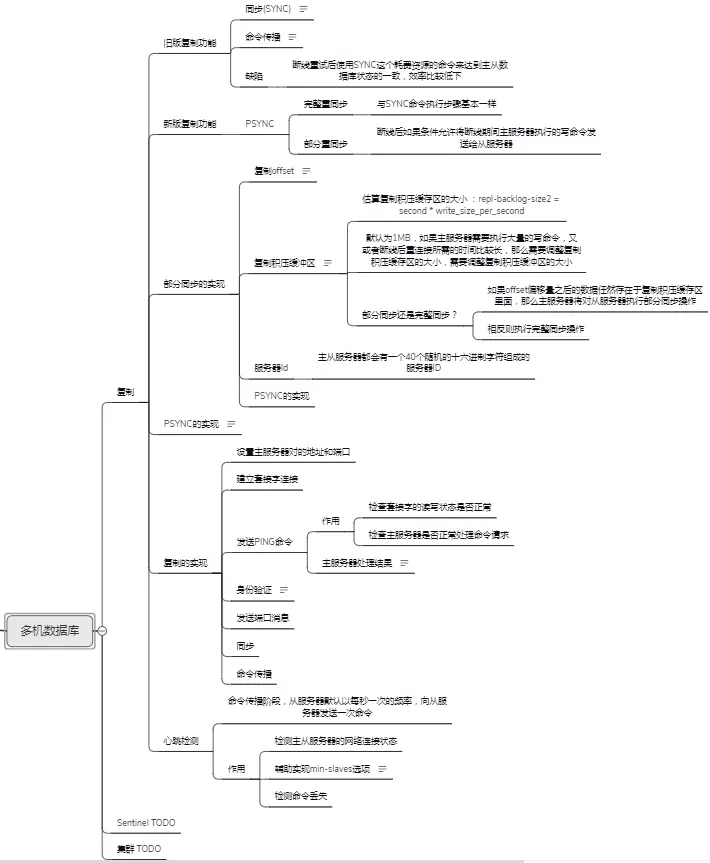
由于篇幅原因,就不多做展示了
接下来,我们就以代码案例的形式来分析各种内存溢出的情况。
首先,我们创建一个类叫做BlowUpJVM,所有的案例实验都是基于这个类进行。
public class BlowUpJVM {
}
public static void testStackOverFlow(){
BlowUpJVM.testStackOverFlow();
}
栈不断递归,而且没有处理,所以虚拟机栈就不断深入不断深入,栈深度就这样溢出了。
public static void testPergemOutOfMemory1(){
//方法一失败
List list = new ArrayList();
while(true){
list.add(UUID.randomUUID().toString().intern());
}
}
打算把String常量池堆满,没想到失败了,JDK1.7后常量池放到了堆里,也能进行垃圾回收了。
然后换种方式,使用cglib,用Class把老年代取堆满
public static void testPergemOutOfMemory2(){
try {
while (true) {
Enhancer enhancer = new Enhancer();
enhancer.setSuperclass(OOM.class);
enhancer.setUseCache(false);
enhancer.setCallback(new MethodInterceptor() {
@Override
public Object intercept(Object obj, Method method, Object[] args, MethodProxy proxy) throws Throwable {
return proxy.invokeSuper(obj, args);
}
});
enhancer.create();
}
}
catch (Exception e){
e.printStackTrace();
}
}
虚拟机成功内存溢出了,那JDK动态代理产生的类能不能溢出呢?
public static void testPergemOutOfMemory3(){
while(true){
final OOM oom = new OOM();
Proxy.newProxyInstance(oom.getClass().getClassLoader(), oom.getClass().getInterfaces(), new InvocationHandler() {
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
Object result = method.invoke(oom, args);
return result;
}
});
}
}
事实表明,JDK动态代理差生的类不会造成内存溢出,原因是:JDK动态代理产生的类信息,不会放到永久代中,而是放在堆中。
public static void testNativeMethodOutOfMemory(){
int j = 0;
while(true){
Printer.println(j++);
ExecutorService executors = Executors.newFixedThreadPool(50);
int i=0;
惊喜
最后还准备了一套上面资料对应的面试题(有答案哦)和面试时的高频面试算法题(如果面试准备时间不够,那么集中把这些算法题做完即可,命中率高达85%+)


5866)]

















 7759
7759

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









