




网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
//该位置首次添加节点,则直接新建节点添加
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
//如果节点是红黑树,调用方法进行添加元素
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
//如果节点是链表,则遍历链表
for (int binCount = 0; ; ++binCount) {
//遍历链表到最后一个节点
if ((e = p.next) == null) {
//新建节点进行添加
p.next = newNode(hash, key, value, null);
//如果遍历指定位置的链表现有节点已经是大于等于8个了
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
//则当前节点,需要通过该方法进行添加
//如果数组容量大于64,该过程会进行链表转化为红黑树
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
//HashMap对于key已经存在的处理情况是
//除非该key对应的value为null,否则一律不做任何处理
//Hashtable中则是会直接更新key对应的value
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
//集合修改次数,没操作一次+1
++modCount;
//HashMap容量大小大于临界值,则进行resize()扩容
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
### 终曲:为什么HashMap底层源码用这么多位运算?
**关于位运算的使用,文中在介绍第三步曲时,也提到了HashMap计算数组下标使用%取模和位运算的问题,使用于位运算的奥妙之处在直接从内存读取数据进行计算,不需要转成十进制,如果使用%取模需要先转成十进制,有性能开销,效率比较低**
**HashMap底层除了文中提到的`^`按位异或、`>>>`无符号右移、`&`按位与位运算,其实在HashMap的扩容机制`resize()`中,还用到了`<<`左移运算**
`oldCap << 1`
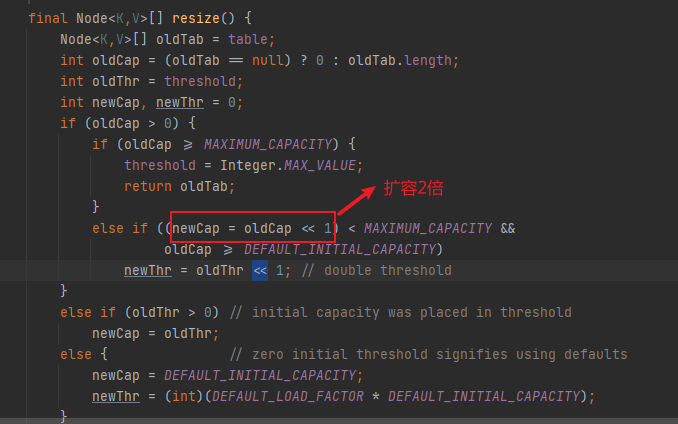
**这里`oldCap << 1`刚好是两倍,可以总结的说一个数与`n`进行左移运算,结果为这个数乘以2的n次方**
`oldCap << 1` 等值 `oldCap = oldCap * (2的n次方)`
**同理,一个数与`n`进行右移运算结果为这个数除以2的n次方**
`oldCap >> 1` 等值 `oldCap = oldCap / (2的n次方)`
\*\*
## HashMap链表转为红黑树
### 红黑树结构
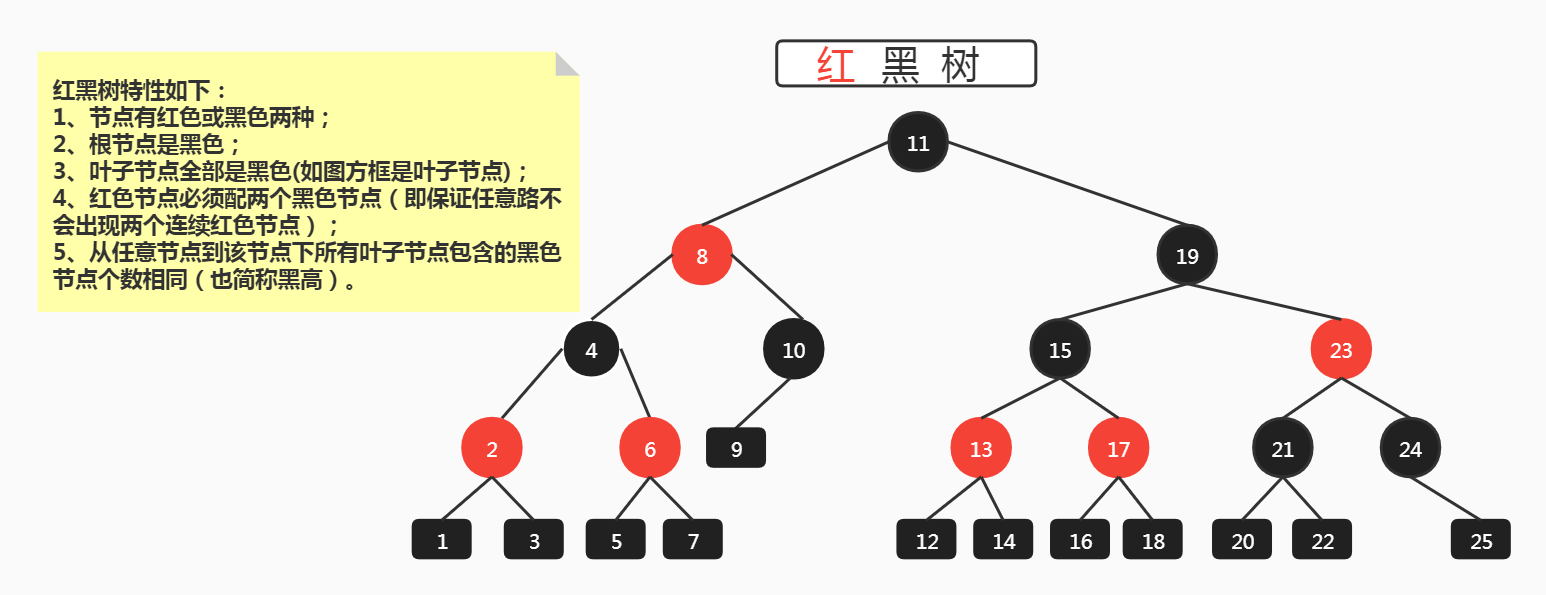
### 红黑树五大特性
>
> * **节点有红色或黑色两种;**
> * **根节点是黑色;**
> * **叶子节点全部是黑色(如图方框是叶子节点);**
> * **红色节点必须配两个黑色节点(即保证任意路不会出现两个连续红色节点);**
> * **从任意节点到该节点下所有叶子节点包含的黑色节点个数相同(也简称黑高)。**
>
>
>
### HashMap链表转为红黑树过程
**代码示例:**
public class Test {
public static void main(String[] args) {
HashMap<Object, Object> map = new HashMap<Object, Object>();
//下标为0
map.put(null, “Justin”);
map.put(16, “Justin”);
//下标为8
map.put(8, "Justin"); //链表第1个节点
map.put(24, "Justin"); //链表第2个节点
map.put(40, "Justin"); //链表第3个节点
map.put(56, "Justin"); //链表第4个节点
map.put(72, "Justin"); //链表第5个节点
map.put(88, "Justin"); //链表第6个节点
map.put(104, "Justin"); //链表第7个节点
map.put(120, "Justin"); //链表第8个节点
map.put("name", "Justin"); //在添加第9个节点时,链表会被转换为红黑树
}
}
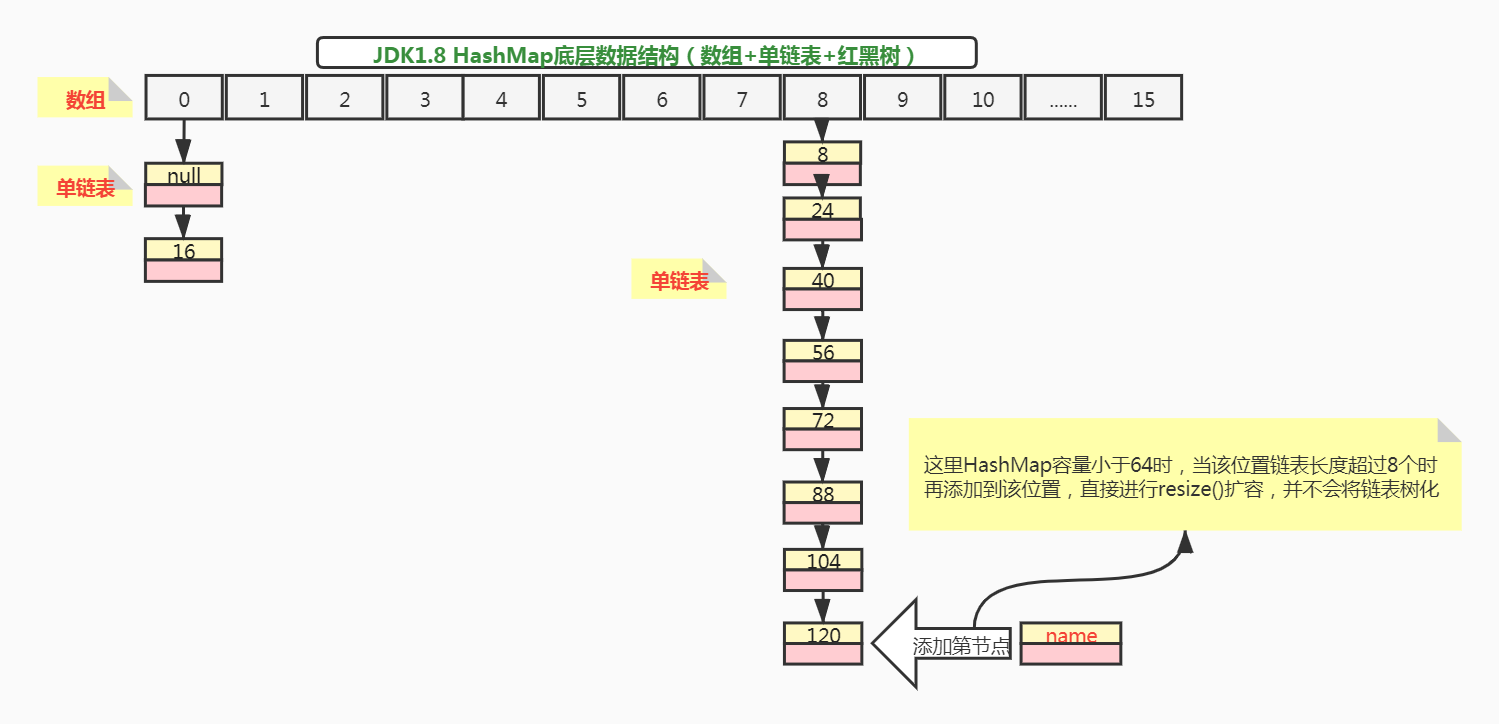
**上述代码添加元素完成后,大多数人认为,底层哈希表的数据结构如下:**
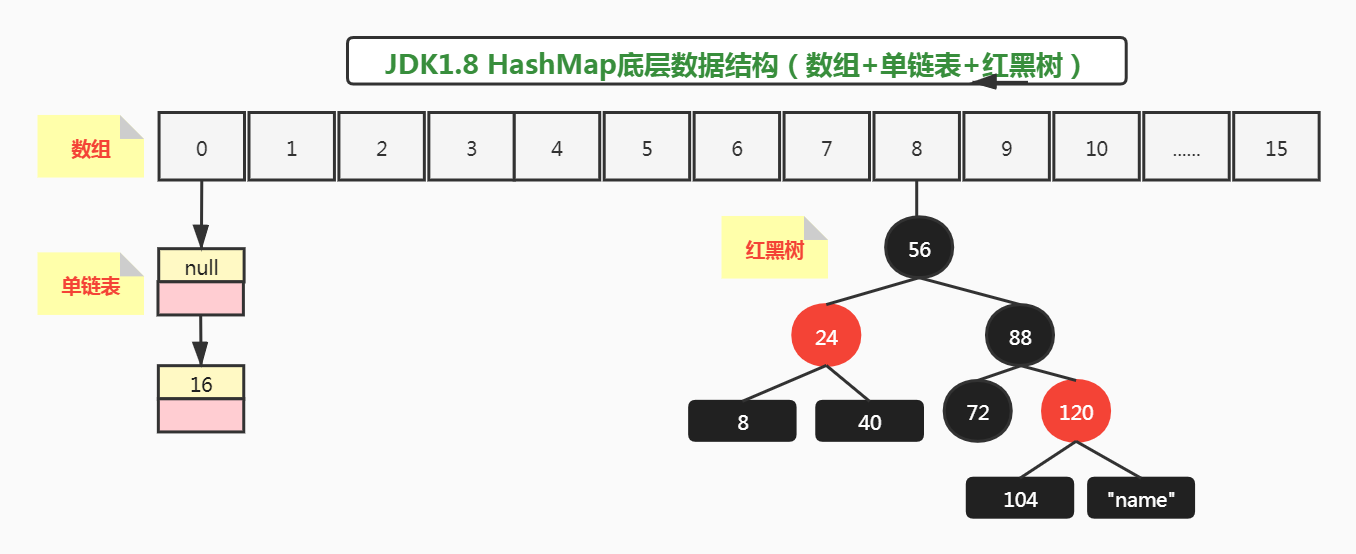
**看起来好像没啥毛病,但实际哈希表index=8的位置链表并不会转成红黑树,原因如下:**
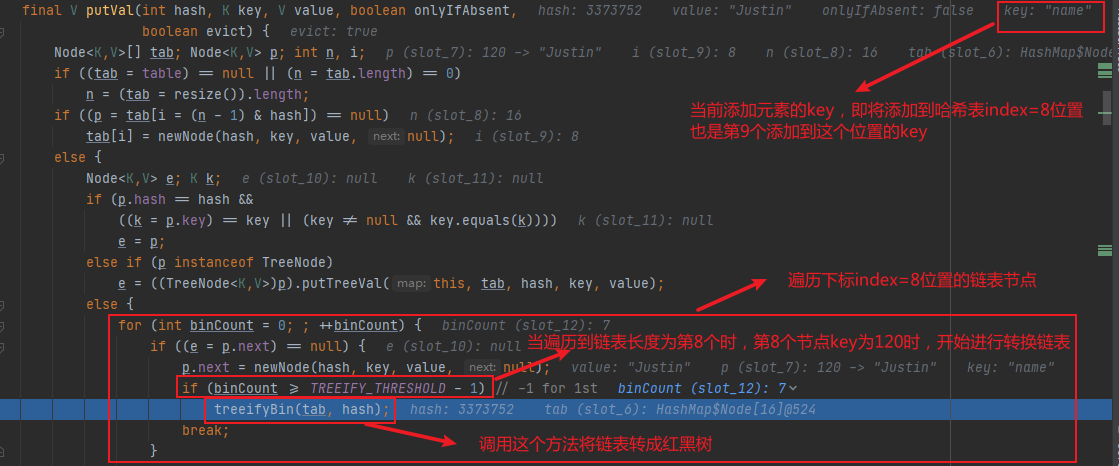
**再来看下`treeifyBin(tab,hash)`为什么不将链表转成红黑树?**
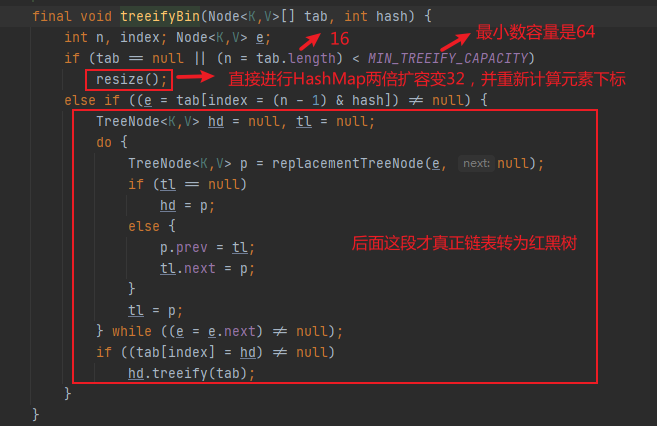
**其中`tab.length < MIN_TREEIFY_CAPACITY`表示只要哈希表数组大小于64容量的,不可能会发生链表树化的过程,所以示例代码中,在哈希表数组下标index=8位置,添加第9个key="name"元素时,此时哈希表大小只有16, `tab.length < MIN_TREEIFY_CAPACITY`即16 < 64 接进行`resize()`扩容并重新计算各个元素存储的位置了,并不会走后面的链表转红黑树的过程。**
**当添加key="name"节点时,会进行扩容,容量大小由16变为32,此时oldMap数据迁移到newMap后数据排列如何呢?**
**这里比较简单,没涉及到红黑树的拆分,而且链表长度都是大于1个的,直接由`(hash & oldCap)`重新计算位置:**
public class Test {
public static void main(String[] args) {
cal(null,0);
cal(16,0);
cal(8,8);
cal(24,8);
cal(40,8);
cal(56,8);
cal(88,8);
cal(72,8);
cal(104,8);
cal(120,8);
cal("name",8);
}
static void cal(Object key,int oldIndex) {
//将oldMap容量和节点hash值进行&按位与运算
if( (16 & hash(key)) == 0){//结果为0,节点放到newMap位置与在oldMap下标index位置一样
System.out.println("原key=" + key + ",迁移到newMap数组下标位置为:" + oldIndex);
}else{//结果不为0,节点放到newMap位置刚好等于oldMap下标index位置 + oldMap数组容量大小
System.out.println("原key=" + key + ",迁移到newMap数组下标位置为:" + (oldIndex + 16));
}
}
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
}
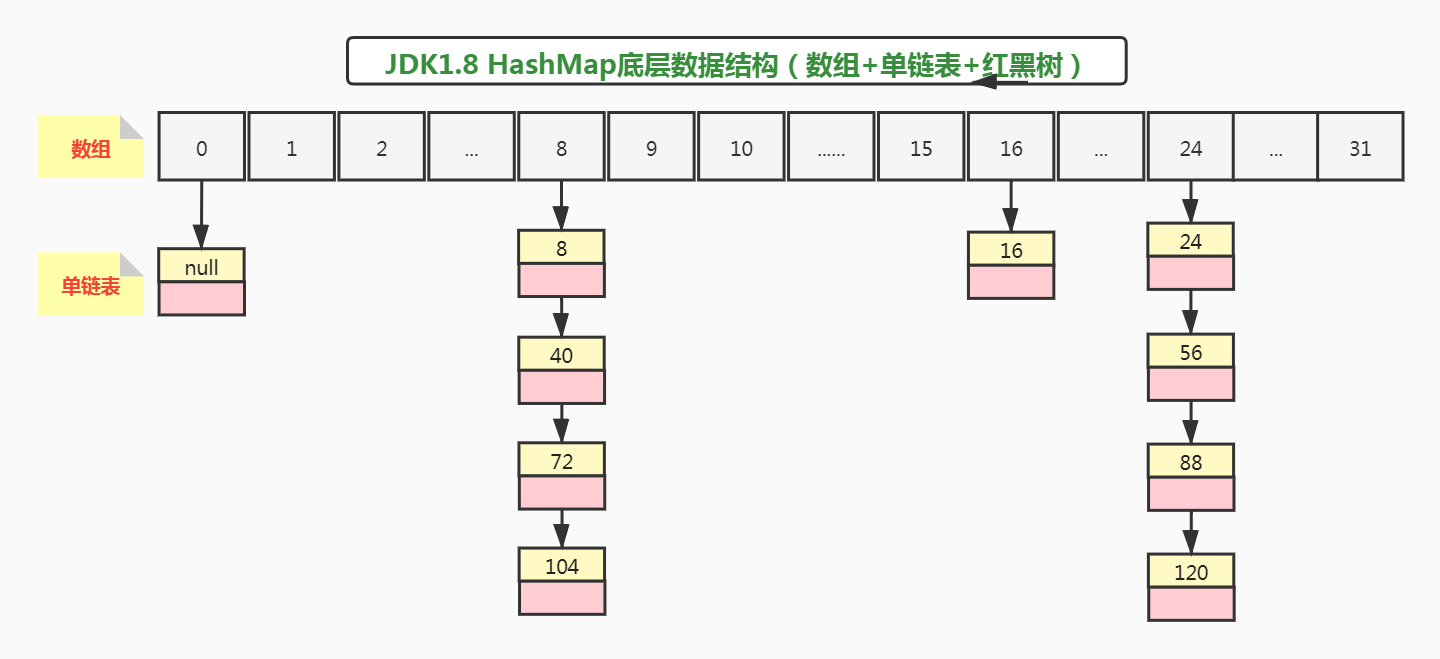
原来所有key,迁移到newMap后数组index下标位置如下:
原key=null,迁移到newMap数组下标位置为:0
原key=16,迁移到newMap数组下标位置为:16
原key=8,迁移到newMap数组下标位置为:8
原key=24,迁移到newMap数组下标位置为:24
原key=40,迁移到newMap数组下标位置为:8
原key=56,迁移到newMap数组下标位置为:24
原key=88,迁移到newMap数组下标位置为:24
原key=72,迁移到newMap数组下标位置为:8
原key=104,迁移到newMap数组下标位置为:8
原key=120,迁移到newMap数组下标位置为:24
原key=name,迁移到newMap数组下标位置为:24
**所以示例代码,添加元素后,正确的数据结构应该是这样的:**
**通过debug断点,也可以看到扩容后节点主要被分配到了8、16、24这个三个数组下标位置:**
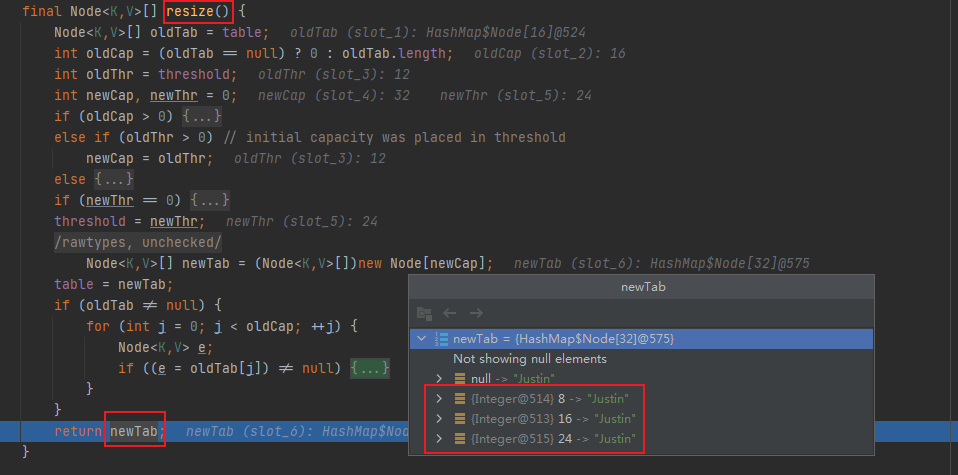
**不过一般情况下,HashMap扩容是发生在添加元素时,最后通过`++size > threshold`判断容量大于临界值时,才进行`resize()`扩容**
## HashMap扩容机制
* **扩容情况1:第一次添加元素会进行扩容,默认初始化容量为16**
* **扩容情况2:哈希表容量小于64时,链表长度每次大于8,都会进行resize()扩容**
* **扩容情况3:HashMap容量大于临界值时**
**几种扩容情况的源码如下:**
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
//扩容情况1:第一次添加元素会进行扩容,默认初始化容量为16
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
//扩容情况2:见treeifyBin方法说明
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize(); //扩容情况3:HashMap容量大于临界值时
afterNodeInsertion(evict);
return null;
}
**treeifyBin源码如下:**
final void treeifyBin(Node<K,V>[] tab, int hash) {
int n, index; Node<K,V> e;
//扩容情况2:哈希表容量小于64时,链表长度每次大于8,都会进行resize()扩容
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
resize();
else if ((e = tab[index = (n - 1) & hash]) != null) {
//链表树化的过程...
}
}
**再来看HashMap的`resize()`扩容关键源码:**
final Node<K,V>[] resize() {
...
if (oldCap > 0) {
...
//oldCap << 1即2倍扩容
else if ((newCap = oldCap << 1) < MAXIMUM\_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
…
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) {
//遍历oldMap按一定规则,迁移数据到newMap
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
//对于哈希表数组后链表只有一个节点的
//需要根据hash值重新计算新的下标位置
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
//对红黑树进行拆分
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
//对于哈希表数组后链表有多个节点的
//通过(hash & oldMap)算法以及lo、hi节点进行分组巧妙迁移
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
//这里是&按位与运算是oldMap迁移数据到newMap的奥妙之处
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
//按位与结果为0的,节点迁移到newMap下标与oldMap中下标一样
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
//按位与结果不为0的,节点迁移到newMap下标
//则刚好等于原oldMap中下标 + oldCap老容量
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
**可以看到其实HashMap扩容机制很简单,核心就是`newCap = oldCap << 1`即`2倍`扩容机制,难点在于oldMap旧数据迁移到newMap的过程,会涉及红黑树的拆分以及哈希表数组后链表有多个节点用的位运算(hash & oldMap)以及`lo`、`hi`两种节点,这个有点理解,特别是刚读源码的小伙伴,读不懂可以先放放,以后在慢慢深入理解。**
## HashMap获取元素
map.get(“name”);
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
**这里hash值的获取跟添加元素一模一样:**
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
### 如何自学黑客&网络安全
#### 黑客零基础入门学习路线&规划
**初级黑客**
**1、网络安全理论知识(2天)**
①了解行业相关背景,前景,确定发展方向。
②学习网络安全相关法律法规。
③网络安全运营的概念。
④等保简介、等保规定、流程和规范。(非常重要)
**2、渗透测试基础(一周)**
①渗透测试的流程、分类、标准
②信息收集技术:主动/被动信息搜集、Nmap工具、Google Hacking
③漏洞扫描、漏洞利用、原理,利用方法、工具(MSF)、绕过IDS和反病毒侦察
④主机攻防演练:MS17-010、MS08-067、MS10-046、MS12-20等
**3、操作系统基础(一周)**
①Windows系统常见功能和命令
②Kali Linux系统常见功能和命令
③操作系统安全(系统入侵排查/系统加固基础)
**4、计算机网络基础(一周)**
①计算机网络基础、协议和架构
②网络通信原理、OSI模型、数据转发流程
③常见协议解析(HTTP、TCP/IP、ARP等)
④网络攻击技术与网络安全防御技术
⑤Web漏洞原理与防御:主动/被动攻击、DDOS攻击、CVE漏洞复现
**5、数据库基础操作(2天)**
①数据库基础
②SQL语言基础
③数据库安全加固
**6、Web渗透(1周)**
①HTML、CSS和JavaScript简介
②OWASP Top10
③Web漏洞扫描工具
④Web渗透工具:Nmap、BurpSuite、SQLMap、其他(菜刀、漏扫等)
恭喜你,如果学到这里,你基本可以从事一份网络安全相关的工作,比如渗透测试、Web 渗透、安全服务、安全分析等岗位;如果等保模块学的好,还可以从事等保工程师。薪资区间6k-15k
到此为止,大概1个月的时间。你已经成为了一名“脚本小子”。那么你还想往下探索吗?
如果你想要入坑黑客&网络安全,笔者给大家准备了一份:282G全网最全的网络安全资料包评论区留言即可领取!
**7、脚本编程(初级/中级/高级)**
在网络安全领域。是否具备编程能力是“脚本小子”和真正黑客的本质区别。在实际的渗透测试过程中,面对复杂多变的网络环境,当常用工具不能满足实际需求的时候,往往需要对现有工具进行扩展,或者编写符合我们要求的工具、自动化脚本,这个时候就需要具备一定的编程能力。在分秒必争的CTF竞赛中,想要高效地使用自制的脚本工具来实现各种目的,更是需要拥有编程能力.
如果你零基础入门,笔者建议选择脚本语言Python/PHP/Go/Java中的一种,对常用库进行编程学习;搭建开发环境和选择IDE,PHP环境推荐Wamp和XAMPP, IDE强烈推荐Sublime;·Python编程学习,学习内容包含:语法、正则、文件、 网络、多线程等常用库,推荐《Python核心编程》,不要看完;·用Python编写漏洞的exp,然后写一个简单的网络爬虫;·PHP基本语法学习并书写一个简单的博客系统;熟悉MVC架构,并试着学习一个PHP框架或者Python框架 (可选);·了解Bootstrap的布局或者CSS。
**8、超级黑客**
这部分内容对零基础的同学来说还比较遥远,就不展开细说了,附上学习路线。
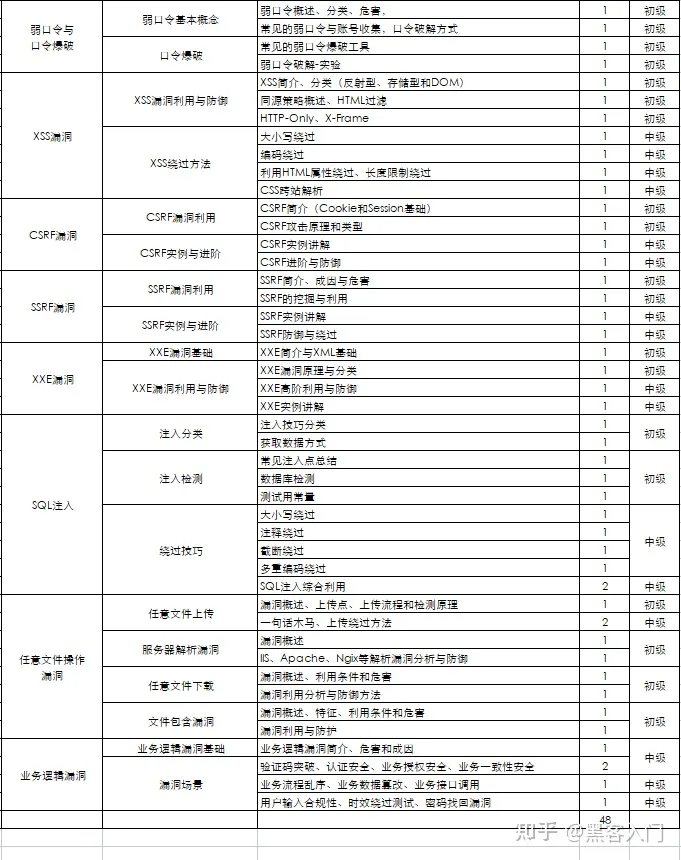
#### 网络安全工程师企业级学习路线

如图片过大被平台压缩导致看不清的话,评论区点赞和评论区留言获取吧。我都会回复的
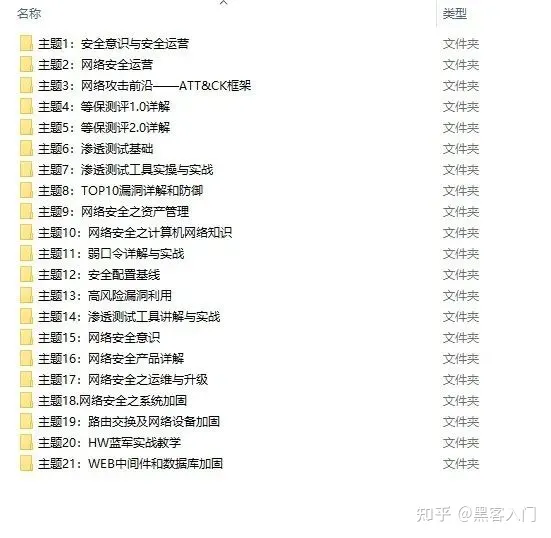
视频配套资料&国内外网安书籍、文档&工具
当然除了有配套的视频,同时也为大家整理了各种文档和书籍资料&工具,并且已经帮大家分好类了。

一些笔者自己买的、其他平台白嫖不到的视频教程。
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化资料的朋友,可以点击这里获取](https://bbs.youkuaiyun.com/forums/4f45ff00ff254613a03fab5e56a57acb)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









