




========
Kafka学习了数据库里面的设计,在里面设计了topic(主题),这个东西类似于关系型数据库的表。
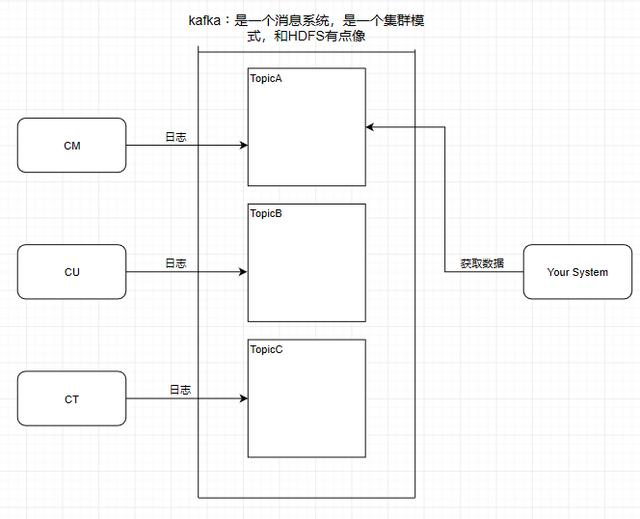
此时我需要获取中国移动的数据,那就直接监听TopicA即可。
Partition 分区
============
kafka还有一个概念叫Partition(分区),分区具体在服务器上面表现起初就是一个目录,一个主题下面有多个分区,这些分区会存储到不同的服务器上面,或者说,其实就是在不同的主机上建了不同的目录。这些分区主要的信息就存在了.log文件里面。跟数据库里面的分区差不多,是为了提高性能。
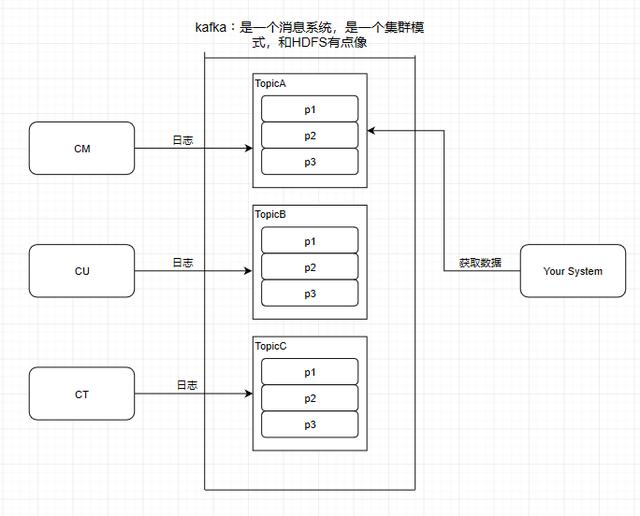
至于为什么提高了性能,很简单,多个分区多个线程,多个线程并行处理肯定会比单线程好得多。
Topic和partition像是HBASE里的table和region的概念,table只是一个逻辑上的概念,真正存储数据的是region,这些region会分布式地存储在各个服务器上面,对应于Kafka,也是一样,Topic也是逻辑概念,而partition就是分布式存储单元。这个设计是保证了海量数据处理的基础。我们可以对比一下,如果HDFS没有block的设计,一个100T的文件也只能单独放在一个服务器上面,那就直接占满整个服务器了,引入block后,大文件可以分散存储在不同的服务器上。
注意:
-
分区会有单点故障问题,所以我们会为每个分区设置副本数;
-
分区的编号是从0开始的。
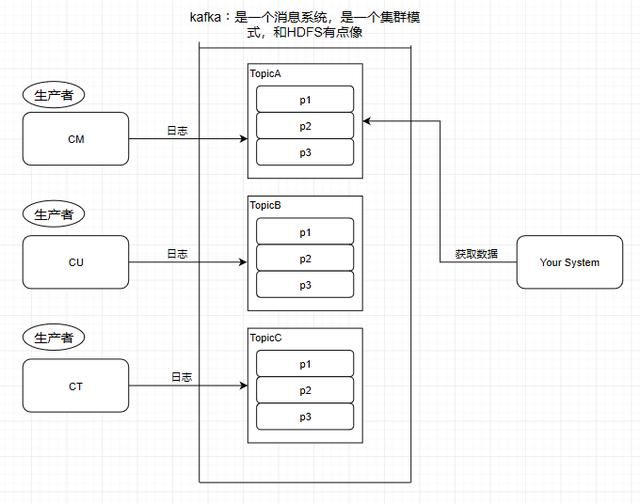
Producer - 生产者
==============
往消息系统里面发送数据的就是生产者。
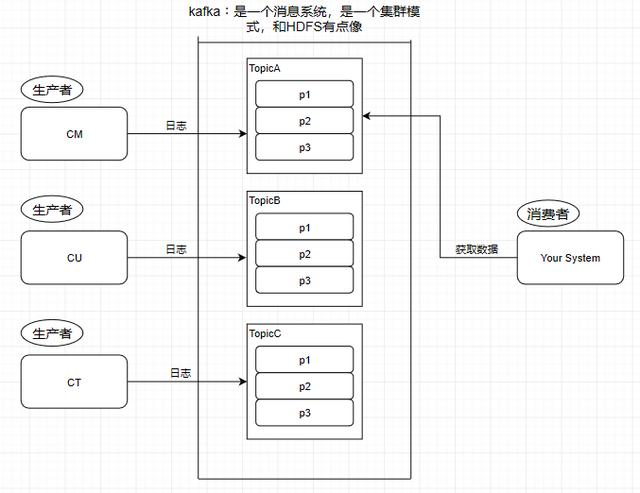
Consumer - 消费者
==============
从Kafka里读取数据的就是消费者。
Message - 消息
============
Kafka里面的我们处理的数据叫做消息。
Kafka的集群架构
==========
创建一个TopicA的主题,3个分区分别存储在不同的服务器,也就是brok
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 172万+
172万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









