




 本文详细分析了Java中CMSGC调优过程中遇到的9个问题,包括空间震荡、显式GC的处理、MetaSpace区OOM、过早晋升、OldGC频繁、单次OldGC耗时长等,并提供了相应的解决方案和优化策略。
本文详细分析了Java中CMSGC调优过程中遇到的9个问题,包括空间震荡、显式GC的处理、MetaSpace区OOM、过早晋升、OldGC频繁、单次OldGC耗时长等,并提供了相应的解决方案和优化策略。
-
CMS调优
-
OOM问题调优
-
Java中9种常见的CMS GC问题分析与解决
常见场景分析
==========
动态扩容引起的空间震荡
===============
现象
======
服务 刚刚启动时 GC 次数较多 ,最大空间剩余很多但是依然发生 GC,这种情况我们可以通过观察 GC 日志或者通过监控工具来观察堆的空间变化情况即可。GC Cause 一般为 Allocation Failure,且在 GC 日志中会观察到经历一次 GC ,堆内各个空间的大小会被调整,如下图所示:

原因分析
========
在 JVM 的参数中 -Xms 和 -Xmx 设置的不一致,在初始化时只会初始 -Xms 大小的空间存储信息,每当空间不够用时再向操作系统申请,这样的话必然要进行一次 GC。另外,如果空间剩余很多时也会进行缩容操作,JVM 通过 -XX:MinHeapFreeRatio 和 -XX:MaxHeapFreeRatio 来控制扩容和缩容的比例,调节这两个值也可以控制伸缩的时机。
解决方案
========
尽量 将成对出现的空间大小配置参数设置成固定的 ,如 -Xms 和 -Xmx , -XX:MaxNewSize 和 -XX:NewSize , -XX:MetaSpaceSize 和 -XX:MaxMetaSpaceSize 等。不过在不追求停顿时间的情况下震荡的空间也是有利的,可以动态地伸缩以节省空间,例如作为富客户端的 Java 应用。
显式GC的去和留
============
现象
======
手动调用 System.gc 方法会引发一次 STW 的 Full GC,对整个堆做收集,可以在 GC 日志中的 GC Cause 中确认。同时JVM提供 -XX:+DisableExplicitGC 参数可以避免这种 GC。那么有没有必要启用该参数呢?
去留分析
========
首先需要了解下 DirectByteBuffer ,它有着零拷贝等特点,被 Netty 等各种 NIO 框架使用,会使用到堆外内存。它的 Native Memory 的清理工作是通过 sun.misc.Cleaner 自动完成的,是一种基于虚引用PhantomReference的清理工具,比普通的 Finalizer 轻量些。而为 DirectByteBuffer 分配空间过程中会显式调用 System.gc ,希望通过 Full GC 来强迫已经无用的 DirectByteBuffer 对象释放掉它们关联的 Native Memory。
如果通过 -XX:+DisableExplicitGC 关闭显式GC,DirectByteBuffer分配空间中System.gc将失效,这时如果很长一段时间没有做过GC或者只做了Young GC,则不会触发Cleaner 的工作,Native Memory得不到及时释放,有可能发生内存泄漏。
所以一般建议保留显式GC,但需要规范使用,避免频繁GC带来的性能开销。可通过 -XX:+ExplicitGCInvokesConcurrent 和 -XX:+ExplicitGCInvokesConcurrentAndUnloadsClasses 参数来讲 System.gc 的触发类型从 Foreground 改为 Background,同时 Background 也会做 Reference Processing,这样的话就能大幅降低了 STW 开销,同时也不会发生 NIO Direct Memory OOM。
MetaSpace 区 OOM
===================
现象
======
JVM 在启动后或者某个时间点开始, MetaSpace 的已使用大小在持续增长,同时每次 GC 也无法释放,调大 MetaSpace 空间也无法彻底解决 。
原因分析
========
Java 7 之前字符串常量池被放到了 Perm 区,所有被 intern 的 String 都会被存在这里,由于 String.intern 是不受控的,所以 -XX:MaxPermSize 的值也不太好设置,经常会出现 java.lang.OutOfMemoryError: PermGen space 异常。但在 Java 7 之后常量池等字面量(Literal)、类静态变量(Class Static)、符号引用(Symbols Reference)等几项被移到 Heap 中,PermGen 也被移除,取而代之的是 MetaSpace。在最底层,JVM 通过 mmap 接口向操作系统申请内存映射,每次申请 2MB 空间,这里是虚拟内存映射,不是真的就消耗了内存的 2MB,只有之后在使用的时候才会真的消耗内存。申请的这些内存放到一个链表中 VirtualSpaceList,作为其中的一个 Node。
关键原因就是 ClassLoader 不停地在内存中 load 了新的 Class ,一般这种问题都发生在动态类加载等情况上。
解决方案
========
dump 快照之后通过 JProfiler 或 MAT 观察 Classes 的 Histogram(直方图)即可,或者直接通过命令即可定位, jcmd 打几次 Histogram 地图,看一下具体是哪个包下的 Class 增加较多就可以定位了。
jcmd GC.class_stats|awk ‘{print$13}’|sed ‘s/(.).(.)/\1/g’|sort |uniq -c|sort -nrk1
经常会出问题的几个点有 Orika 的 classMap、JSON 的 ASMSerializer、Groovy 动态加载类等,基本都集中在反射、Javasisit 字节码增强、CGLIB 动态代理、OSGi 自定义类加载器等的技术点上。
过早晋升
========
现象
======
-
分配速率接近于晋升速率 ,对象晋升年龄较小
-
Full GC 比较频繁 ,且经历过一次 GC 之后 Old 区的 变化比例非常大
原因分析及策略
===========
-
Young/Eden 区过小 :一般情况下 Old 的大小应当为活跃对象的 2~3 倍左右,考虑到浮动垃圾问题最好在 3 倍左右,剩下的都可以分给 Young 区
-
分配速率过大 :偶发较大 :通过内存分析工具找到问题代码,从业务逻辑上做一些优化一直较大 :当前的 Collector 已经不满足应用程序的期望了,这种情况要么增加应用程序的 机器,要么调整 GC 收集器类型或加大空间
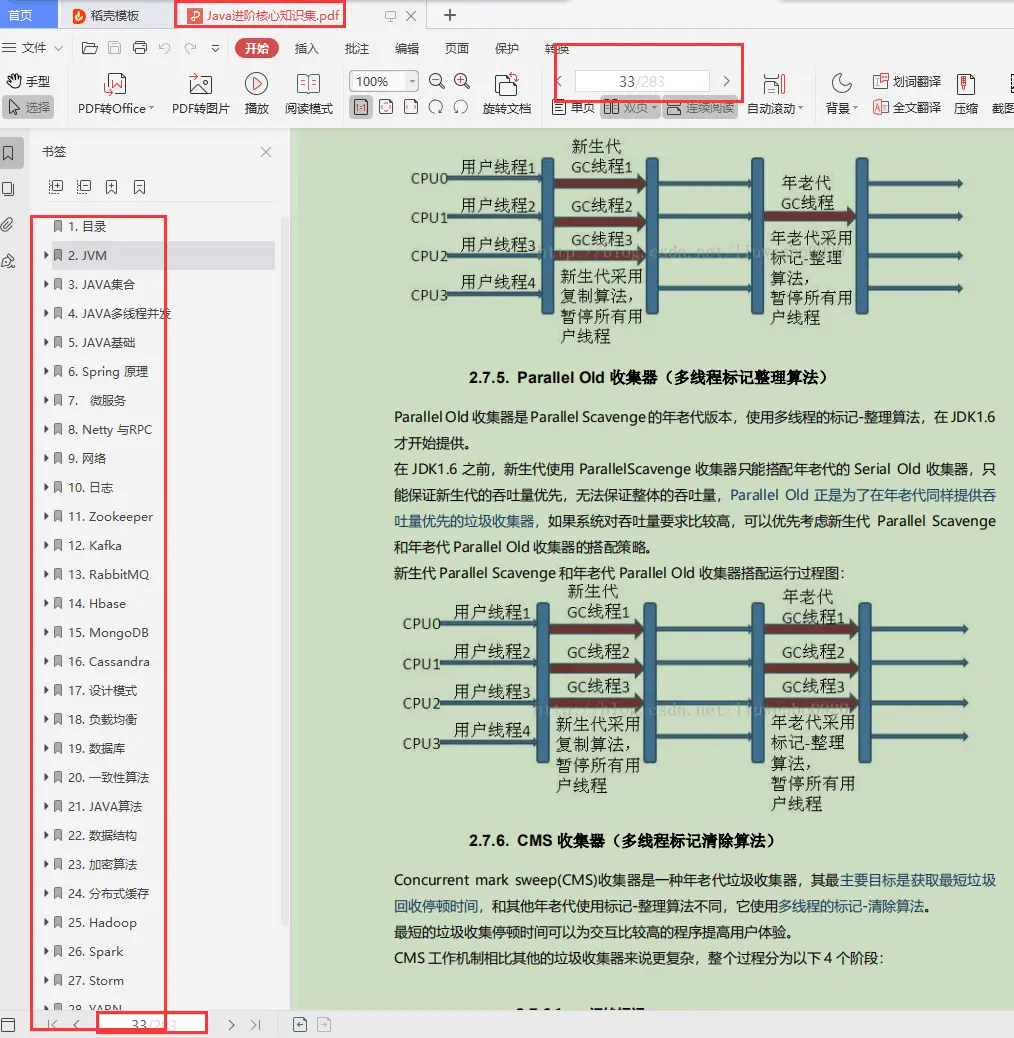
CMS Old GC频繁
================
现象
======
Old 区频繁地做 CMS GC,但是每次耗时不是特别长,整体最大 STW 也在可接受范围内,但由于 GC 太频繁导致吞吐下降比较多。
原因分析
========
基本都是一次 Young GC 完成后,负责处理 CMS GC 的一个后台线程 concurrentMarkSweepThread 会不断地轮询,使用 shouldConcurrentCollect() 方法做一次检测,判断是否达到了回收条件。如果达到条件(参考上文中CMS GC触发条件),使用 collect_in_background() 启动一次 Background 模式 GC。轮询的判断是使用 sleepBeforeNextCycle() 方法,间隔周期为 -XX:CMSWaitDuration 决定,默认为2s。
解决方案
========

-
Dump Diff:分别在 CMS GC 的发生前后分别 dump 一次,进行dump文件差异分析
-
Leak Suspects:内存泄露报告
-
Top Component分析:按照对象、类、类加载器、包等多个维度观察 Histogram,同时使用 outgoing 和 incoming 分析关联的对象,另外就是 Soft Reference 和 Weak Reference、Finalizer 等也要看一下
-
Unreachable分析:不可达对象分析
单次 CMS Old GC 耗时长
=====================
现象
======
CMS GC 单次 STW 最大超过 1000ms,不会频繁发生。但这种场景非常危险,某些场景下会引起“雪崩效应”,我们应该尽量避免出现。
原因分析
========
可能造成STW的情况如下:
-
Init Mark整个过程比较简单,从 GC Root 出发标记 Old 中的对象,处理完成后借助 BitMap 处理下 Young 区对 Old 区的引用,整个过程基本都比较快,很少会有较大的停顿。
-
Final MarkFinal Remark 的开始阶段与 Init Mark 处理的流程相同,但是后续多了 Card Table 遍历、Reference 实例的清理,并将其加入到 Reference 维护的 pend_list 中,如果要收集元数据信息,还要清理 SystemDictionary、CodeCache、SymbolTable、StringTable 等组件中不再使用的资源。
-
STW前等待应用线程到达安全点(较少发生)
由此可见,大部分问题都出在 Final Remark 过程,观察详细 GC 日志,找到出问题时 Final Remark 日志,分析下 Reference 处理和元数据处理 real 耗时是否正常,详细信息需要通过 -XX:+PrintReferenceGC 参数开启。 基本在日志里面就能定位到大概是哪个方向出了问题,耗时超过 10% 的就需要关注 。
一般来说最容易出问题的地方就是 Reference 中的 FinalReference 和元数据信息处理中的 scrub symbol table 两个阶段,想要找到具体问题代码就需要内存分析工具 MAT 或 JProfiler 了,注意要 dump 即将开始 CMS GC 地堆。在用 MAT 等工具前也可以先用命令行看下对象 Histogram,有可能直接就能定位问题。
-
对 FinalReference 的分析主要观察 java.lang.ref.Finalizer 对象的 dominator tree,找到泄漏的来源。经常会出现问题的几个点有 Socket 的 SocksSocketImpl 、Jersey 的 ClientRuntime 、MySQL 的 ConnectionImpl 等等。
-
scrub symbol table 表示清理元数据符号引用耗时,符号引用是 Java 代码被编译成字节码时,方法在 JVM 中的表现形式,生命周期一般与 Class 一致,当 _should_unload_classes 被设置为 true 时在 CMSCollector::refProcessingWork() 中与 Class Unload、String Table 一起被处理。
解决方案
========
更多:Java进阶核心知识集
包含:JVM,JAVA集合,网络,JAVA多线程并发,JAVA基础,Spring原理,微服务,Zookeeper,Kafka,RabbitMQ,Hbase,MongoDB,Cassandra,设计模式,负载均衡,数据库,一致性哈希,JAVA算法,数据结构,加密算法,分布式缓存等等
高效学习视频
oad、String Table 一起被处理。
解决方案
========
更多:Java进阶核心知识集
包含:JVM,JAVA集合,网络,JAVA多线程并发,JAVA基础,Spring原理,微服务,Zookeeper,Kafka,RabbitMQ,Hbase,MongoDB,Cassandra,设计模式,负载均衡,数据库,一致性哈希,JAVA算法,数据结构,加密算法,分布式缓存等等
[外链图片转存中…(img-wkEHsM7a-1714408522575)]


















 1003
1003

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









