 线程池与线程安全设计
线程池与线程安全设计





前言: 结合之前学过线程同步和互斥,我们可以进行一个线程池的设计。在写之前,我们要做如下准备
- 准备线程的封装
- 准备锁和条件变量的封装
- 引入日志,对线程进行封装
一、线程池
1.1 什么是线程池
线程池(Thread Pool)是并发编程中一种重要的设计模式,它预先创建一组线程并维护它们的生命周期,用于处理大量短期异步任务。就像一个工厂的工人团队,线程池中的线程随时待命,接到任务后立即执行,执行完毕后返回线程池等待下一个任务,避免了频繁创建和销毁线程的开销。
线程池本质上也是一种生产消费模型。
1.2 为什么需要线程池
在传统的多线程编程中,每当有新任务时就创建一个新线程,这种方式存在严重缺陷:
- 资源消耗巨大:频繁创建和销毁线程会消耗大量CPU时间和内存资源
- 系统稳定性差:过多线程可能导致系统资源耗尽,引发OutOfMemoryError
- 调度开销高:线程切换和上下文切换带来额外性能损耗
- 缺乏统一管理:难以监控线程状态、统计执行情况
线程池通过复用已有线程,有效解决了这些问题,成为现代高性能服务器和并发应用的标准配置。
线程池的应用场景:
- 需要大量的线程来完成任务,且完成任务的时间比较短。比如WEB服务器完成网页请求这样的任务,使用线程池技术是非常合适的。因为单个任务小,而任务数量巨大,你可以想象一个热门网站的点击次数。但对于长时间的任务,比如一个Telnet连接请求,线程池的优点就不明显了。因为Telnet会话时间比线程的创建时间大多了。
- 对性能要求苛刻的应用,比如要求服务器迅速响应客户请求。
- 接受突发性的大量请求,但不至于使服务器因此产生大量线程的应用。突发性大量客户请求,在没有线程池情况下,将产生大量线程,虽然理论上大部分操作系统线程数目最大值不是问题,短时间内产生大量线程可能使内存到达极限,出现错误.
线程池的种类:
a. 创建固定数量线程池,循环从任务队列中获取任务对象,获取到任务对象后,执行任务对象中的任务接口
b. 浮动线程池,其他同上,当工作队列已满且当前线程数小于最大线程数,创建新线程处理任务
线程池工作流程:
线程池的工作流程可以用以下状态机来描述:
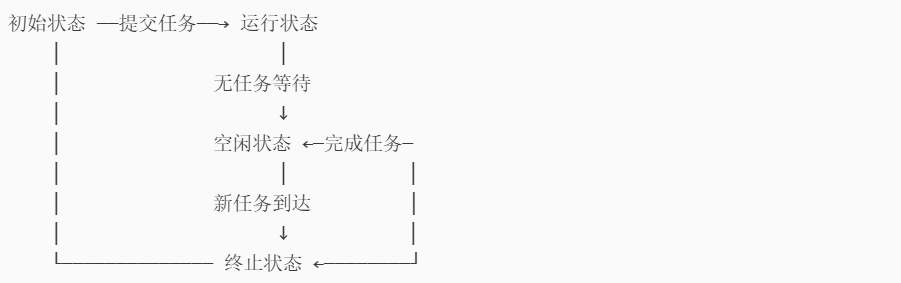
结合以下图片进行理解:
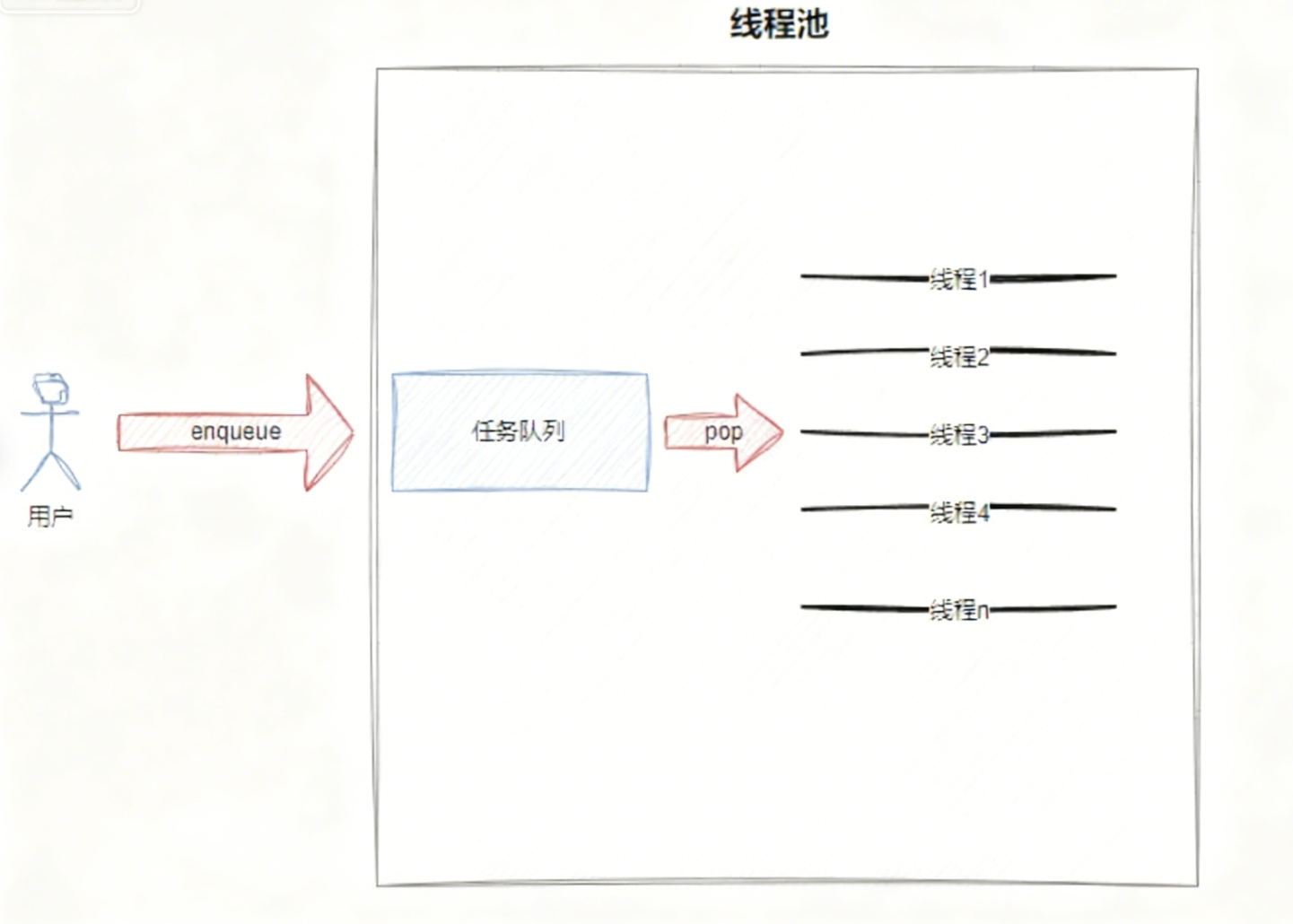
对于使用线程池的用户而言,他仅需要将要执行的任务放入线程池内部的任务队列,然后就可去做自己的事情了,当线程池中有空闲线程时,用户提交的任务就会被执行。
1.3 日志与策略模式
为了完成线程池,要先做好准备,首先,我们来完成日志模块的设计,那么什么是设计模式呢?
1.3.1 设计模式
设计模式(Design Pattern)是软件开发中针对常见问题的、经过验证的最佳解决方案模板。它不是具体的代码,而是解决某一类设计问题的通用思路和结构。
1.3.2 日志认识
计算机中的日志,是记录系统与软件运行过程中所发生事件的文件。其核心作用是监控运行状态、记录异常信息,帮助工作人员快速定位问题,同时为程序员修复问题提供支持。日志是系统维护、故障排查以及安全管理中不可或缺的重要工具。
日志格式以下几个指标是必须得有的
- 时间戳
- 日志等级
- 日志内容
以下几个指标是可选的
- 文件名行号
- 进程,线程相关id信息等
虽然日志领域已有现成的成熟解决方案(比如 spdlog、glog、Boost.Log、Log4cxx 等),但我们仍然选择采用自定义日志的实现方式。
我们采用设计模式-策略模式来进行日志的设计,我们想要的日志格式如下:

[高可读性时间] [日志等级] [进程PID] [日志所在文件名] [行号] - 消息内容(支持可变参数传入,灵活拼接日志详情)
1.4 日志设计实现
1.4.1 核心思想
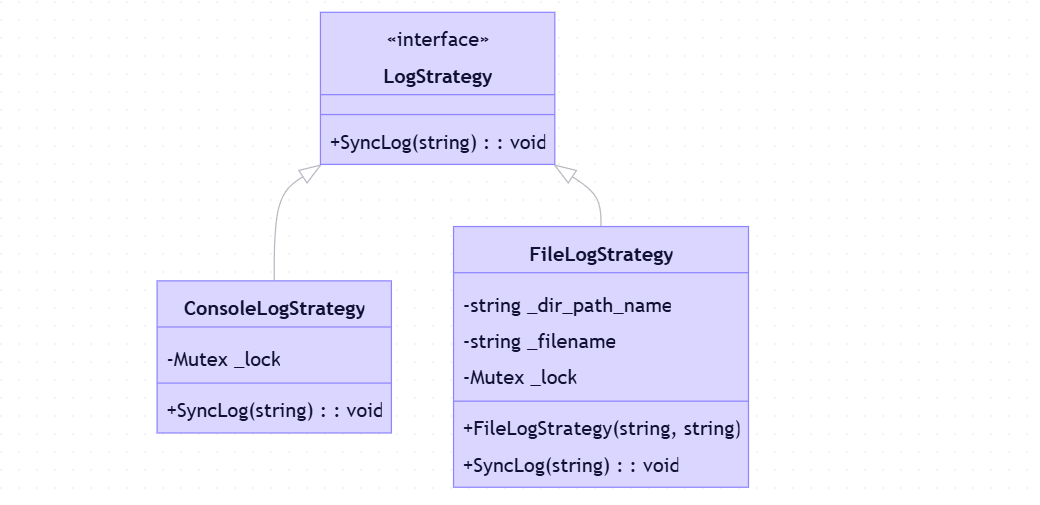
1.4.1.1 策略模式实现日志输出方式的解耦
- 通过
LogStrategy抽象基类定义日志输出接口- 具体策略类(
ConsoleLogStrategy/FileLogStrategy)实现不同输出方式Logger类持有策略对象,运行时可动态切换输出方式
1.4.1.2 RAII原则保证日志完整性
LogMessage类在构造时初始化日志前缀- 重载
operator<<实现流式日志内容追加
1.4.1.3 线程安全设计
- 每个策略类内部使用互斥锁(
Mutex)保护共享资源LockGuard(RAII风格锁管理)确保异常安全
1.4.2 实现逻辑
1.4.2.1 日志策略体系
1.4.2.2 日志构建流程
- 通过宏
LOG(level)创建LogMessage临时对象
- 自动捕获文件名(
__FILE__)和行号(__LINE__)- 初始化日志前缀:
[时间][级别][PID][文件][行号] -- 通过
operator<<链式追加日志内容- 临时对象生命周期结束时(语句结束)
- 调用析构函数
- 通过当前策略输出完整日志
日志构建时,通过EnableConsoleLogStrategy() 以及 EnableFileLogStrategy()采用不同的输出策略,通过对 << 进行重载实现流式输入,临时对象LogMessage析构时自动进行输出,代码如下:
#pragma once
#include <iostream>
#include <string>
#include <fstream>
#include <memory>
#include <ctime>
#include <sstream>
#include <filesystem> // C++17, 需要⾼版本编译器和-std=c++17
#include <unistd.h>
#include <time.h>
#include "Mutex.hpp"
enum class LogLevel
{
DEBUG,
INFO,
WARNING,
ERROR,
FATAL
};
std::string LogLevelToString(LogLevel level)
{
switch (level)
{
case LogLevel::DEBUG:
return "DEBUG";
case LogLevel::INFO:
return "INFO";
case LogLevel::WARNING:
return "WARNING";
case LogLevel::ERROR:
return "ERROR";
case LogLevel::FATAL:
return "FATAL";
default:
return "UNKNOWN";
}
}
// 20xx-09-22 12:22:34
std::string GetCurrentTime()
{
time_t current = time(nullptr); // 获取时间戳
struct tm current_tm;
localtime_r(¤t, ¤t_tm);
char timebuffer[64];
snprintf(timebuffer, sizeof(timebuffer), "%4d-%02d-%02d %02d:%02d:%02d", current_tm.tm_year + 1900, current_tm.tm_mon + 1,
current_tm.tm_mday, current_tm.tm_hour, current_tm.tm_min, current_tm.tm_sec);
return timebuffer;
}
// 基类方法
class LogStrategy
{
public:
virtual ~LogStrategy() = default;
virtual void SyncLog(const std::string &logmessage) = 0;
};
// 显示器
class ConsoleLogStrategy : public LogStrategy
{
public:
~ConsoleLogStrategy() {}
void SyncLog(const std::string &logmessage) override
{
LockGuard lockguard(&_lock);
std::cout << logmessage << std::endl;
}
private:
Mutex _lock;
};
// 默认路径和⽇志名称
const std::string defaultpath = "./log/";
const std::string defaultname = "log.txt";
// 文件
class FileLogStrategy : public LogStrategy
{
public:
~FileLogStrategy() {}
FileLogStrategy(const std::string &dir = defaultpath, const std::string &name = defaultname)
: _dir_path_name(dir), _filename(name)
{
LockGuard lockguard(&_lock);
if (std::filesystem::exists(_dir_path_name))
{
return;
}
try
{
std::filesystem::create_directories(_dir_path_name);
}
catch (const std::filesystem::filesystem_error &e)
{
std::cerr << e.what() << "\r\n";
}
}
void SyncLog(const std::string &logmessage) override
{
{
LockGuard lockguard(&_lock);
std::string target = _dir_path_name + _filename;
std::ofstream out(target.c_str(), std::ios::app);
if (!out.is_open())
{
return;
}
out << logmessage << "\n";
out.close();
}
}
private:
std::string _dir_path_name;
std::string _filename;
Mutex _lock;
};
// 网络
//////////////////////////////////////////////////////////////////////////////////
class Logger
{
public:
Logger()
{
}
void EnableConsoleLogStrategy()
{
_strategy = std::make_unique<ConsoleLogStrategy>();
}
void EnableFileLogStrategy()
{
_strategy = std::make_unique<FileLogStrategy>();
}
// 形成一条完整日志的方式
class LogMessage
{
public:
LogMessage(LogLevel level, std::string filename, int line, Logger &logger)
: _curr_time(GetCurrentTime()),
_level(level),
_pid(getpid()),
_filename(filename),
_line(line),
_logger(logger)
{
std::stringstream ss;
ss << "[" << _curr_time << "] "
<< "[" << LogLevelToString(_level) << "] "
<< "[" << _pid << "] "
<< "[" << _filename << "] "
<< "[" << _line << "]"
<< " - ";
_loginfo = ss.str();
}
template <typename T>
LogMessage &operator<<(const T &info)
{
std::stringstream ss;
ss << info;
_loginfo += ss.str();
return *this;
}
~LogMessage() // 利用临时对象LogMessage做刷新
{
if (_logger._strategy)
{
_logger._strategy->SyncLog(_loginfo);
}
}
private:
std::string _curr_time;
LogLevel _level;
pid_t _pid;
std::string _filename;
int _line;
std::string _loginfo; // ⼀条合并完成的,完整的⽇志信息
Logger &_logger; // 提供具体刷新策略
};
LogMessage operator()(LogLevel level, std::string filename, int line)
{
return LogMessage(level, filename, line, *this);
}
~Logger() {}
private:
std::unique_ptr<LogStrategy> _strategy;
};
Logger logger;
#define LOG(level) logger(level, __FILE__, __LINE__)
#define EnableConsoleLogStrategy() logger.EnableConsoleLogStrategy()
#define EnableFileLogStrategy() logger.EnableFileLogStrategy()
1.5 线程池设计实现
在此设计线程池,我们首先考虑线程安全的单例模式,那么什么是单例模式呢?
1.5.1 单例模式的特点
某些类, 只应该具有⼀个对象(实例), 就称之为单例。
在很多服务器开发场景中, 经常需要让服务器加载很多的数据 (上百G) 到内存中. 此时往往要用⼀个单例的类来管理这些数据。
1.5.2 单例模式的实现方式
单例模式的实现方式分为饿汉实现方式和懒汉实现方式
我们以洗碗的例子来理解一下
- 吃完饭, 立刻洗碗, 这种就是饿汉方式. 因为下⼀顿吃的时候可以立刻拿着碗就能吃饭.
- 吃完饭, 先把碗放下, 然后下⼀顿饭用到这个碗了再洗碗, 就是懒汉方式
懒汉方式最核心的思想是 "延时加载". 从而能够优化服务器的启动速度.
1.5.2.1 饿汉方式实现单例模式
template <typename T>
class Singleton {
private: // 静态数据成员应设为私有,避免外部直接访问
static T data;
public:
static T* GetInstance() {
return &data;
}
};
// 必须显式初始化静态数据成员(类外定义),否则会报链接错误
template <typename T>
T Singleton<T>::data;
只要通过 Singleton 这个包装类来使用 T 对象, 则一个进程中只有一个 T 对象的实例.
1.5.2.2 懒汉方式实现单例模式
template <typename T>
class Singleton {
private:
static T* inst;
public:
static T* GetInstance() {
if (inst == nullptr) {
inst = new T();
}
return inst;
}
};
// 类外初始化静态成员变量
template <typename T>
T* Singleton<T>::inst = nullptr;
上述代码存在一个严重的问题, 线程不安全.第一次调用GetInstance 的时候, 如果两个线程同时调用, 可能会创建出两份 T 对象的实例. 但是后续再次调用, 就没有问题了.
因此我们需要考虑线程安全方案实现单例:
可通过加锁(std::mutex)或使用 C++11 局部静态变量(Magic Static)实现。
加锁(std::mutex):
#include <mutex>
// 懒汉模式,线程安全版本
template <typename T>
class Singleton {
private:
// volatile 关键字防止编译器优化,确保每次都从内存读取最新值
static volatile T* inst;
// 互斥锁,保证多线程环境下实例创建的唯一性
static std::mutex lock;
// 将构造函数、拷贝构造函数和赋值运算符设为私有,防止外部创建实例
Singleton() {}
Singleton(const Singleton&) = delete;
Singleton& operator=(const Singleton&) = delete;
public:
// 获取单例实例的静态方法
static T* GetInstance() {
// 双重检查锁定(Double-Checked Locking)
// 第一次检查,避免每次调用都加锁,提高性能
if (inst == nullptr) {
// 加锁,保证临界区代码的原子性
lock.lock();
// 第二次检查,防止在等待锁的过程中实例已被创建
if (inst == nullptr) {
// 使用 new 创建实例,注意:此处未处理内存释放问题
inst = new T();
}
// 解锁
lock.unlock();
}
return const_cast<T*>(inst);
}
};
// 类外初始化静态成员变量
template <typename T>
volatile T* Singleton<T>::inst = nullptr;
template <typename T>
std::mutex Singleton<T>::lock;
注意事项:
- 加锁解锁的位置
- 双重 if 判定, 避免不必要的锁竞争
- volatile关键字防止过度优化
C++11 局部静态变量(Magic Static):
template <typename T>
class Singleton {
private:
// 私有化构造函数、拷贝构造和赋值运算符,防止外部创建实例
Singleton() {}
Singleton(const Singleton&) = delete;
Singleton& operator=(const Singleton&) = delete;
public:
// 使用局部静态变量实现线程安全的单例
static T* GetInstance() {
static T instance; // C++11 后局部静态变量初始化线程安全
return &instance;
}
};
1.5.3 单例式线程池
做好前面的准备后,就可以开始着手进程池的实现了。
首先,我们来看一下整体架构
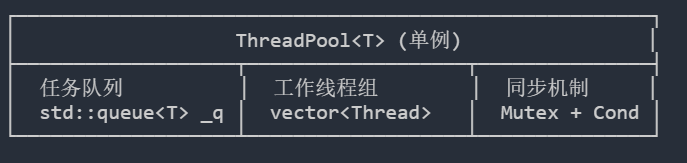
其中核心实现思想是先以懒汉模式创建一个单例线程池,代码如下
static ThreadPool<T>* GetInstance() {
if(!_instance) {
LockGuard lock(&_singleton_lock);
if (!_instance) {
_instance = new ThreadPool<T>();
_instance->Start(); // 初始化后立即启动
}
}
return _instance;
}
- 双重检查锁定:确保线程安全的单例创建
- 懒加载:首次使用时才创建线程池
- 自动启动:获取实例时自动初始化并启动线程池
然后引入生产者-消费者模型,
// 生产者:提交任务
void Enqueue(const T& in) {
LockGuard lockguard(&_lock);
_q.push(in);
if (_thread_wait_num > 0)
_cond.NotifyOne(); // 只唤醒一个等待线程
}
// 消费者:工作线程处理任务
void Routine(const std::string& name) {
while (true) {
T t;
{
LockGuard lockguard(&_lock);
while (QueueIsEmpty() && _isrunning) {
_thread_wait_num++; // 记录等待线程数
_cond.Wait(_lock); // 等待任务
_thread_wait_num--;
}
// 退出条件判断 & 任务获取
t = _q.front(); _q.pop();
}
t(); // 在临界区外执行任务
}
}
- 任务与执行解耦:任务提交后立即返回,执行在后台进行
- 临界区最小化:只在获取任务时加锁,执行任务时不占用锁
- 智能唤醒策略:根据等待线程数量决定唤醒一个还是全部
最后是退出机制,
退出逻辑设计
- 如果被唤醒 && 队列没有任务 = 让线程退出
- 如果被唤醒 && 队列有任务 = 线程不能立即退出 而应该让线程把任务处理完,再退出
- 线程本身没有休眠 我们应该让他把能处理的任务全处理完成,再退出
// 退出逻辑设计
// 1.如果被唤醒 && 队列没有任务 = 让线程退出
// 2.如果被唤醒 && 队列有任务 = 线程不能立即退出 而应该让线程把任务处理完,再退出
// 3.线程本身没有休眠 我们应该让他把能处理的任务全处理完成,再退出
void Stop()
{
if (!_isrunning)
return;
_isrunning = false;
if (_thread_wait_num > 0)
_cond.NotifyAll();
}
void Routine(const std::string &name)
{
// LOG(LogLevel::INFO) << name << " hello world";
while (true)
{
// 把任务从线程获取到线程私有 临界区 -> 私有栈
T t;
{
LockGuard lockguard(&_lock);
while (QueueIsEmpty() && _isrunning)
{
_thread_wait_num++;
_cond.Wait(_lock);
_thread_wait_num--;
}
// T t = _q.front(); // 处理任务不需要再临界区,只需把取任务保护好就行
if (!_isrunning && QueueIsEmpty()) // 退出情况设计
{
LOG(LogLevel::INFO) << "线程池退出 && 任务队列为空, " << name << "退出";
break;
}
t = _q.front();
_q.pop();
// t();
}
t();
}
}
完整实现代码如下所示
#pragma once
#include <iostream>
#include <memory>
#include <queue>
#include <vector>
#include "Thread.hpp"
#include "Mutex.hpp"
#include "Cond.hpp"
const static int threadnum_default = 3; // for debug
// 单例线程池
template <typename T>
class ThreadPool
{
private:
bool QueueIsEmpty()
{
return _q.empty();
}
void Routine(const std::string &name)
{
// LOG(LogLevel::INFO) << name << " hello world";
while (true)
{
// 把任务从线程获取到线程私有 临界区 -> 私有栈
T t;
{
LockGuard lockguard(&_lock);
while (QueueIsEmpty() && _isrunning)
{
_thread_wait_num++;
_cond.Wait(_lock);
_thread_wait_num--;
}
// T t = _q.front(); // 处理任务不需要再临界区,只需把取任务保护好就行
if (!_isrunning && QueueIsEmpty()) // 退出情况设计
{
LOG(LogLevel::INFO) << "线程池退出 && 任务队列为空, " << name << "退出";
break;
}
t = _q.front();
_q.pop();
// t();
}
t();
}
}
ThreadPool(int threadnum = threadnum_default) : _threadnum(threadnum), _thread_wait_num(0), _isrunning(false) // 对象先创建(存在),再初始化
{
for (int i = 0; i < threadnum; i++)
{
// 方法1
// auto f = std::bind(hello, this);
// 方法2
std::string name = "thread-" + std::to_string(i + 1);
_threads.emplace_back(Thread([this](const std::string &name)
{ this->Routine(name); }, name));
// Thread t([this]() {
// }, name);
// _threads.push_back(std::move(t));
}
LOG(LogLevel::INFO) << " threadpool cerate success";
}
// 复制拷⻉禁⽤
ThreadPool<T> &operator=(const ThreadPool<T> &) = delete;
ThreadPool(const ThreadPool<T> &) = delete;
public:
void Start()
{
if (_isrunning)
return;
_isrunning = true;
for (auto &t : _threads)
{
t.Start();
}
LOG(LogLevel::INFO) << " threadpool start success";
}
// 退出逻辑设计
// 1.如果被唤醒 && 队列没有任务 = 让线程退出
// 2.如果被唤醒 && 队列有任务 = 线程不能立即退出 而应该让线程把任务处理完,再退出
// 3.线程本身没有休眠 我们应该让他把能处理的任务全处理完成,再退出
void Stop()
{
// 这种做法太简单粗暴
// if (!_isrunning)
// return;
// _isrunning = false;
// for (auto &t : _threads)
// {
// t.Stop();
// }
// LOG(LogLevel::INFO) << " threadpool stop success";
if (!_isrunning)
return;
_isrunning = false;
if (_thread_wait_num > 0)
_cond.NotifyAll();
}
void Wait()
{
for (auto &t : _threads)
{
t.Join();
}
LOG(LogLevel::INFO) << " threadpool wait success";
}
void Enqueue(const T &in)
{
if (!_isrunning)
return;
{
LockGuard lockguard(&_lock);
_q.push(in);
if (_thread_wait_num > 0)
_cond.NotifyOne();
}
}
// 获取单例 // 让用户以类的方式访问构造单例,不需要自己构造
static ThreadPool<T> *GetInstance()
{
if(!_instance)
{
LockGuard LockGuard(&_singleton_lock);
if (!_instance)
{
LOG(LogLevel::DEBUG) << "线程池首次被使用,创建并初始化";
_instance = new ThreadPool<T>();
_instance->Start();
}
// else
// {
// LOG(LogLevel::DEBUG) << "线程池单例已经存在,直接获取";
// }
}
return _instance;
}
~ThreadPool()
{
LOG(LogLevel::INFO) << " threadpool destory success";
}
private:
// 任务队列
std::queue<T> _q; // 整体使用的临界资源
// 多个线程
std::vector<Thread> _threads;
int _threadnum;
int _thread_wait_num;
// 锁
Mutex _lock;
// 条件变量
Cond _cond;
bool _isrunning; // 防止线程池重复启动
// 单例中静态指针 // 懒汉模式设计
static ThreadPool<T> *_instance;
static Mutex _singleton_lock;
};
template <class T>
ThreadPool<T> *ThreadPool<T>::_instance = nullptr;
template <class T>
Mutex ThreadPool<T>::_singleton_lock;
二、线程安全问题
2.1 线程安全和重入问题
概念:
线程安全
线程安全指的是多个线程访问共享资源时,能够正确执行,不会相互干扰或破坏彼此的执行结果。通常情况下,多个线程并发执行仅包含局部变量的代码时,不会出现结果不一致的问题;但如果对全局变量或静态变量进行操作,且没有通过锁等机制进行保护,就容易引发线程安全问题。
重入与可重入函数
重入指的是同一个函数被不同的执行流调用时,前一个执行流尚未执行完毕,另一个执行流就再次进入该函数的情况。若一个函数在重入场景下,运行结果依然不会出现异常或不一致,则该函数被称为可重入函数;反之,则为不可重入函数。
现在我们能够理解重入其实就可以分为2种了,其一是多线程重入函数,其二是信号导致⼀个执行流重复进入函数。
可重入与线程安全的联系,本质上是一个函数是可重入的,那么它一定是线程安全的
- 如果一个函数是不可重入的,那么它不能被多个线程同时安全地调用,否则可能会引发线程安全问题。
- 进一步说,如果一个函数内部使用了全局变量或静态变量,那么这个函数通常既不是线程安全的,也不是可重入的。
可重入与线程安全的区别,本质上是可重入函数是线程安全函数的一种
- 线程安全不一定是可重入的,但可重入函数一定是线程安全的。
- 如果通过加锁保护临界资源访问,函数可以实现线程安全;但这种情况下,若该函数在重入时(前一次调用尚未释放锁)再次尝试获取锁,会导致死锁,因此它是不可重入的。
需要注意的是,如果不考虑信号导致一个执行流重复进入函数这种重入情况,那么从安全角度来看,线程安全和可重入这两个概念几乎可以看作是等价的,不需要加以区分。
但是,在更精确的语境下,二者的侧重点有所不同:
线程安全:这个术语侧重于描述多个线程并发访问共享资源时的安全性。它强调的是在多线程环境中,函数或代码段的行为是正确的,不会产生数据竞争或不一致的结果。它体现的是并发线程之间的互动特点。
可重入:这个术语侧重于描述一个函数本身的特性。它指的是一个函数在执行过程中,可以被安全地再次调用(无论是被同一个执行流还是不同的执行流),并且不会因为上次调用尚未完成而导致错误。它体现的是函数自身的健壮性和独立性。
2.2 常见锁概念
2.2.1 死锁
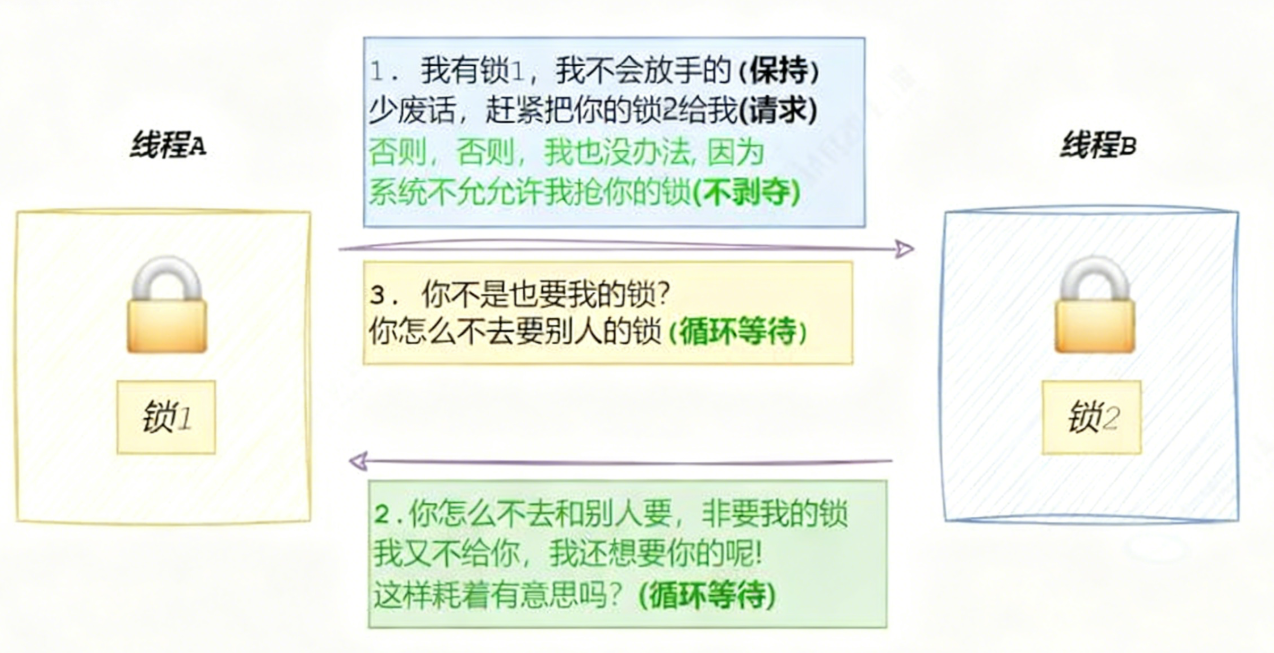
死锁是指两个或多个进程 / 线程因互相等待对方持有的资源,而陷入 "永久无法继续执行" 的状态。若无外力干预,这些进程会一直占用资源却不产生任何有用输出,导致系统服务停滞、资源耗尽,甚至崩溃。
如何来理解死锁呢,假设现在有2个线程,分别为线程A、线程B,以及有2把锁,分别为锁1、锁2,当访问某临界资源时,A、B线程都必须同时持有锁1、锁2,才能正常访问,
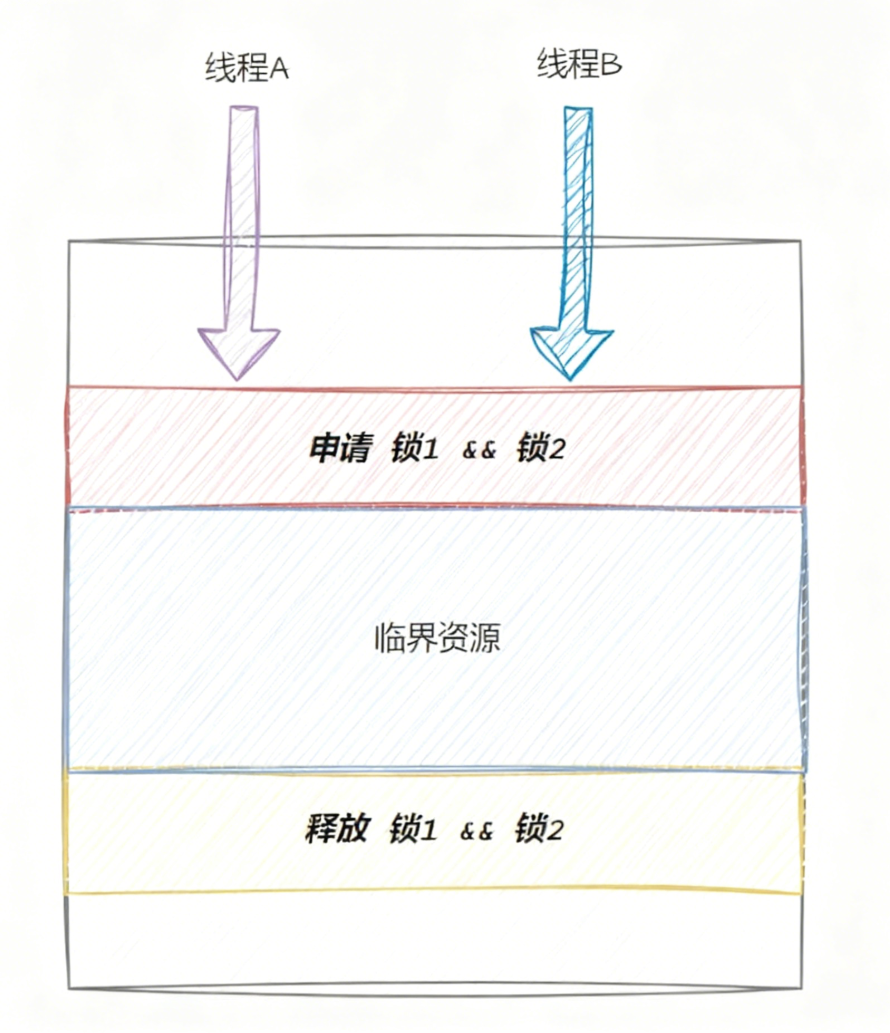
那么就可能会出现下面的问题,当线程A申请到锁1的时间段里,线程B可能就去申请锁2了,故A、B很难同时申请到2把锁,那么线程A、B就会互相去申请对方的锁,原因是申请一把锁是原子的,但是申请两把锁就不一定了,
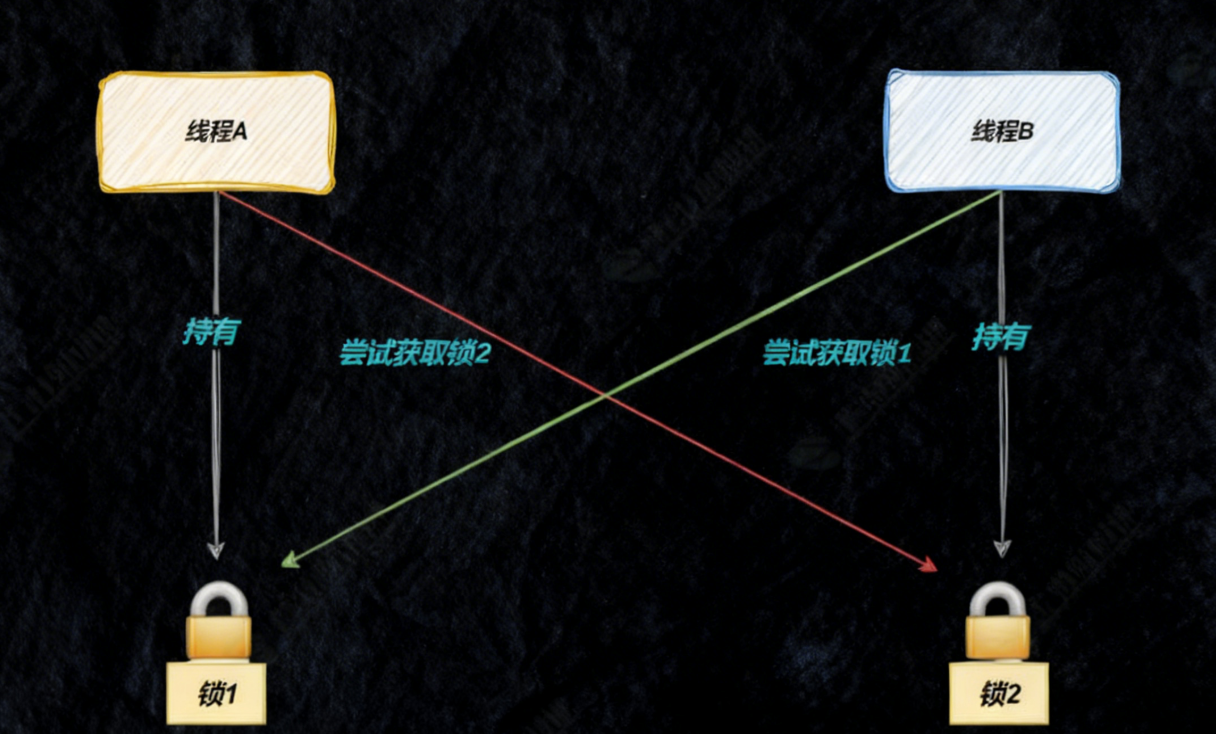
最后导致的结果是
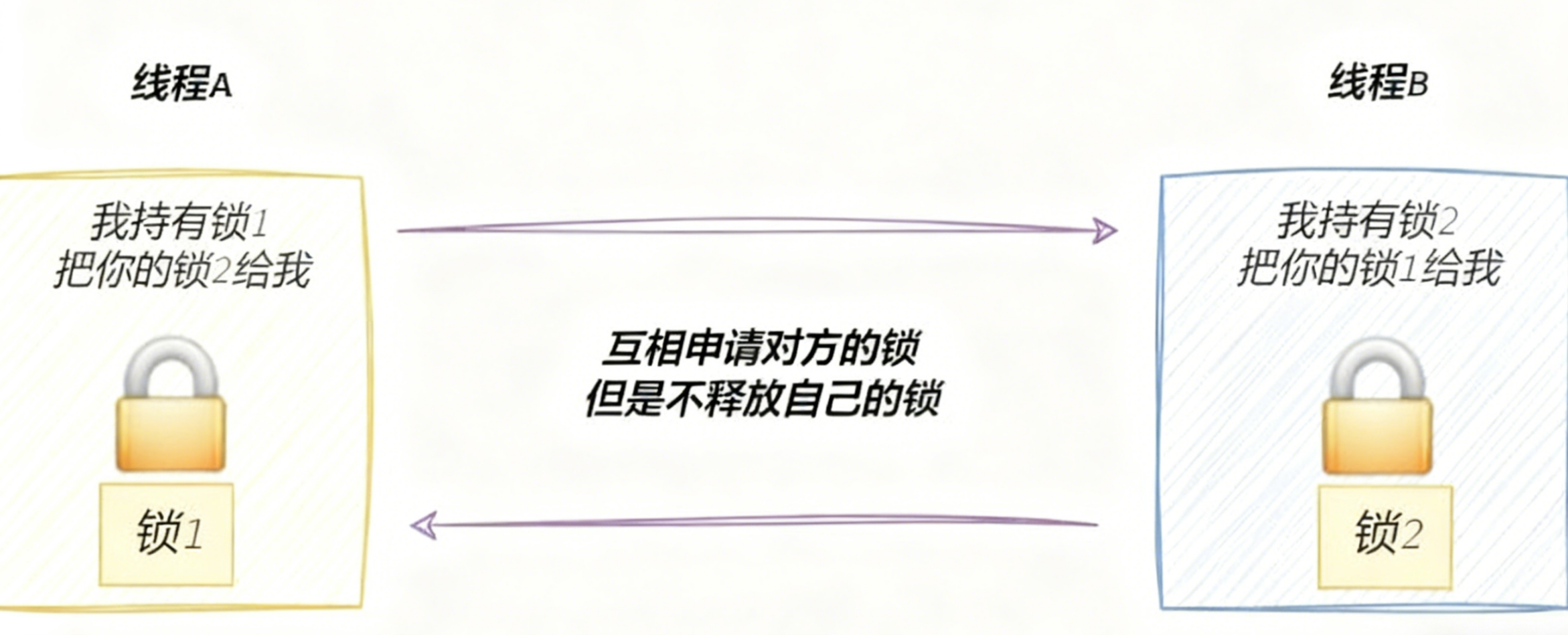
从而产生了死锁的问题。
下面是产生死锁的几个错误例子,
1. 互斥锁顺序不当
// 线程1
pthread_mutex_lock(&lockA);
pthread_mutex_lock(&lockB); // 死锁风险点
// ...操作
pthread_mutex_unlock(&lockB);
pthread_mutex_unlock(&lockA);
// 线程2
pthread_mutex_lock(&lockB);
pthread_mutex_lock(&lockA); // 死锁风险点
// ...操作
pthread_mutex_unlock(&lockA);
pthread_mutex_unlock(&lockB);
2.递归锁使用不当
// 同一线程重复获取非递归互斥锁
pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;
void unsafe_function() {
pthread_mutex_lock(&mutex);
// 递归调用时再次尝试获取锁
unsafe_function(); // 死锁!
pthread_mutex_unlock(&mutex);
}
3.文件锁死锁
// 进程A
fd1 = open("file1", O_RDWR);
flock(fd1, LOCK_EX); // 获取file1的排他锁
fd2 = open("file2", O_RDWR);
flock(fd2, LOCK_EX); // 如果进程B先锁了file2,这里会死锁
// 进程B(同时运行)
fd2 = open("file2", O_RDWR);
flock(fd2, LOCK_EX); // 获取file2的排他锁
fd1 = open("file1", O_RDWR);
flock(fd1, LOCK_EX); // 死锁!
4.信号处理函数中的锁
pthread_mutex_t log_mutex = PTHREAD_MUTEX_INITIALIZER;
void signal_handler(int sig) {
pthread_mutex_lock(&log_mutex); // 信号处理函数中获取锁
write_log("Signal received");
pthread_mutex_unlock(&log_mutex);
}
// 主线程中
pthread_mutex_lock(&log_mutex);
// 此时收到信号,信号处理函数尝试获取同一把锁
// 如果锁不是可重入的,将导致死锁
kill(getpid(), SIGUSR1);
pthread_mutex_unlock(&log_mutex);
2.2.2 死锁的四个必要条件
- 互斥条件:一个资源每次只能被一个执行流使用
本质就是要线程安全的访问临界资源
- 请求与保持条件:一个执行流因请求资源而阻塞时,对已获得的资源保持不放

- 不剥夺条件:一个执行流已获得的资源,在末使用完之前,不能强行剥夺
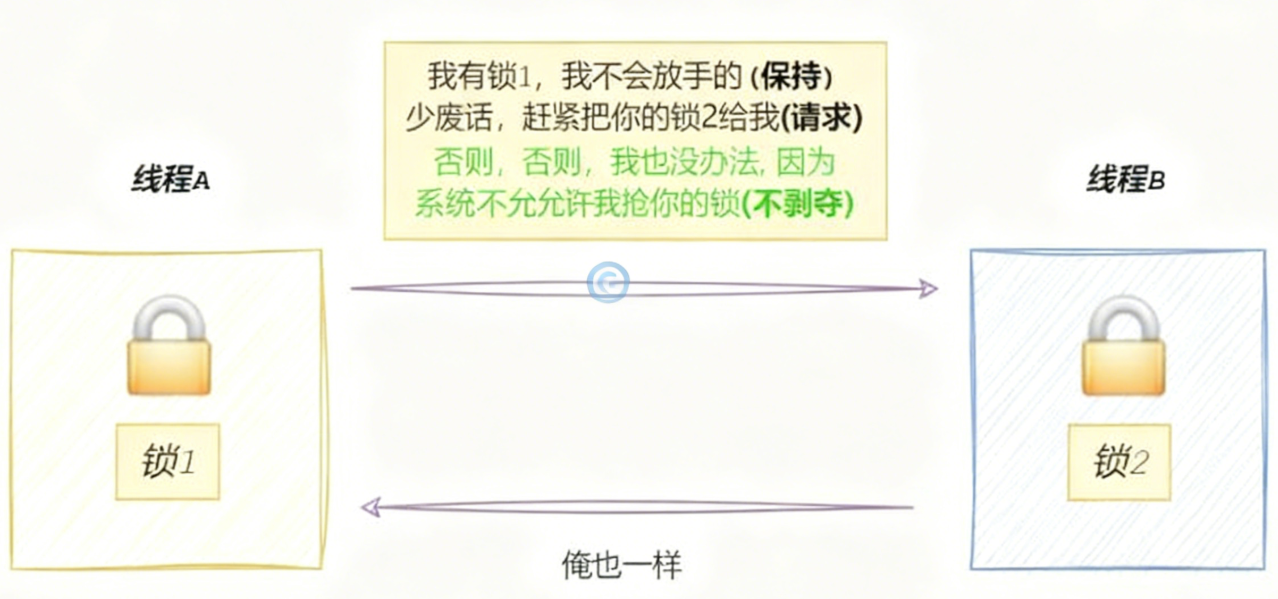
- 循环等待条件:若干执行流之间形成一种头尾相接的循环等待资源的关系
2.2.3 避免死锁
事实上,我们只需要把形成死锁的4个必要条件,随便破坏掉一个就可以了,比如破坏循环等待条件问题:资源一次性分配, 使用超时机制、加锁顺序一致
#include <iostream>
#include <mutex>
#include <thread>
#include <vector>
#include <unistd.h>
// 定义两个共享资源(整数变量)和两个互斥锁
int shared_resource1 = 0;
int shared_resource2 = 0;
std::mutex mtx1, mtx2;
// 一个函数,同时访问两个共享资源
void access_shared_resources()
{
std::unique_lock<std::mutex> lock1(mtx1, std::defer_lock);
std::unique_lock<std::mutex> lock2(mtx2, std::defer_lock);
// 使用 std::lock 同时锁定两个互斥锁,避免死锁
std::lock(lock1, lock2);
// 当前没有正确加锁,会导致数据竞争
int cnt = 10000;
while (cnt)
{
++shared_resource1;
++shared_resource2;
cnt--;
}
// 当离开 access_shared_resources 的作用域时,lock1 和 lock2 的析构函数会被自动调用
// 这会导致它们各自的互斥量被自动解锁
}
// 模拟多线程同时访问共享资源的场景
void simulate_concurrent_access()
{
std::vector<std::thread> threads;
// 创建多个线程来模拟并发访问
for (int i = 0; i < 10; ++i)
{
threads.emplace_back(access_shared_resources);
}
// 等待所有线程完成
for (auto &thread : threads)
{
thread.join();
}
// 输出共享资源的最终状态
std::cout << "Shared Resource 1: " << shared_resource1 << std::endl;
std::cout << "Shared Resource 2: " << shared_resource2 << std::endl;
}
int main()
{
simulate_concurrent_access();
return 0;
}
不使用锁就会出现严重的竞态条件(Race Condition),所以我们需要使用锁,而如果不调用std::lock(lock1, lock2),就会出现死锁的情况。
2.2.4 避免死锁算法
解决死锁问题的方法有多种,在此仅仅介绍锁排序算法、银行家算法
需要避免死锁?
│
├─ 能否预知资源需求? ──是──→ 银行家算法
│ │
│ 否
│ │
├─ 能否定义全局锁顺序? ──是──→ 锁排序/锁层次
│ │
│ 否
│ │
├─ 系统是否容忍偶尔死锁? ──是──→ 死锁检测与恢复
│ │
│ 否
│ │
└─ 能否重构代码避免多锁? ──是──→ 无锁设计/避免嵌套锁
│
否
│
└──→ 超时机制 + 回退策略
2.2.4.1 锁排序算法
核心思想:为系统中所有锁定义全局唯一顺序,强制线程按相同顺序获取锁,破坏循环等待条件。
基本锁排序:
// 全局锁顺序定义
enum LockOrder {
ORDER_DB = 1,
ORDER_CACHE = 2,
ORDER_LOG = 3
};
// 锁获取辅助函数
void acquire_locks(std::vector<std::pair<std::mutex*, int>> locks) {
// 按顺序排序
std::sort(locks.begin(), locks.end(),
[](const auto& a, const auto& b) {
return a.second < b.second;
});
// 按顺序获取锁
for (auto& [mutex, order] : locks) {
mutex->lock();
}
}
// 使用示例
void safe_operation() {
std::vector<std::pair<std::mutex*, int>> locks = {
{&cache_mutex, ORDER_CACHE},
{&db_mutex, ORDER_DB}
};
acquire_locks(locks);
// ... 操作 ...
// 按相反顺序释放锁
db_mutex.unlock();
cache_mutex.unlock();
}
C++17的std::scoped_lock:
#include <mutex>
#include <thread>
std::mutex m1, m2, m3;
void safe_transfer() {
// C++17: 自动按地址顺序锁定多个互斥锁,避免死锁
std::scoped_lock lock(m1, m2, m3);
// ... 执行需要所有锁的操作 ...
// 析构时自动按锁定的逆序解锁
}
// 对比传统方法(容易死锁)
void unsafe_transfer() {
m1.lock();
m2.lock();
m3.lock();
// ... 操作 ...
m3.unlock();
m2.unlock();
m1.unlock();
}
下面以列表形式给出优缺点
| 优点 | 缺点 |
|---|---|
| 实现简单,开销小 | 需要全局协调,难以在大型系统中维护 |
| 运行时性能高 | 可能导致不必要的阻塞(严格的顺序可能限制并发) |
| 适用于大多数应用场景 | 无法处理动态锁顺序需求 |
2.2.4.2 银行家算法
基本概念: 银行家算法是由Edsger Dijkstra于1965年开发的一种死锁避免算法,其名称源于它模拟了银行家在发放贷款时的谨慎决策过程:银行必须确保在发放贷款后,仍能满足所有客户的资金需求,避免银行破产。
| 策略 | 复杂度 | 适用场景 |
|---|---|---|
| 银行家算法 | O(n²m) | 资源需求可预测的系统 |
核心思想:在分配资源前,先检查此次分配是否会使系统保持在安全状态。如果不安全,则推迟分配。
安全状态的定义: 系统处于安全状态,当且仅当存在一个进程执行序列<P₁, P₂, ..., Pₙ>,使得每个进程Pᵢ都能获得其所需的最大资源并顺利完成。
银行家算法需要维护四个核心数据结构:
| 数据结构 | 说明 | 示例 |
|---|---|---|
| Available | 长度为m的向量,表示每种资源的可用数量 | Available = [3, 3, 2] 表示A类资源3个,B类3个,C类2个 |
| Max | n×m矩阵,表示每个进程对每种资源的最大需求 | Max[i][j] = 7 表示进程i最多需要7个j类资源 |
| Allocation | n×m矩阵,表示当前已分配给每个进程的资源 | Allocation[i][j] = 2 表示进程i已获得2个j类资源 |
| Need | n×m矩阵,表示每个进程仍需的资源 Need = Max - Allocation | Need[i][j] = 5 表示进程i还需要5个j类资源 |
算法原理:银行家算法包含两个核心部分:安全性检查算法和资源请求算法。
安全性检查算法
1. 初始化:
- 工作向量 Work = Available
- 完成向量 Finish[1..n] = false (所有进程未完成)
- 安全序列 SafeSequence = 空列表
2. 寻找可执行进程:
查找进程i,满足:
- Finish[i] = false
- Need[i] ≤ Work (对所有资源类型)
3. 处理找到的进程:
- Work = Work + Allocation[i] (假设进程i完成后释放资源)
- Finish[i] = true
- 将i加入SafeSequence
- 转到步骤2
4. 结束条件:
- 如果所有Finish[i] = true,则系统安全,SafeSequence是安全序列
- 否则,系统不安全
资源请求算法
1. 合法性检查:
- 如果Requestᵢ[j] > Need[i][j](对任意j)
- 错误:请求超过声明的最大需求
2. 资源可用性检查:
- 如果Requestᵢ[j] > Available[j](对任意j)
- 进程必须等待
3. 试探性分配:
- Available = Available - Requestᵢ
- Allocation[i] = Allocation[i] + Requestᵢ
- Need[i] = Need[i] - Requestᵢ
4. 安全性检查:
- 调用安全性检查算法
- 如果安全,保留分配
- 否则,撤销分配(回滚到步骤3前的状态)
下面是C++对银行家算法的实现
#include <iostream>
#include <vector>
#include <algorithm>
class BankersAlgorithm {
private:
int num_processes;
int num_resources;
std::vector<int> available; // 可用资源向量
std::vector<std::vector<int>> max; // 最大需求矩阵
std::vector<std::vector<int>> allocation; // 已分配资源矩阵
std::vector<std::vector<int>> need; // 需求矩阵
public:
BankersAlgorithm(int processes, int resources,
const std::vector<int>& avail,
const std::vector<std::vector<int>>& maximum)
: num_processes(processes), num_resources(resources),
available(avail), max(maximum) {
// 初始化分配矩阵(初始为0)
allocation = std::vector<std::vector<int>>(num_processes,
std::vector<int>(num_resources, 0));
// 计算需求矩阵: Need = Max - Allocation
need = max;
for (int i = 0; i < num_processes; ++i) {
for (int j = 0; j < num_resources; ++j) {
need[i][j] -= allocation[i][j];
}
}
}
// 检查系统是否处于安全状态
bool isSafeState() {
std::vector<int> work = available;
std::vector<bool> finish(num_processes, false);
std::vector<int> safe_sequence;
int count = 0;
while (count < num_processes) {
bool found = false;
for (int i = 0; i < num_processes; ++i) {
if (!finish[i]) {
// 检查进程i的资源需求是否小于等于可用资源
bool can_allocate = true;
for (int j = 0; j < num_resources; ++j) {
if (need[i][j] > work[j]) {
can_allocate = false;
break;
}
}
if (can_allocate) {
// 假设进程i完成,释放其资源
for (int j = 0; j < num_resources; ++j) {
work[j] += allocation[i][j];
}
finish[i] = true;
safe_sequence.push_back(i);
found = true;
count++;
}
}
}
if (!found) {
break; // 无法找到可执行的进程
}
}
// 打印结果
if (count == num_processes) {
std::cout << "系统处于安全状态。安全序列为: ";
for (size_t i = 0; i < safe_sequence.size(); ++i) {
std::cout << "P" << safe_sequence[i];
if (i < safe_sequence.size() - 1) {
std::cout << " -> ";
}
}
std::cout << std::endl;
return true;
} else {
std::cout << "系统处于不安全状态。" << std::endl;
return false;
}
}
// 处理资源请求
bool requestResources(int process_id, const std::vector<int>& request) {
// 1. 检查请求是否合法
for (int i = 0; i < num_resources; ++i) {
if (request[i] > need[process_id][i]) {
std::cerr << "错误: 进程 P" << process_id
<< " 请求的资源超过了其最大需求。" << std::endl;
return false;
}
}
// 2. 检查是否有足够资源
for (int i = 0; i < num_resources; ++i) {
if (request[i] > available[i]) {
std::cerr << "错误: 系统没有足够的资源满足进程 P"
<< process_id << " 的请求。进程必须等待。" << std::endl;
return false;
}
}
// 3. 试探性分配资源
for (int i = 0; i < num_resources; ++i) {
available[i] -= request[i];
allocation[process_id][i] += request[i];
need[process_id][i] -= request[i];
}
// 4. 检查安全性
if (isSafeState()) {
std::cout << "资源分配成功。" << std::endl;
return true;
} else {
// 5. 撤销试探性分配
for (int i = 0; i < num_resources; ++i) {
available[i] += request[i];
allocation[process_id][i] -= request[i];
need[process_id][i] += request[i];
}
std::cerr << "错误: 资源分配会导致系统进入不安全状态。撤销分配。" << std::endl;
return false;
}
}
// 打印当前系统状态
void printState() {
std::cout << "\n当前系统状态:\n";
std::cout << "可用资源: ";
for (int i = 0; i < num_resources; ++i) {
std::cout << available[i] << " ";
}
std::cout << std::endl;
std::cout << "\n最大需求矩阵:\n";
for (int i = 0; i < num_processes; ++i) {
std::cout << "P" << i << ": ";
for (int j = 0; j < num_resources; ++j) {
std::cout << max[i][j] << " ";
}
std::cout << std::endl;
}
std::cout << "\n已分配资源矩阵:\n";
for (int i = 0; i < num_processes; ++i) {
std::cout << "P" << i << ": ";
for (int j = 0; j < num_resources; ++j) {
std::cout << allocation[i][j] << " ";
}
std::cout << std::endl;
}
std::cout << "\n需求矩阵:\n";
for (int i = 0; i < num_processes; ++i) {
std::cout << "P" << i << ": ";
for (int j = 0; j < num_resources; ++j) {
std::cout << need[i][j] << " ";
}
std::cout << std::endl;
}
}
};
// 示例使用
int main() {
// 系统有5个进程(P0-P4),3种资源(A,B,C)
int num_processes = 5;
int num_resources = 3;
// 初始可用资源:A=3, B=3, C=2
std::vector<int> available = {3, 3, 2};
// 最大需求矩阵
std::vector<std::vector<int>> max = {
{7, 5, 3}, // P0
{3, 2, 2}, // P1
{9, 0, 2}, // P2
{2, 2, 2}, // P3
{4, 3, 3} // P4
};
// 创建银行家算法实例
BankersAlgorithm banker(num_processes, num_resources, available, max);
// 设置初始分配
std::vector<std::vector<int>> initial_alloc = {
{0, 1, 0}, // P0
{2, 0, 0}, // P1
{3, 0, 2}, // P2
{2, 1, 1}, // P3
{0, 0, 2} // P4
};
// 应用初始分配(直接修改内部状态)
for (int i = 0; i < num_processes; ++i) {
for (int j = 0; j < num_resources; ++j) {
banker.requestResources(i, initial_alloc[i]);
break; // 只需调用一次,内部会处理整个向量
}
}
// 打印初始状态
banker.printState();
// 检查初始状态是否安全
std::cout << "\n检查初始状态安全性:\n";
banker.isSafeState();
// 模拟进程1请求额外资源
std::vector<int> request1 = {1, 0, 2};
std::cout << "\n进程 P1 请求资源: A=1, B=0, C=2\n";
banker.requestResources(1, request1);
banker.printState();
// 模拟进程4请求资源(会导致不安全状态)
std::vector<int> request4 = {3, 3, 0};
std::cout << "\n进程 P4 请求资源: A=3, B=3, C=0\n";
banker.requestResources(4, request4);
banker.printState();
return 0;
}
算法工作流程理解
考虑一个系统有5个进程(P0-P4)和3种资源(A,B,C):
- 可用资源:
Available = [3, 3, 2] - 最大需求和分配如下:
| 进程 | Max (A,B,C) | Allocation (A,B,C) | Need (A,B,C) |
|---|---|---|---|
| P0 | 7,5,3 | 0,1,0 | 7,4,3 |
| P1 | 3,2,2 | 2,0,0 | 1,2,2 |
| P2 | 9,0,2 | 3,0,2 | 6,0,0 |
| P3 | 2,2,2 | 2,1,1 | 0,1,1 |
| P4 | 4,3,3 | 0,0,2 | 4,3,1 |
安全性检查过程:
- 初始化:
Work = [3,3,2],Finish = [F,F,F,F,F]- 寻找可执行进程:
- P3:
Need[3] = [0,1,1] ≤ Work = [3,3,2]✓- 假设P3完成:
Work = [3+2, 3+1, 2+1] = [5,4,3]- 继续寻找:
- P1:
Need[1] = [1,2,2] ≤ Work = [5,4,3]✓- 假设P1完成:
Work = [5+2, 4+0, 3+0] = [7,4,3]- 继续寻找:
- P0:
Need[0] = [7,4,3] ≤ Work = [7,4,3]✓- 假设P0完成:
Work = [7+0, 4+1, 3+0] = [7,5,3]- 继续寻找:
- P2:
Need[2] = [6,0,0] ≤ Work = [7,5,3]✓- 假设P2完成:
Work = [7+3, 5+0, 3+2] = [10,5,5]- 继续寻找:
- P4:
Need[4] = [4,3,1] ≤ Work = [10,5,5]✓- 假设P4完成:
Work = [10+0, 5+0, 5+2] = [10,5,7]
结果:安全序列为 <P3, P1, P0, P2, P4>
资源请求示例:
当P1请求
[1,0,2]资源:
- 检查合法性:
Request[1] = [1,0,2] ≤ Need[1] = [1,2,2]✓- 检查可用性:
Request[1] = [1,0,2] ≤ Available = [3,3,2]✓- 试探性分配后,新的状态:
Available = [2,3,0]Allocation[1] = [3,0,2]Need[1] = [0,2,0]- 安全性检查:找到安全序列(
<P3, P4, P1, P0, P2>)
结果:对于P1而言资源分配成功
当P4请求
[3,3,0]资源:
- 检查合法性:
Request[4] = [3,3,0] ≤ Need[4] = [4,3,1]✓- 检查可用性:
Request[4] = [3,3,0] ≤ Available = [2,3,0]✗ (A资源不足)
结果:请求被拒绝,P4必须等
2.3 STL智能指针和线程安全
2.3.1 STL中的容器是否是线程安全的?
STL 的设计初衷是把性能发挥到极致,而一旦要通过加锁来保证线程安全,会对性能造成极大影响。而且对于不同的容器,加锁方式不同(比如哈希表的锁表和锁桶),性能表现也可能不一样。因此 STL 默认是不保证线程安全的,如果需要在多线程环境中使用,通常需要由调用者自行确保线程安全。
2.3.2 智能指针是否是线程安全的?
对于 unique_ptr,由于它的作用域仅限于当前代码块,因此不涉及线程安全问题。
而对于 shared_ptr,因为多个对象可能需要共享同一个引用计数变量,所以会存在线程安全问题。但是,标准库在实现时已经考虑到了这一点,并采用了基于原子操作(如 CAS)的方式,来保证 shared_ptr 能够高效、原子地操作其引用计数。
以上就是本博客的全部内容了,如果本博客对你有点用处的话,不要忘了留下小爱心呦

















 1892
1892

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









