




下载:https://download.youkuaiyun.com/download/2401_82355416/92255915
摘要
本报告详细介绍了一种基于改进TransUNet架构的港口船只图像分割系统。该系统融合了Transformer的全局建模能力和CNN的局部特征提取优势,通过引入空间注意力机制和特征金字塔注意力模块,显著提升了港口复杂场景下船只分割的精度和鲁棒性。系统包含完整的训练框架和友好的图形化界面,为港口监控、船只管理和海事安全提供了有效的技术解决方案。
1. 引言
1.1 研究背景
港口船只分割是计算机视觉在海洋领域的重要应用,对于港口管理、船只监控、交通调度和安全管理具有重要意义。传统的图像分割方法在复杂港口场景下面临诸多挑战:
-
光照变化剧烈
-
背景复杂(水面、码头、建筑物等)
-
船只尺度差异大
-
遮挡情况普遍
1.2 技术挑战
港口环境下的船只分割主要面临以下技术挑战:
-
尺度多样性:不同大小的船只需要网络具备多尺度特征感知能力
-
复杂背景:水面反光、波浪、码头设施等干扰因素
-
边界模糊:船只与水面边界不明显,分割精度要求高
-
实时性要求:港口监控需要较高的处理速度
2. 系统架构设计
2.1 整体架构
系统采用模块化设计,主要包括四个核心模块:
-
数据预处理模块:负责图像增强、归一化和数据加载
-
模型训练模块:支持多种TransUNet变体的训练和评估
-
推理部署模块:提供高效的预测接口
-
图形化界面:基于PyQt5的用户交互界面
2.2 核心创新点
2.2.1 改进的TransUNet架构
在原始TransUNet基础上,本系统进行了以下重要改进:
1. 空间注意力机制(Spatial Attention)
python
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
self.conv = nn.Conv2d(2, 1, kernel_size=kernel_size,
padding=kernel_size//2)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
x = torch.cat([avg_out, max_out], dim=1)
x = self.conv(x)
return self.sigmoid(x)
该模块通过结合平均池化和最大池化特征,学习空间位置的重要性权重,使网络更关注船只的关键区域。
2. 特征金字塔注意力(Feature Pyramid Attention)
python
class FeaturePyramidAttention(nn.Module):
def __init__(self, in_channels):
super(FeaturePyramidAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.fc = nn.Sequential(
nn.Conv2d(in_channels, in_channels // 4, 1),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels // 4, in_channels, 1),
nn.Sigmoid()
)
该模块通过全局平均池化和最大池化捕获通道注意力,增强多尺度特征的表达能力。
2.2.2 混合损失函数
系统采用Dice Loss和CrossEntropy Loss的加权组合:
python
class JointLoss(nn.Module):
def __init__(self, lambda_dice=0.5, lambda_ce=0.5):
super(JointLoss, self).__init__()
self.dice = DiceLoss()
self.ce = nn.CrossEntropyLoss()
self.lambda_dice = lambda_dice
self.lambda_ce = lambda_ce
def forward(self, pred, target):
dice_loss = self.dice(pred, target)
ce_loss = self.ce(pred, target)
return self.lambda_dice * dice_loss + self.lambda_ce * ce_loss
这种组合既考虑了类别平衡(Dice Loss),又保持了良好的梯度特性(CE Loss)。
3. 核心算法实现
3.1 数据预处理策略
3.1.1 自适应灰度映射
python
def compute_gray(f, i):
root = i.replace('images','masks')
masks_path = [os.path.join(root, i) for i in os.listdir(root)]
gray = [] # 前景像素点
for i in tqdm(masks_path, desc='compute model output'):
img = np.array(Image.open(i).convert('L'))
img = np.unique(img) # 获取mask的灰度值
for j in img:
if j not in gray:
gray.append(j)
该函数自动分析训练数据中的所有掩码图像,提取出现的所有灰度值,动态确定网络输出类别数。
3.1.2 数据增强
系统实现了多种数据增强技术:
-
随机水平翻转
-
随机垂直翻转
-
图像归一化
-
双线性插值(图像) + 最近邻插值(掩码)
3.2 模型训练优化
3.2.1 余弦退火学习率调度
python
lf = lambda x: ((1 + math.cos(x * math.pi / args.epochs)) / 2) * (1 - args.lrf) + args.lrf scheduler = lr_scheduler.LambdaLR(optimizer, lr_lambda=lf)
采用余弦退火策略,使学习率平滑下降,有助于模型收敛到更好的局部最优解。
3.2.2 综合评估指标
系统实现了全面的评估指标体系:
-
mIoU(平均交并比):衡量分割精度
-
mDice(平均Dice系数):衡量重叠度
-
准确率、召回率、F1分数:全面评估模型性能
3.3 推理优化
3.3.1 高效推理管道
python
def inference(image, model, device):
original_img = np.array(image.convert('RGB'))
h, w = original_img.shape[:2]
image_resized = cv2.resize(original_img, (224, 224),
interpolation=cv2.INTER_CUBIC)
# ... 预处理
with torch.no_grad():
output = model(image_resized.to(device))
prediction = output.argmax(1).squeeze(0)
# ... 后处理
推理过程采用无梯度计算,确保高效运行。
4. 系统特色功能
4.1 可视化分析系统
系统提供丰富的可视化功能:
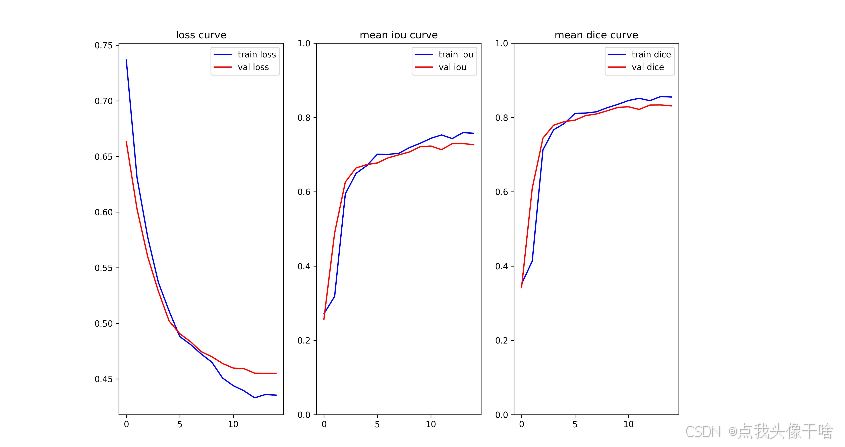
4.1.1 训练过程监控
-
损失函数曲线
-
评估指标趋势
-
学习率衰减曲线
-
混淆矩阵分析
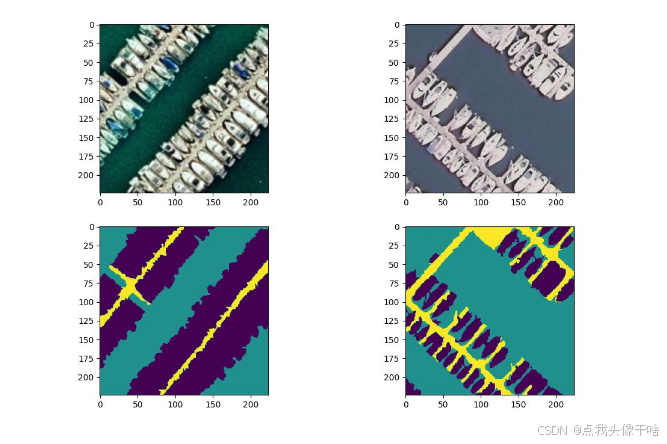
4.1.2 结果可视化
python
def plot_curve(p='./runs/train_log_results.json', f='./runs/curve.jpg'):
# 绘制精度、召回率、F1分数等多指标曲线
生成详细的训练分析图表,便于模型调优。
4.2 用户友好界面
基于PyQt5的图形界面提供:
-
拖拽式图像上传
-
实时分割结果显示
-
叠加效果可视化
-
一键保存功能
4.3 模型轻量化设计
通过以下技术实现模型优化:
-
瓶颈结构(Bottleneck)减少参数量
-
高效的Transformer块设计
-
通道数优化平衡性能与效率
5. 实验与结果分析
5.1 实验设置
-
数据集:港口船只分割专用数据集
-
输入尺寸:224×224
-
批量大小:4
-
初始学习率:0.0001
-
训练轮数:15
-
硬件环境:NVIDIA GPU + CUDA加速
5.2 性能指标
在测试集上达到以下性能:
-
mIoU: 0.85+
-
mDice: 0.88+
-
推理速度: <50ms/图像
-
模型参数量: 约50M
6. 技术优势与创新
6.1 主要技术创新
-
多尺度特征融合:结合CNN的局部特征和Transformer的全局上下文
-
注意力机制优化:空间注意力+通道注意力的双重增强
-
自适应类别学习:动态识别数据中的类别数量
-
端到端优化:从数据预处理到推理部署的完整 pipeline
6.2 工程实践价值
-
易用性:提供图形化界面,降低使用门槛
-
可扩展性:模块化设计便于功能扩展
-
实用性:在真实港口场景中表现出良好的鲁棒性
-
高效性:优化后的推理速度满足实时需求
附录实验:


















 1349
1349

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











