




哈希表是什么
哈希(hash)⼜称散列,是⼀种组织数据的⽅式。从译名来看,有散乱排列的意思。本质就是通过哈希
函数把关键字Key跟存储位置建⽴⼀个映射关系,查找时通过这个哈希函数计算出Key存储的位置,进
⾏快速查找。也就是说给定一个数值,快速查找出这个数值的所在位置
直接地址法
根据上面的概念,我们很容易想到一个存放数据的结构可以实现这个功能,那就是数组,因为数组他是带下标的,我们可以直接根据下标来快速查找想要找的数值,就比如说一堆数据,他在0-99之间,那我们可以直接开一个100个空间大小的数组,这样就可以直接通过对数组下标的索引快速找到想要的数值,这个方法是非常高效的,这个方法又称为直接地址法,当然代码实现也非常简单
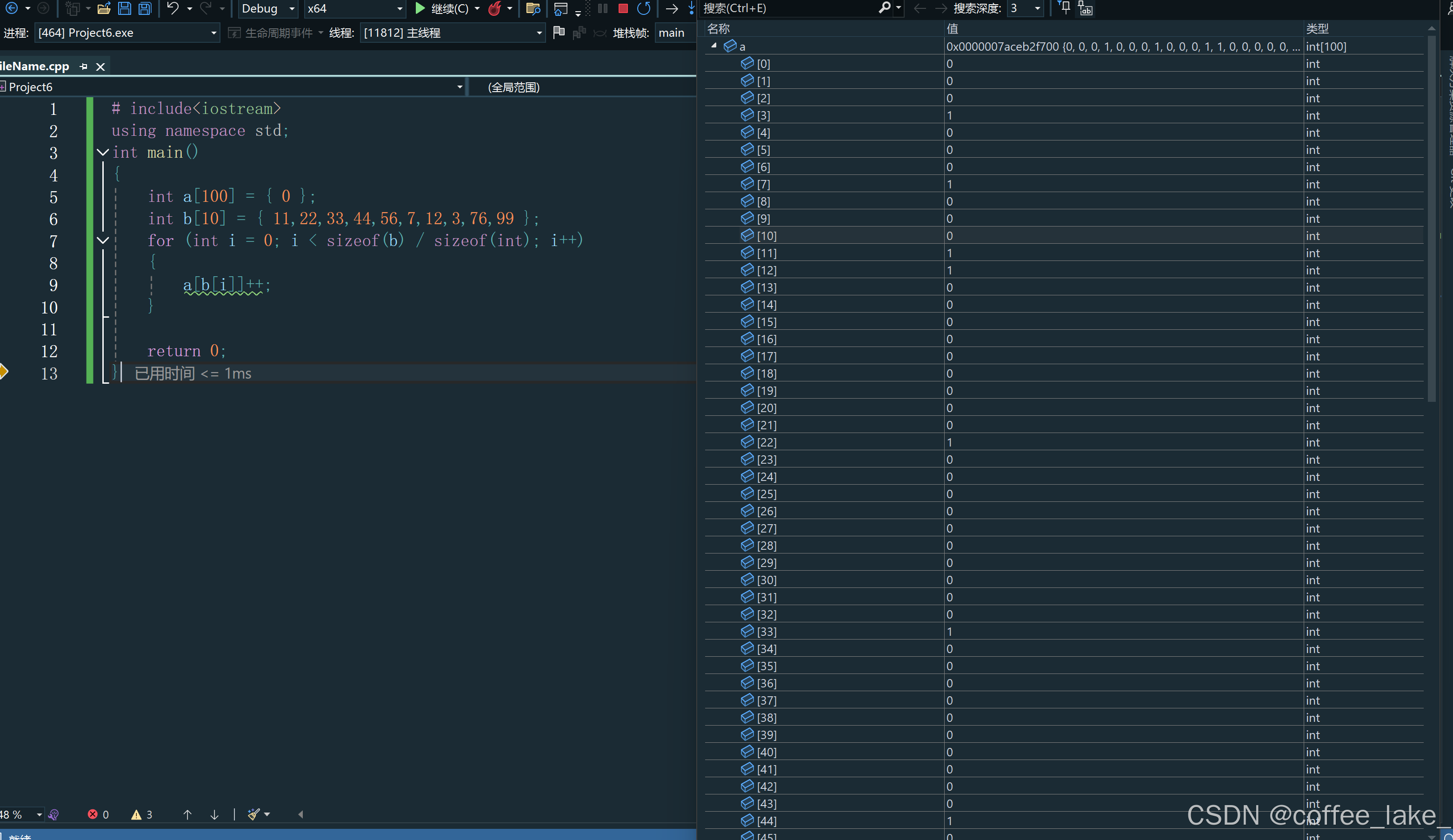
上面的代码,我们用了直接地址法在a[]的数组中统计b[]数组里面的数字出现的次数。我们假设b[]的数组存放的值是0-99之间的数字,但b里面只存放了10个数字,但我们a却需要开100个空间,这是非常浪费的,这也是直接地址法的一个缺点,如果数据不太集中就会造成空间上的很大的浪费
哈希冲突
假设我们只有数据范围是[0, 9999]的N个值,我们要映射到⼀个M个空间的数组中(⼀般情况下M >= N),那么就要借助哈希函数(hash function)hf,关键字key被放到数组的h(key)位置,这⾥要注意的是h(key)计算出的值必须在[0, M)之间。
这⾥存在的⼀个问题就是,两个不同的key可能会映射到同⼀个位置去,这种问题我们叫做哈希冲突,或者哈希碰撞。理想情况是找出⼀个好的哈希函数避免冲突,但是实际场景中,冲突是不可避免的,所以我们尽可能设计出优秀的哈希函数,减少冲突的次数,同时也要去设计出解决冲突的⽅案。这就是哈希冲突
除留余数法
除留余数法又称除法散列法,顾名思义假设哈希表的大小为m我们需要把关键字key的值去用key%m把除下来的余数作为这个key的对应值去放到哈希表中 也就是哈希函数为:h(key) = key % M
我们在使用除留余数法的时候开m的空间需要避免一些特定的值,就比如说2的幂,10的幂等,为什么需要避免这些情况的出现,那是因为如果m的大小是16,也就是2的四次方 假设我们的哈希表里面要存放63,31这两个值,看起来这两个值没有任何区别,但是如果我们用63去除以16 他就余15 如果把余数继续除的话就等于3.9375,而用31去除以16的话他也余15,如果把余数继续除的话就等于1.9375,这两个余数是一样的,那么就会产生冲突,那么key %2的x次方本质相当于保留key的后X位,那么后x位相同的值,计算出的哈希值都是⼀样的,就冲突了如果是10的次方的话就更加明显了,假设m的大小是10的二次方,我们要把123,123123给映射进去的话,都会映射到23这个位置那么计算出的哈希值都是23。
所以根据上面的这种情况,建议M取不太接近2的整数次冥的⼀个质数(素数)。
在c++的标准库里面就提供了这样提供素数的函数
inline unsigned long __stl_next_prime(unsigned long n)
{
static const int __stl_num_primes = 28;
static const unsigned long __stl_prime_list[__stl_num_primes] = {
53, 97, 193, 389, 769,
1543, 3079, 6151, 12289, 24593,
49157, 98317, 196613, 393241, 786433,
1572869, 3145739, 6291469, 12582917, 25165843,
50331653, 100663319, 201326611, 402653189, 805306457,
1610612741, 3221225473, 4294967291
};
const unsigned long* first = __stl_prime_list;
const unsigned long* last = __stl_prime_list + __stl_num_primes;
const unsigned long* pos = lower_bound(first, last, n);
return pos == last ? *(last - 1) : *pos;
}
处理哈希冲突
负载因子
假设哈希表中已经映射存储了N个值,哈希表的⼤⼩为M,那么 ,负载因⼦有些地⽅也翻译为载荷因⼦/装载因⼦等,负载因⼦越⼤,哈希冲突的概率越⾼,空间利⽤率越⾼;负载因⼦越⼩,哈希冲突的概率越低,空间利⽤率越低 负载因子等于m/n,m是空间总大小n是已用空间大小
开放地址法
有了冲突我们必须要解决他
我们这里就要用到开放地址法,开放地址法就是说当两个key的哈希值算出来都一样时,我们就需要把第二个哈希值
按照某一种规则,找到一个空闲的区间,开放定址法中负载因⼦⼀定是⼩于总空间大小的。
这里我们用的方法是线性探测
线性探测就是当此区域有数据存放的时候,我们在此区域的基础上向后一个一个探测,直到找到一个空闲区域的时候就停止探测,如果探测到最后一个位置的时候还没有找到,那么就回绕到开头,从头开始探测,当然探测方法不仅仅只限于线性探测,还有⼆次探测、双重探测。
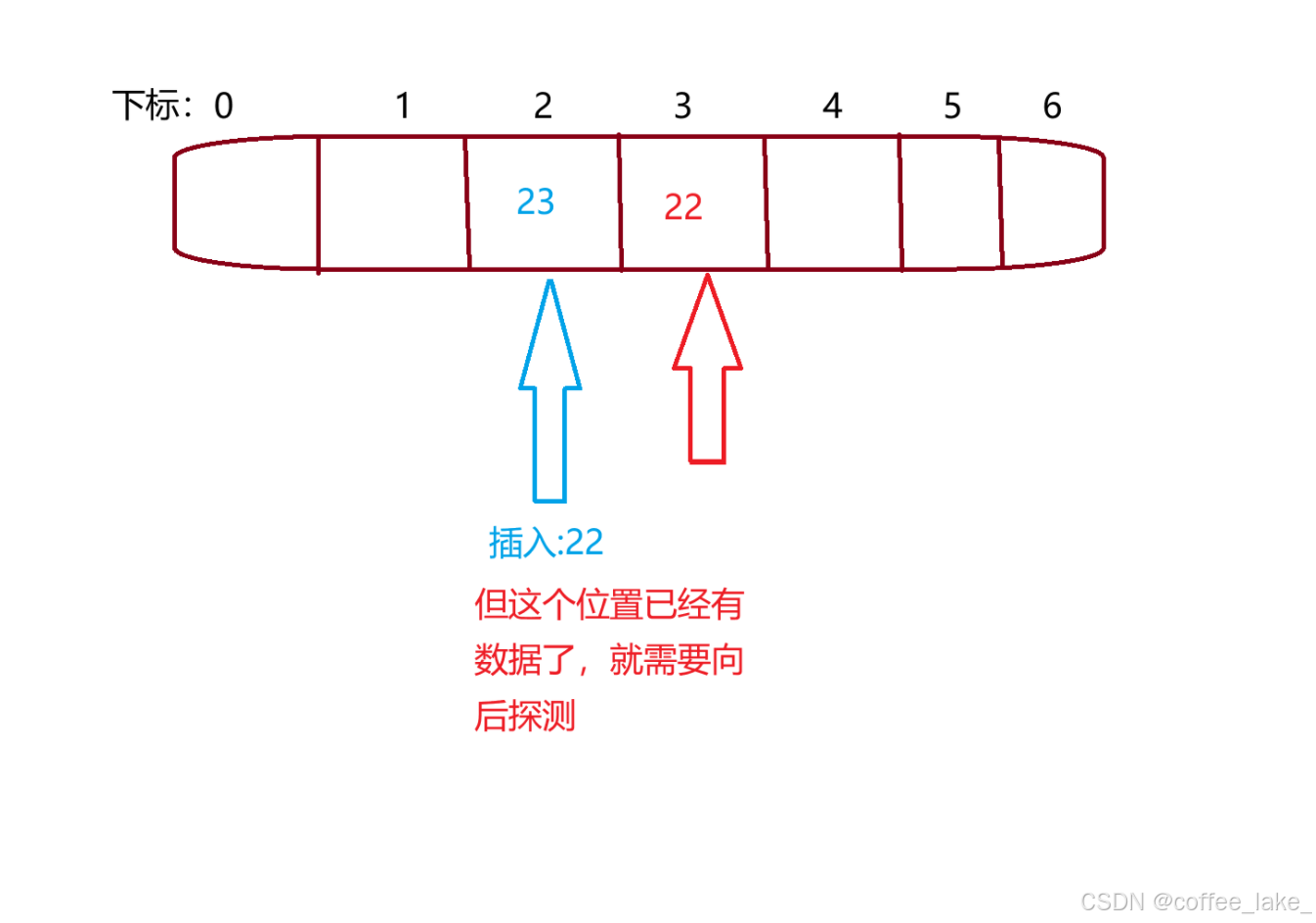
线性探测的公式为:(hsah0+i)%M; i = {1, 2, 3, …, M − 1}因为负载因子要小于1,那么则最多探测m-1次,就找到空闲位置了(取%是为了防止越界,如果越界就回到开头从头探测)
线性探测的⽐较简单且容易实现,线性探测的问题假设,hash0位置连续冲突,hash0,hash1,hash2位置已经存储数据了,后续映射到hash0,hash1,hash2,hash3的值都会争夺hash3位置,这种现象叫做群集/堆积。下⾯的⼆次探测可以⼀定程度改善这个问题。二次探测就相当于是(hsah0±i*i)%M;在hash0的位置两边反复横跳,这样就会相对减少堆积。
下面来看看代码实现
开放地址法的代码实现
这里我们用的是线性探测
首先我们要用到枚举,来枚举出每个元素的状态
enum _state
{
EXIST,//存在
EMPTY,//空
DELETE//删除
};
为什么这里需要一个delete来标识删除,这是由于为了解决地址抢占问题所设计的,如果我要删除一个key这个key本来对应的hsah位置是另一个数,他由于他的位置被抢占了,需要向后探测,找到一个空位置,如果此时,占据了他原本那个数被删除了,这个位置就变空了,用哈希函数查找锁定到这个位置时已经变空了,就查找不到也就不能删除,如果我们增加一个delete状态指示(这里的delete不会真的删除只会把状态标识成delete但数据原本还在那个位置),就会知道这里是被删除了,但所对应的值不是想要查找的那个,就会继续向后探测
hash_data的数据结构
template<class k, class v>
struct  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 306
306

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









