




前言
上个博文中只提到了简单的查询使用,这里接着介绍多表查询、聚合函数、子查询等内容。
一、查询语句常用子句及其作用

如果 SQL 语句中同时存在聚合函数、GROUP BY、HAVING ,执行顺序是先通过GROUP BY进行分组 ,然后使用聚合函数对每个分组的数据进行汇总计算,最后用HAVING筛选出符合特定条件的分组。
二、多表查询
1、连接查询
select * from 表1
union
select * from 表2;
2、内连接
内连接也叫等值连接,该连接方式返回的是两个表中连结字段相等的行。也就是交集,有两种方法:
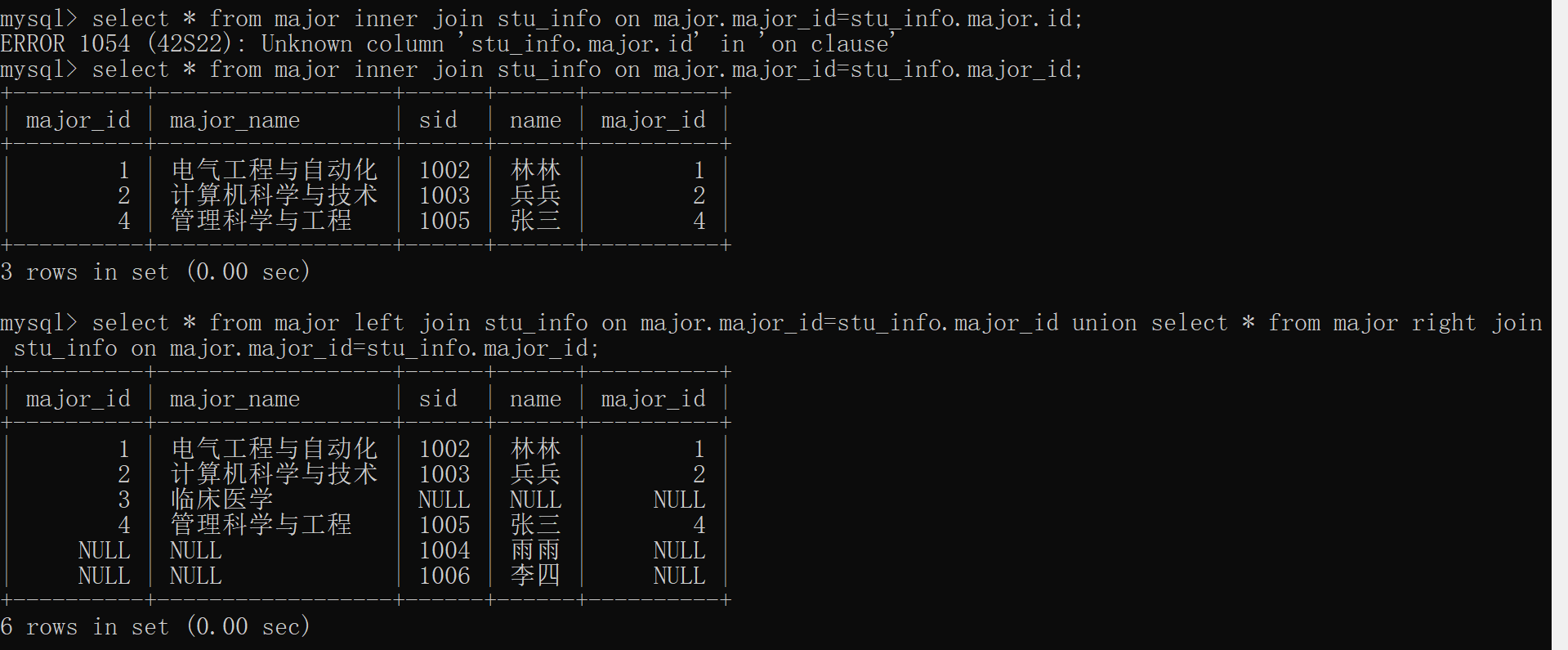
select * from 表1 inner join 表2 on 表1.字段1=表2.字段2;
select * from表1,表2 where 表1.字段1=表2.字段2;
当然,三个表也可以进行连接
select * from 表1 inner join 表2 on 表1.字段1=表2.字段2 inner join 表3 on 表2.字段2=表3.字段3;
3、外连接
外连接又分为左连接、右链接、全连接(并集)全连接没有专门的关键字,但可以通过连接内连接和外连接实现:
select * from 表1 left join 表2 on 表1.字段1=表2.字段2;
select * from 表1 right join 表2 on 表1.字段1=表2.字段2;
select * from major left join stu_info on major.major_id=stu_info.major_id union select * from major right join stu_info on major.major_id=stu_info.major_id;
内连接与外连接的对比:
-可以对比交集与并集去理解
三、聚合函数
1、count(*)用于统计个数
2、max( )、min( )用于计算最大值、最小值
3、avg( )求平均值
4、sum( )求和
四、子查询
1、in和exists的区别
in是从内表开始查询,exists是从外表开始查询的,故而当内表数据较多时可选择exists。
2、all与any的用法
all所有条件必须同时满足,而any 只满足其中一个即可
五、一些小总结
1、同时查询非聚合列和聚合函数,要加上group by+非聚合列。例如如果同时查学生姓名和最高分,如果不按照姓名分组的话就不知道最高分对应的是哪个同学;
2、不能在where里面使用聚合函数,因为where是在分组聚合前筛选数据的,而聚合函数是对分组之后的数据进行计算的。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









