




完结
Redis基于内存,常用作于缓存的一种技术,并且Redis存储的方式是以key-value的形式。Redis是如今互联网技术架构中,使用最广泛的缓存,在工作中常常会使用到。Redis也是中高级后端工程师技术面试中,面试官最喜欢问的问题之一,因此作为Java开发者,Redis是我们必须要掌握的。
Redis 是 NoSQL 数据库领域的佼佼者,如果你需要了解 Redis 是如何实现高并发、海量数据存储的,那么这份腾讯专家手敲《Redis源码日志笔记》将会是你的最佳选择。

Java八大基本数据类型有整型:short,int,long;字节型:byte;浮点型:float,double;字符型:char;布尔类型:boolean。

============================================================================
面向对象的三个基本特征有封装,继承和多态。
封装:隐藏部分对象的属性和实现细节,对数据的访问只能通过对外公开的接口,控制在程序中属性的读和修改的访问级别,将抽象得到的数据和行为(或功能)相结合,形成一个有机的整体,通过这种方式对象对内部数据提供了不同级别的保护,防止程序中无关紧要的部分意外的改变或者出错的是用来对象的私有部分。
继承:让某个类型的对象获取另一个类型的对象的属性的方法,继承就是子类继承父类的特征和行为,使子类的对象具有父类的方法,或者子类从父类继承方法 是子类具有父类相同的行为 使用extends关键字实现继承 继承就是子类自动共享父类的数据和方法,是类与类之间的一种关系,提高了软件的可重用性和可扩展性。
多态:多态就是在声明的时候使用父类在实现或调用的时候使用具体的子类,不修改代码既可以改变程序运行时所绑定的具体代码,让程序可以选择多个运行状态这就是多态 对于同一个行为,不同的子类对象具有不同的表现形式,多态的存在要满足三个条件:继承,方法重写,父类引用指向子类的对象。

==========================================================================
首先解释什么是抽象类:
将类与类之间的共同特征提取出来,就可以形成抽象类。
抽象类不能直接实例化对象,但可以使用多态即父类的引用指向子类的对象,抽象类作为父类。
什么是接口:
接口可以看做特殊的抽象类,当然接口也无法实例化和创建对象,在使用时也可以使用多态,父类的引用指向子类的对象,这里的父类就是接口。
区别:
-
抽象类体现的是继承关系(extends),接口体现的是实现关系(implements),一个类可以实现多个接口,而类只能继承一个抽象类。
-
抽象类中可以定义,普通方法,静态方法,抽象方法,提供给子类使用,而接口中的方法都是抽象的,接口中的成员都有固定的修饰符。
-
抽象类中可以有构造方法,而接口中不可以有构造方法
-
抽象类中的抽象方法的访问类型可以是public,protected,但接口中的抽象方法只能是public类型的,并且默认即为public abstract类型。

=================================================================================
1.==号是运算符,而equals()是方法;
2.==既可以比较基本类型的数据,也可以比较引用类型的数据,判断两个变量或实例是不是指向同一个内存空间。equals()只能比较引用类型的数据,用于检查对象的相等性,例如如果双等于号和equals()用于比较对象,当两个对象引用地址相同,双等于号则返回TRUE,而equals()方法可以返回TRUE或FALSE,主要取决于方法重写的实现。
3.==是指对内存地址进行比较 , equals()是对字符串的内容进行比较。
小提示:
String str = "xiaowei";
先在内存中找是不是有"xiaowei"这个对象,如果有,就让str指向那个"hello"
String s = new String("xiaowei");
和其它任何对象一样,每调用一次就产生一个对象,只要它们调用。
String str = “xiaowei”; 如果内存里没有"xiaowei",就创建一个新的对象保存"xiaowei". String str=new String (“xiaowei”) 就是不管内存里是不是已经有"xiaowei"这个对象,都新建一个对象保存"xiaowei"。

===================================================================================
首先说一下SQL注入
SQL注入是一种代码注入技术,用于攻击数据驱动的应用,恶意的SQL语句被插入到执行的实体字段中,攻击者在界面的表单信息或URL上输入一些奇怪的SQL片段(例如“or ‘1’=‘1’”这样的语句),有可能入侵参数检验不足的应用程序。
所以两种方式的区别就体现出来了:
1.#{变量名}可以进行预编译、类型匹配等操作,#{变量名}会转化为jdbc的类型。#方式能够很大程度防止sql注入;
2.$ {变量名}不进行数据类型匹配,直接替换。 方式无法方式sql注入。$ 方式一般用于传入数据库对象,例如传入表名;
3.#会自动加双引号,$不会加双引号。
这两个符号在mybatis中最直接的区别就是:#相当于对数据加上单引号,$相当于直接显示数据(只讨论字符串类型的)。
举个栗子😉😉😉:
-
#对传入的参数视为字符串,也就是它会预编译,
select * from user where name = #{name},比如我传一个xiaowei,那么传过来就是select * from user where name = 'xiaowei'; -
$ 将不会将传入的值进行预编译,
select * from user where name=${name},比如我传一个xiaowei,那么传过来就是select * from user where name = xiaowei; -
#的优势就在于它能很大程度的防止sql注入,而 $ 则不行。比如:用户进行一个登录操作,后台sql验证式样的:
select * from user where username=#{name} and password = #{pwd},如果前台传来的用户名是“xiaoweihaoshuai”,密码是 “1 or 1=1”,用#的方式就不会出现sql注入,而如果换成$方式,sql语句就变成了select * from user where username=wang and password = 1 or 1=1。这样的话就形成了sql注入。
========================================================================================
@Autowired是spring框架提供的实现依赖注⼊的注解,主要⽀持在set⽅法,field,构造函数中完成bean注⼊,注⼊⽅式为通过类型查找bean,即byType类型的,如果存在多个同⼀类型的bean,则使⽤@Qualifier来指定注⼊哪个beanName的bean。
与JDK的@Resource的区别:@Resource是基于bean的名字,即beanName类型的,来从spring的IOC容器查找bean注⼊的,⽽@Autowried是基于类型byType来查找bean注⼊的。
与JDK的@Inject的区别:@Inject也是基于类型来查找bean注⼊的,如果需要指定名称beanName,则可以结合使⽤@Named注解,⽽@Autowired是结合@Qualifier注解来指定名称beanName。
1.@Autowired、@Inject是默认按照类型匹配的,@Resource是按照名称匹配的。如在spring-boot-data项⽬中⾃动⽣成的redisTemplate的bean,是需要通过byName来注⼊的。如果需要注⼊该默认的,则需要使⽤@Resource来注⼊,⽽不是@Autowired。
2.对于@Autowire和@Inject,如果同⼀类型存在多个bean实例,则需要指定注⼊的beanName。
3.@Autowired和@Qualifier⼀起使⽤,@Inject和@Name⼀起使⽤。

==============================================================================
首先介绍下什么是死锁:
两个或两个以上线程,在争抢资源中出现都在等待对方执行完毕才能继续往下执行的时候就发生了死锁,最后这些线程都陷入了无限的等待中。

===========================================================================
由于之前详细写过相关的文章,所以直接给小伙伴儿们附上链接嘿嘿🤩🤩三次握手四次挥手详解
悲观锁:总是假设最坏的情况,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会阻塞,直到它拿到锁。
悲观锁又叫互斥同步锁,它为了确保结果的正确性,会在每次获取到数据后,都会将其锁住,因此当其他线程也来访问时,就会进入阻塞状态,这样就可以防止其他线程访问该数据,从而保证数据的安全性。
Java中我们常用的 Synchronized 及 RenntrantLock 都是悲观锁。
在数据库很多地方就用到了这种锁机制,比如行锁,表锁,读锁,写锁等。
举个栗子😏😏😏:
select * from user where id='1' for update
这条 sql 语句锁定了user表中所有符合检索条件(id=‘1’)的记录。这条数据就被当前事务锁定了,其它的事务必须等本次事务提交之后才能执行,也就是其他线程进入阻塞状态。 这样可以保证当前的数据不会被其它事务修改。(前提是id字段一定是主键或者唯一索引,不然是锁表,会出事的。)
对于悲观锁来说,只能有一个事务占据资源,其他事务被挂起等待持有资源的事务提交并释放资源,CPU就会将这些得不到资源的线程挂起,挂起的线程也会消耗CPU的资源,尤其是在高井发的请求中。
一旦该线程提交了事务,那么锁就会被释放,这个时候被挂起的线程就会开始竞争资源,那么竞争到的线程就会被 CPU 恢复到运行状态,继续运行。
在高并发的过程中,使用悲观锁就会造成大量的线程被挂起和恢复,这将十分消耗资源,所以使用悲观锁性能非常不佳。

最后
为什么我不完全主张自学?
①平台上的大牛基本上都有很多年的工作经验了,你有没有想过之前行业的门槛是什么样的,现在行业门槛是什么样的?以前企业对于程序员能力要求没有这么高,甚至十多年前你只要会写个“Hello World”,你都可以入门这个行业,所以以前要入门是完全可以入门的。
②现在也有一些优秀的年轻大牛,他们或许也是自学成才,但是他们一定是具备优秀的学习能力,优秀的自我管理能力(时间管理,静心坚持等方面)以及善于发现问题并总结问题。
如果说你认为你的目标十分明确,能做到第②点所说的几个点,以目前的市场来看,你才真正的适合去自学。
除此之外,对于绝大部分人来说,报班一定是最好的一种快速成长的方式。但是有个问题,现在市场上的培训机构质量参差不齐,如果你没有找准一个好的培训班,完全是浪费精力,时间以及金钱,这个需要自己去甄别选择。
我个人建议线上比线下的性价比更高,线下培训价格基本上没2W是下不来的,线上教育现在比较成熟了,此次疫情期间,学生基本上都感受过线上的学习模式。相比线下而言,线上的优势以我的了解主要是以下几个方面:
①价格:线上的价格基本上是线下的一半;
②老师:相对而言线上教育的师资力量比线下更强大也更加丰富,资源更好协调;
③时间:学习时间相对而言更自由,不用裸辞学习,适合边学边工作,降低生活压力;
④课程:从课程内容来说,确实要比线下讲的更加深入。
应该学哪些技术才能达到企业的要求?(下图总结)
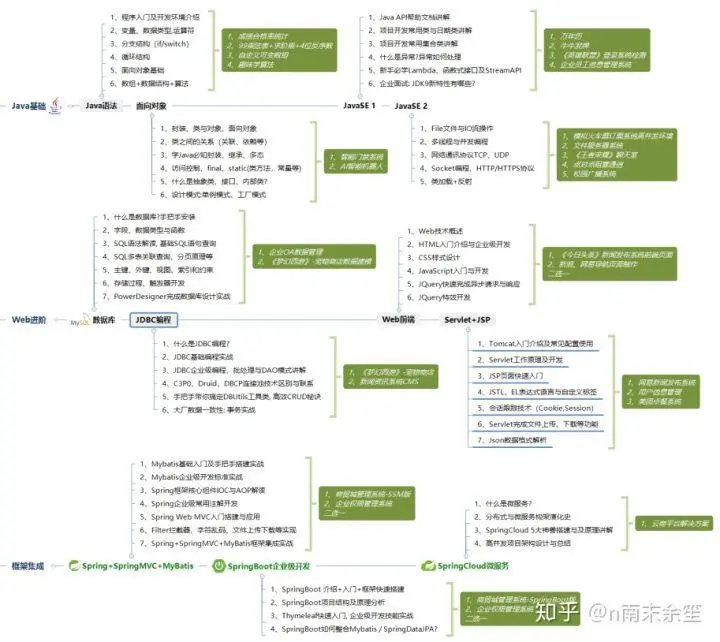
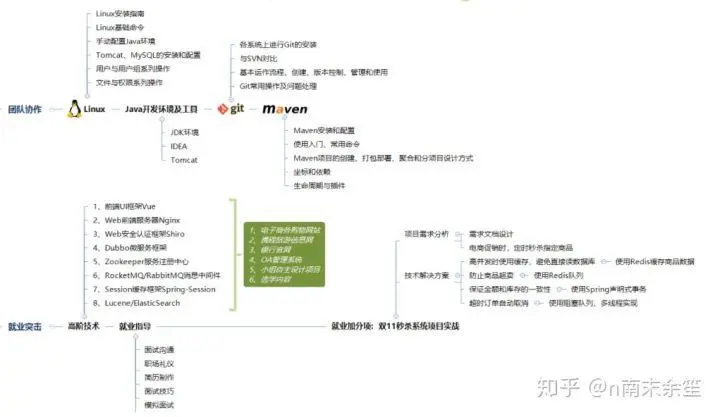
求?(下图总结)**
[外链图片转存中…(img-MvZq8T69-1715615410597)]
[外链图片转存中…(img-wBTZ6W1K-1715615410597)]


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









