



Dify 知识库9 月份迎来了一个非常重大的升级,Knowledge Pipeline !
这次升级,给用户提供了一套可视化、可编排的 RAG 数据处理基础设施,从而系统性地解决了企业级 AI 应用落地的上下文工程(Context Engineering) 瓶颈。
其主要升级价值点有以下这些:
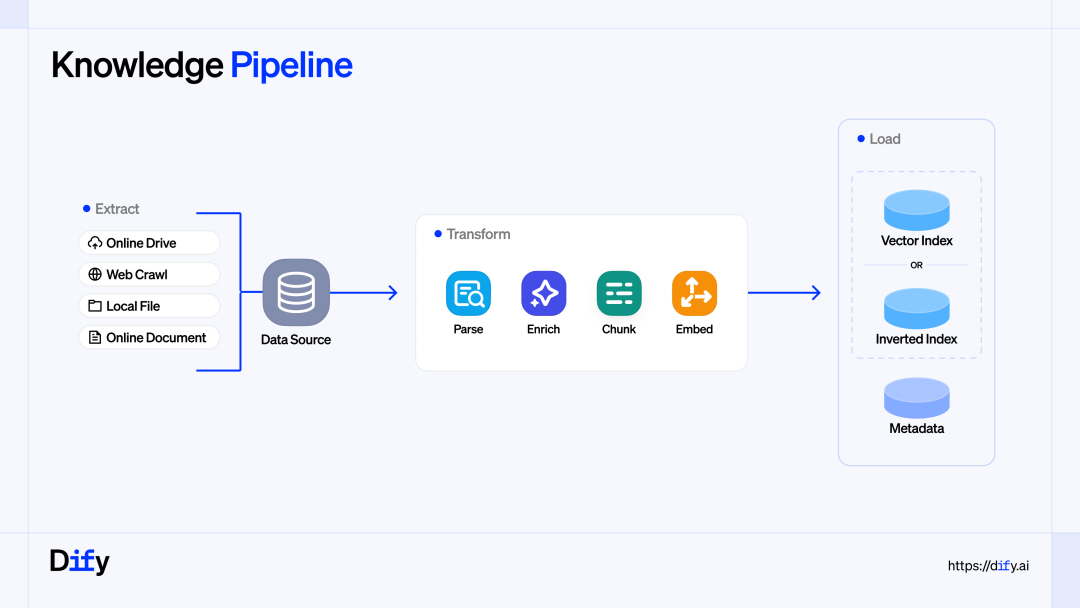
1-零散非结构化文件知识处理能力
大量业务数据分散在非结构化文件中,传统方法难以稳定地将这些分散、异构、持续更新的数据转化为 LLM 能可靠消费的上下文。Knowledge Pipeline 通过系统化设计与调优,成为实践 Context Engineering 的关键基础设施。
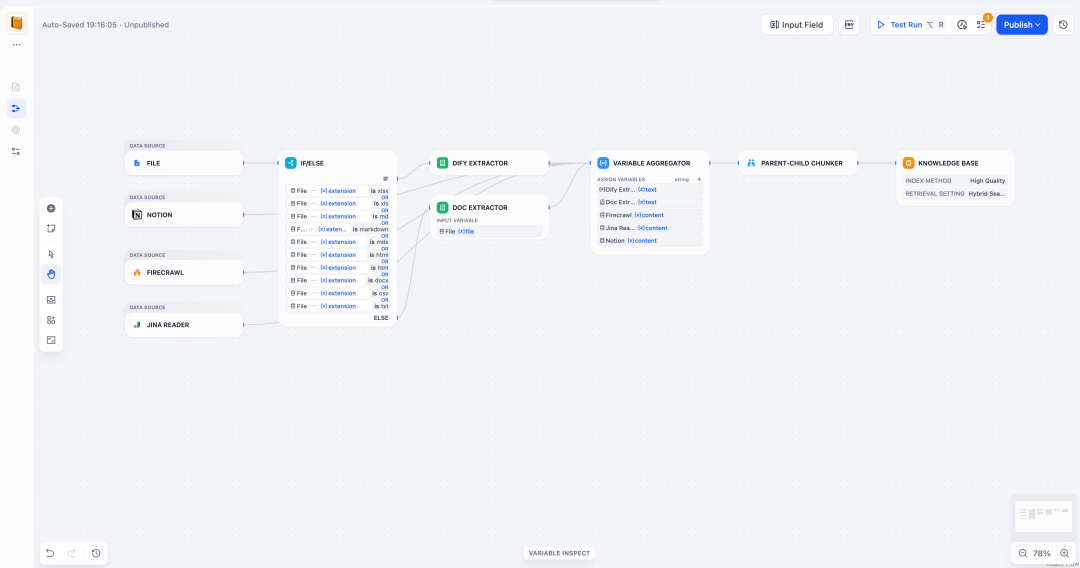
2-增强数据处理的掌控力,解决旧版 RAG黑盒问题
旧版 Dify 数据处理流程如同黑盒,问题难以定位。Knowledge Pipeline 提供了可观测的数据调试过程:
◦ 用户可以通过**测试运行(Test Run)功能对 Pipeline 逐节点执行,查看每一步的输入输出是否符合预期。
◦ 通过变量监视器(Variable Inspect)**实时观察中间变量和上下文,快速定位解析错误或分块异常等问题。
3-极大地降低开发与维护成本
• 价值: 将复杂的数据处理逻辑转化为可复用的资产,提高团队效率。
• 理由: 传统 RAG 项目多为一次性交付。Knowledge Pipeline 将数据处理做成可沉淀、可复用的能力,例如将合同审查或客服知识库的流程做成模板,供团队直接复制和调整,减少重复搭建和后期维护的工作量。
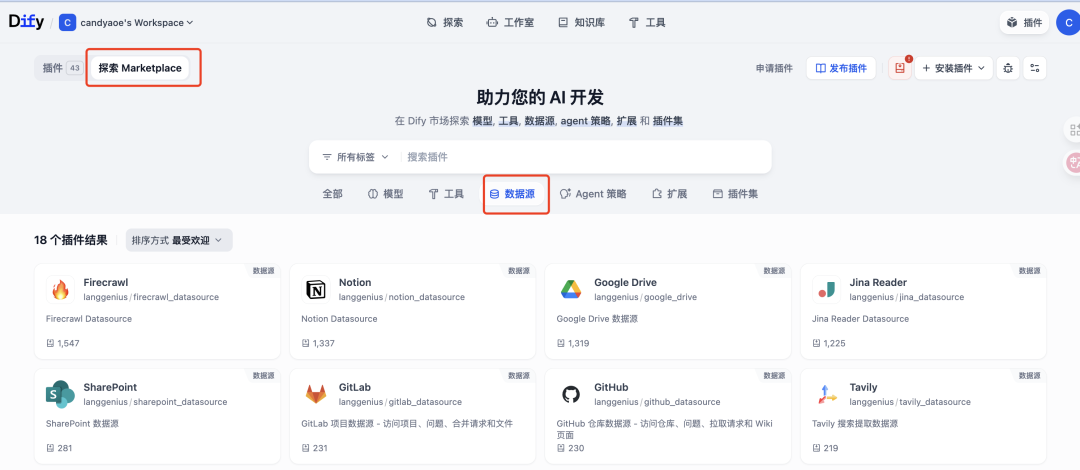
4-开放且灵活的集成能力
轻松接入各种数据源,并集成行业最优的 RAG 解决方案。
◦ 数据源突破: 引入了全新的 Data Source 插件类型,用户通过 Marketplace 插件即可一键接入主流数据源(如 Google Drive, Notion, Firecrawl 等),无需为每种数据源编写定制代码并维护认证逻辑。
◦ 模块化选择: 基于插件化架构,企业在数据处理的各个环节(如解析、结构化提取、向量库)都可以按需选型并随时替换,确保始终采用业界最优解。
5-连接业务需求和技术实现
• 价值: 让业务专家也能参与 AI 系统的优化。
• 理由: 通过可视化编排和实时调试,业务专家可以直接看到数据处理流程,并能上手排查检索问题,减少与技术团队反复沟通的成本,使技术团队能更专注于核心业务项目。

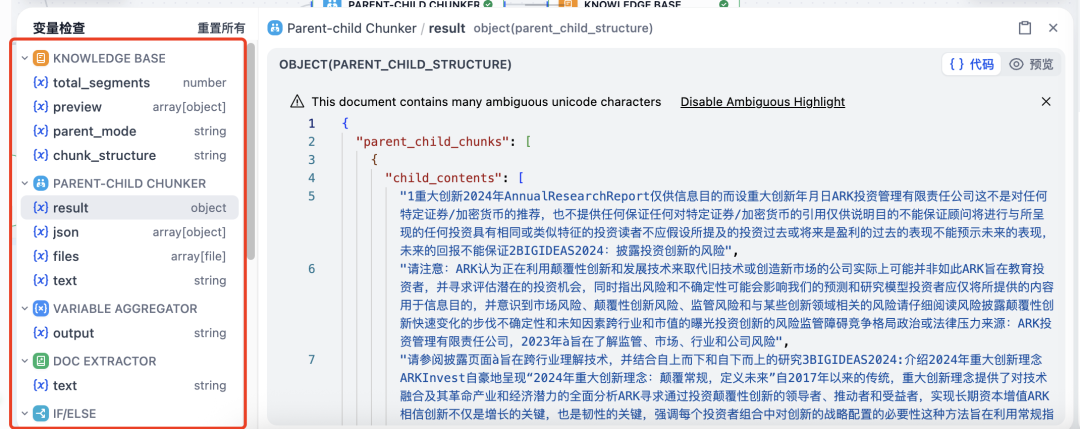
接下来,我测试了一些之前做 Agent 开发比较头疼的场景,比如 PDF 解析(图片类)、表格信息提取、数据图信息提取等,效果非常惊艳!
简单说一下我上传文件格式是 PDF,里面是纯图片模式。需要靠 OCR 解析提取信息。
这份PDF 文件并不是一个好的知识库资料,里面的文字和内容糊出天际。但是,它反而能很好的测试本次 Dify 升级的 Knowledge pipeline 的能力。

一、pipeline 测试效果
我们从简单到复杂,看一下本次的 PDF(图片) 文件的解析结果;
1-文字 OCR 解析能力
问题1:AI 提及次数在财报电话中翻了几倍?
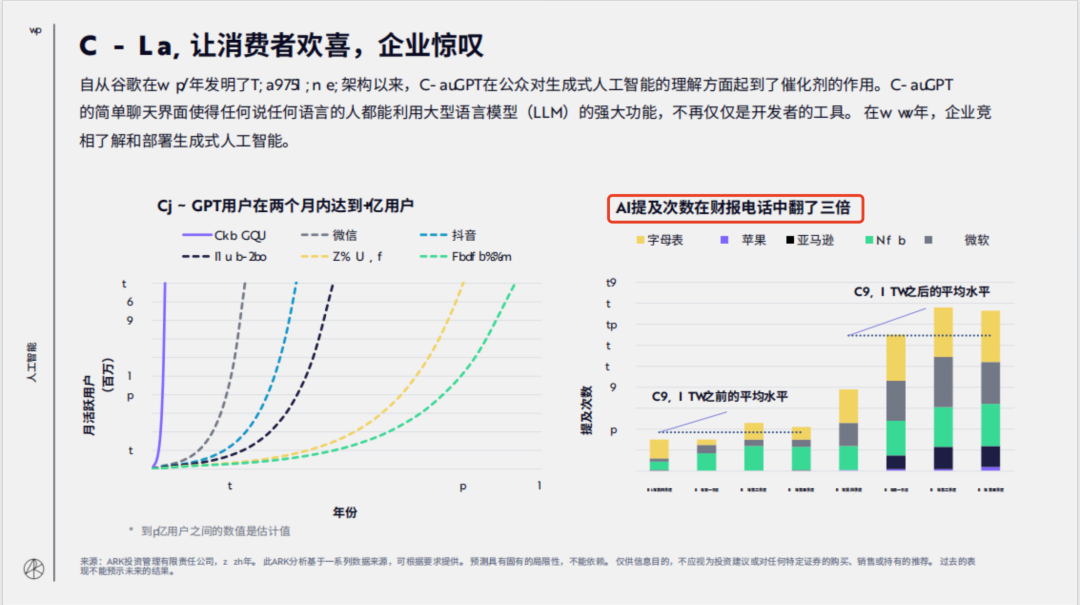
回答:可以看到,这个信息得到了良好的解析和回答。
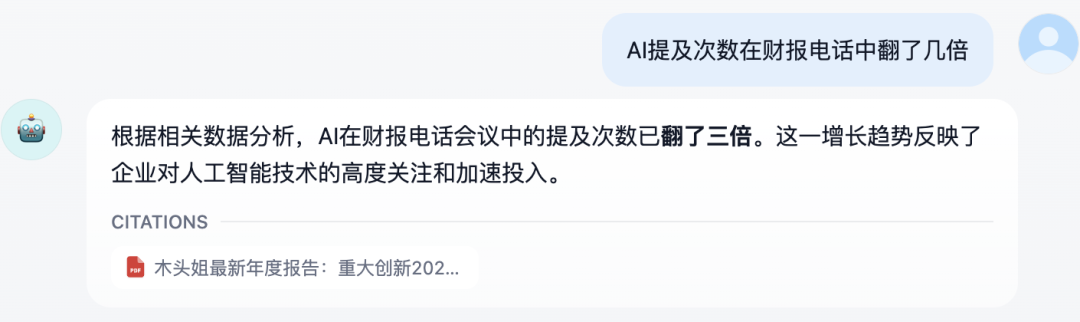
2-非结构化布局信息识别和提取
问题2:HELM评估指标有哪些?
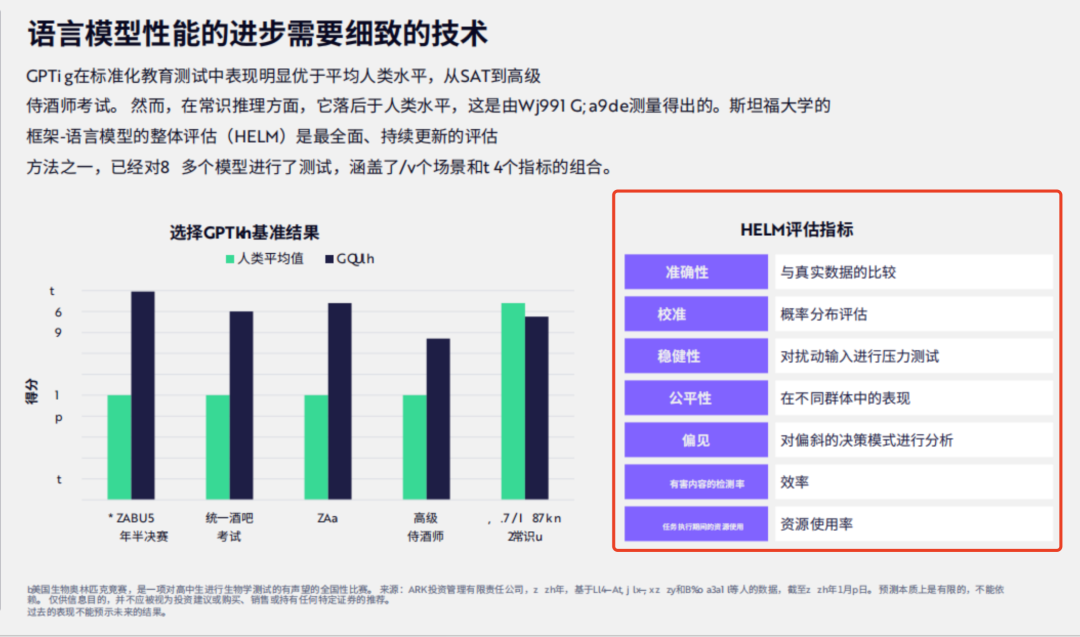
回答:可以看到,右侧的 HELM 评估指标,完整的得到识别和回答。

3-结构化表格信息提取
问题 3:为什么说比特币已成为机构投资组合中值得战略配置的独立资产类别?
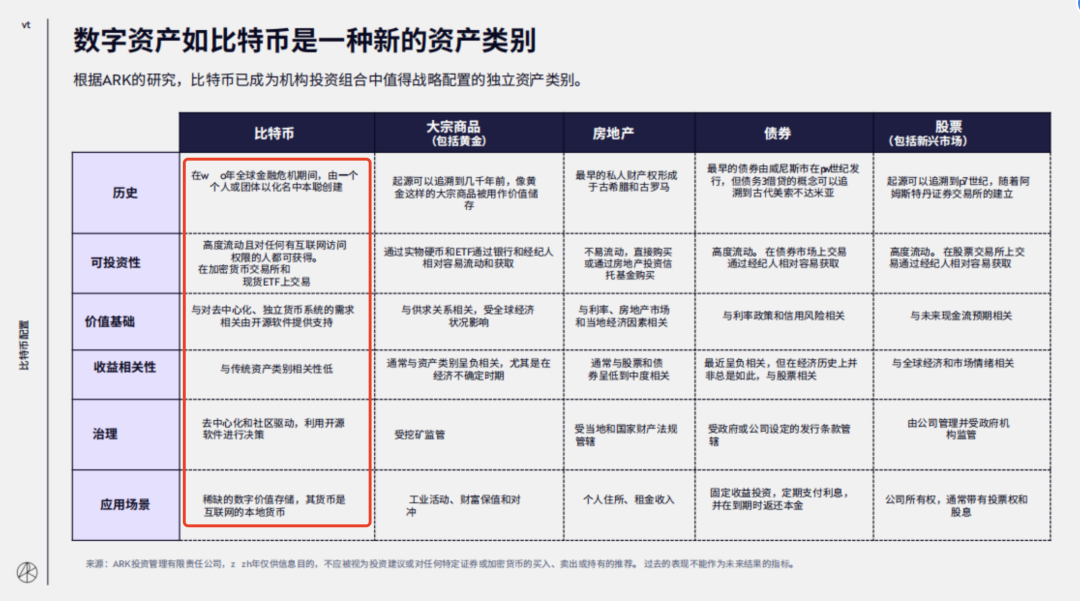
回答:结果比较长,我只把部分回答内容拿出来了。可以看到,答案里已经融合了整个表格的观点,再由大模型进行融合输出。

4-多文档不同类型召回识别
这次,难度再升级一下。我配置了其他的数据结构类型的信息来源。

问题4:介绍一下移动APP—AARRR
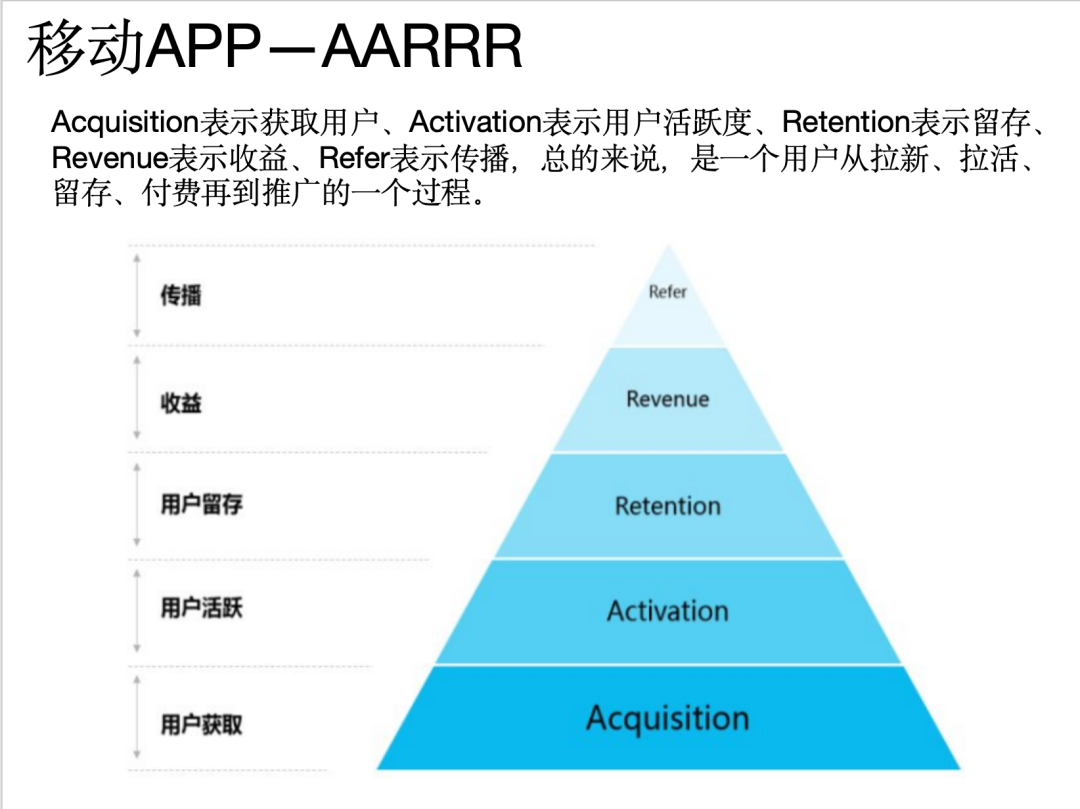
回答:OK,结果非常满意。

问题5:详细说明收入类指标
文档《案例6:app业务指标体系建设(21页 PPT).pptx》相关片段:
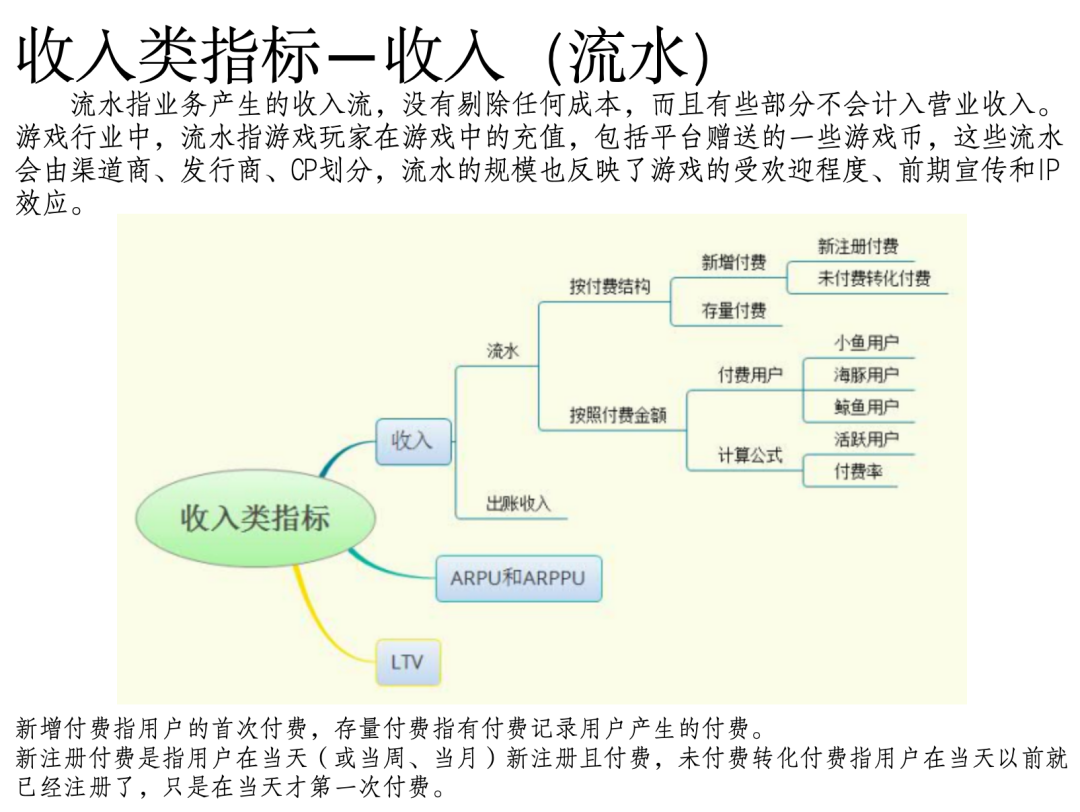
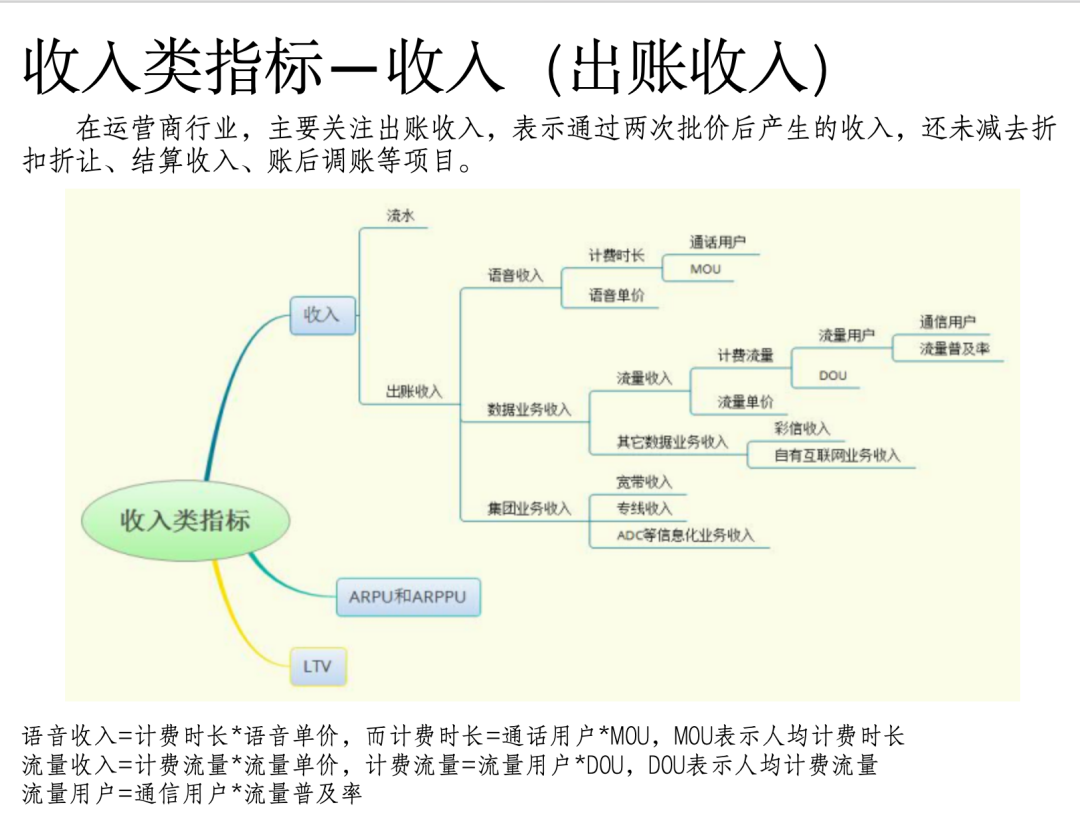
文档《案例7:美团数据指标体系搭建实战.docx》片段:
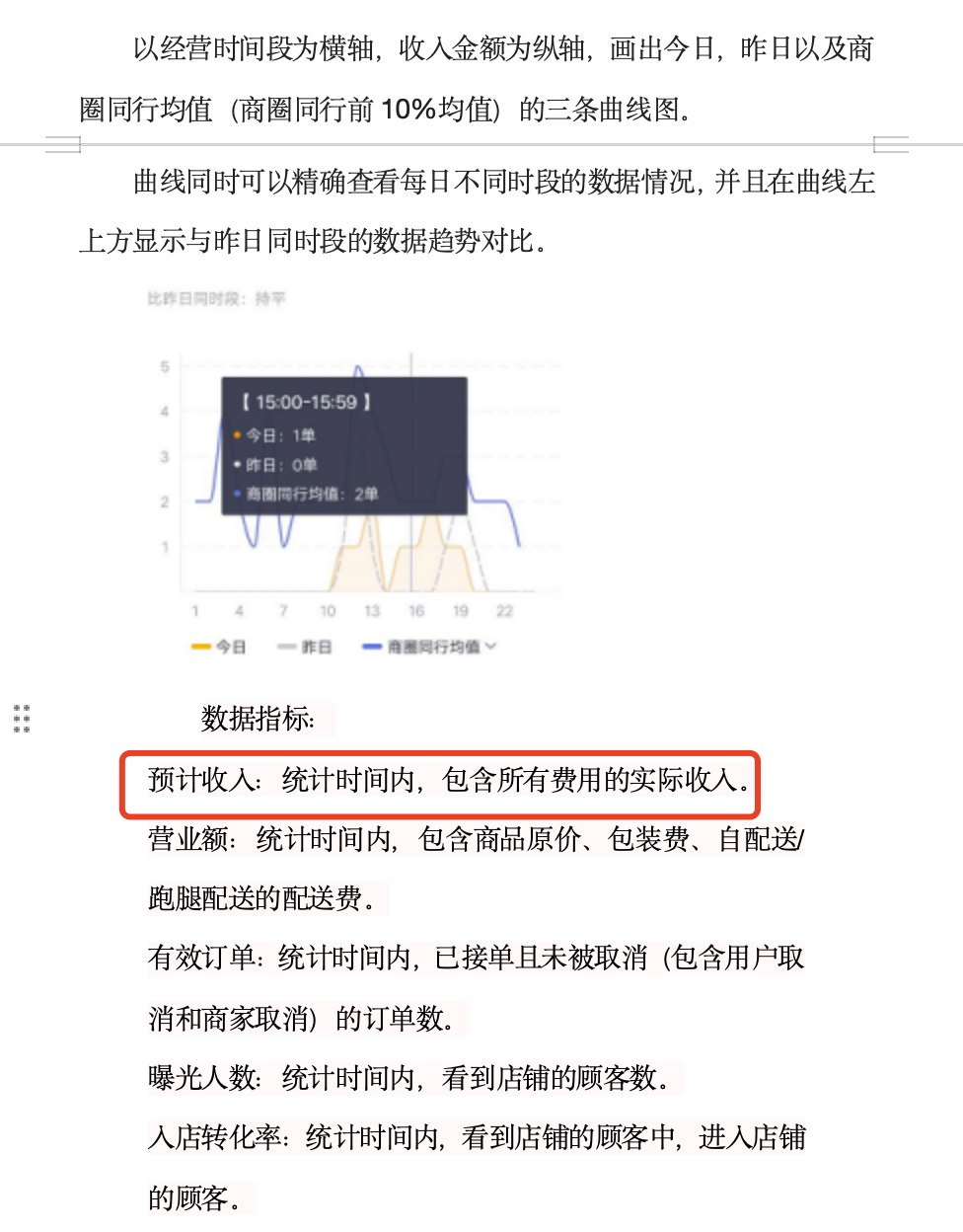
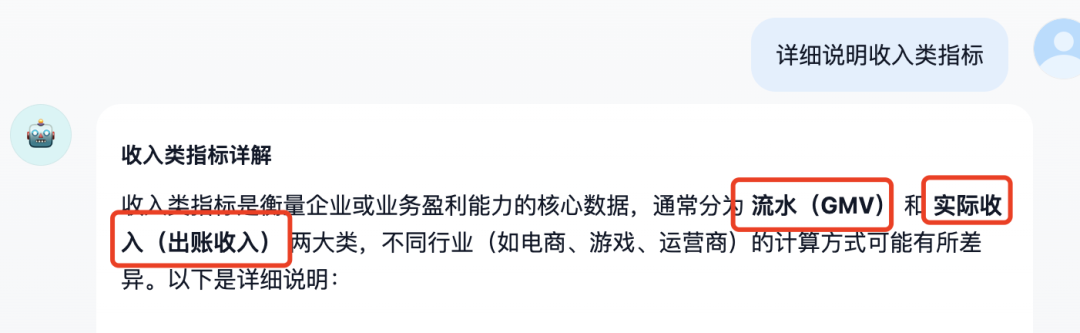
回答:能够综合两个文档内容进行解答。

二、pipeline 配置速通方法
Dify 本次升级在系统里添加了多种类型的模板。
我这次配置的 pipeline 用的是 Dify 内置的模板,选择知识库->通过知识库流水线创建知识库->Parent-child-HQ
下面是这个模板的工作流详情。唯一需要调整的是在最后一个节点:Knowledge Base,需要切换你所使用的 embedding 和 Rerank模型。
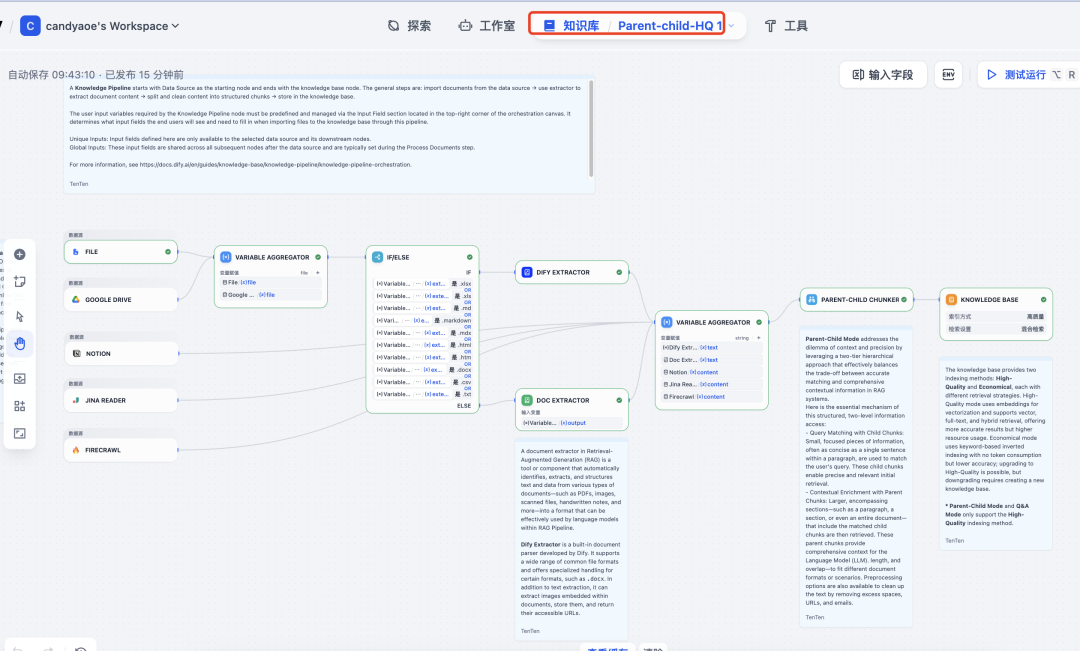
embedding 模型更换,我使用的是硅基流动的 BAAI/beg-m3。
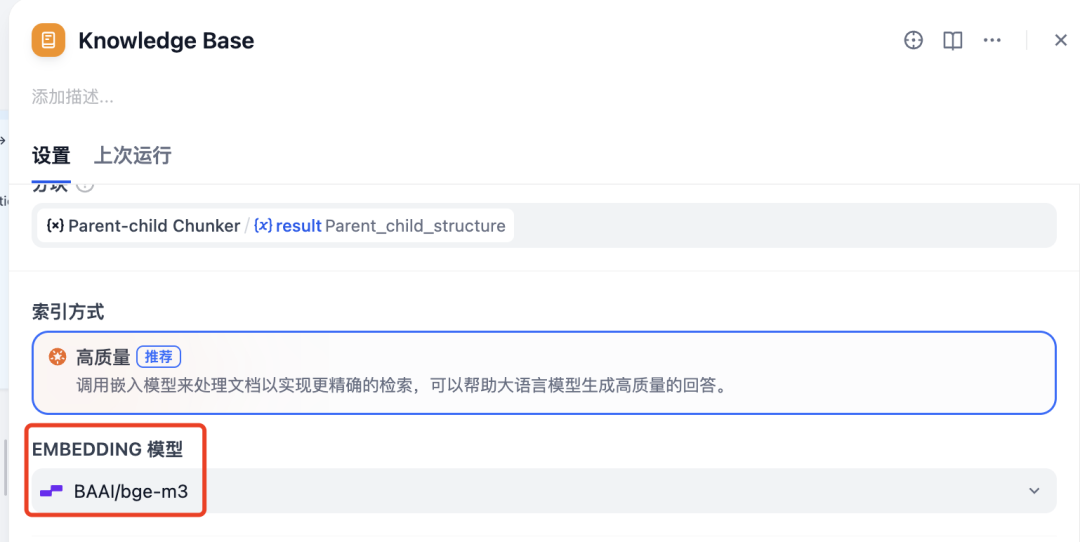
Rerank 模型切换,同样的也是硅基流动的,BAAI/beg-reranker-v2-m3模型。
然后,选择测试运行,上传测试文档。
测试通过后,点击发布,一个完整的 KnowledgePipeline 就发布完成了。
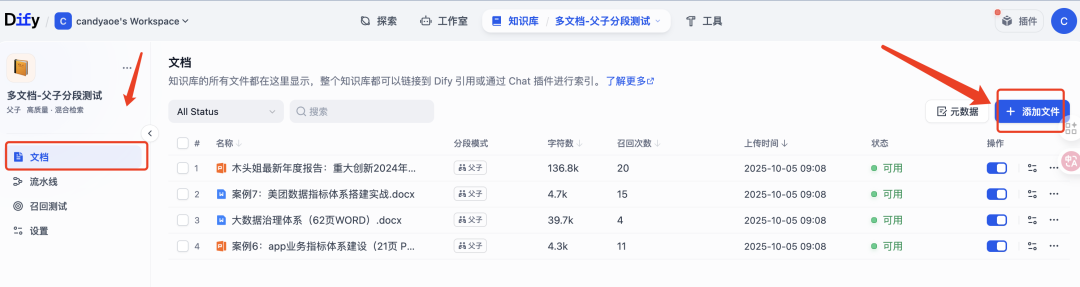
但是,这个时候还不能使用这个知识库,我们需要到“文档”界面,通过“添加文件”,完成解析知识后,才可以在工作流中,配置该知识库。
以上是本次 Dify Knowledge pipeline 的简单测试和快速配置指引。
如果大家对本次升级的其他内容感兴趣,欢迎评论区留言。
想入门 AI 大模型却找不到清晰方向?备考大厂 AI 岗还在四处搜集零散资料?别再浪费时间啦!2025 年 AI 大模型全套学习资料已整理完毕,从学习路线到面试真题,从工具教程到行业报告,一站式覆盖你的所有需求,现在全部免费分享!
👇👇扫码免费领取全部内容👇👇

一、学习必备:100+本大模型电子书+26 份行业报告 + 600+ 套技术PPT,帮你看透 AI 趋势
想了解大模型的行业动态、商业落地案例?大模型电子书?这份资料帮你站在 “行业高度” 学 AI:
1. 100+本大模型方向电子书

2. 26 份行业研究报告:覆盖多领域实践与趋势
报告包含阿里、DeepSeek 等权威机构发布的核心内容,涵盖:

- 职业趋势:《AI + 职业趋势报告》《中国 AI 人才粮仓模型解析》;
- 商业落地:《生成式 AI 商业落地白皮书》《AI Agent 应用落地技术白皮书》;
- 领域细分:《AGI 在金融领域的应用报告》《AI GC 实践案例集》;
- 行业监测:《2024 年中国大模型季度监测报告》《2025 年中国技术市场发展趋势》。
3. 600+套技术大会 PPT:听行业大咖讲实战
PPT 整理自 2024-2025 年热门技术大会,包含百度、腾讯、字节等企业的一线实践:

- 安全方向:《端侧大模型的安全建设》《大模型驱动安全升级(腾讯代码安全实践)》;
- 产品与创新:《大模型产品如何创新与创收》《AI 时代的新范式:构建 AI 产品》;
- 多模态与 Agent:《Step-Video 开源模型(视频生成进展)》《Agentic RAG 的现在与未来》;
- 工程落地:《从原型到生产:AgentOps 加速字节 AI 应用落地》《智能代码助手 CodeFuse 的架构设计》。
二、求职必看:大厂 AI 岗面试 “弹药库”,300 + 真题 + 107 道面经直接抱走
想冲字节、腾讯、阿里、蔚来等大厂 AI 岗?这份面试资料帮你提前 “押题”,拒绝临场慌!

1. 107 道大厂面经:覆盖 Prompt、RAG、大模型应用工程师等热门岗位
面经整理自 2021-2025 年真实面试场景,包含 TPlink、字节、腾讯、蔚来、虾皮、中兴、科大讯飞、京东等企业的高频考题,每道题都附带思路解析:

2. 102 道 AI 大模型真题:直击大模型核心考点
针对大模型专属考题,从概念到实践全面覆盖,帮你理清底层逻辑:

3. 97 道 LLMs 真题:聚焦大型语言模型高频问题
专门拆解 LLMs 的核心痛点与解决方案,比如让很多人头疼的 “复读机问题”:

三、路线必明: AI 大模型学习路线图,1 张图理清核心内容
刚接触 AI 大模型,不知道该从哪学起?这份「AI大模型 学习路线图」直接帮你划重点,不用再盲目摸索!

路线图涵盖 5 大核心板块,从基础到进阶层层递进:一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

四、资料领取:全套内容免费抱走,学 AI 不用再找第二份
不管你是 0 基础想入门 AI 大模型,还是有基础想冲刺大厂、了解行业趋势,这份资料都能满足你!
现在只需按照提示操作,就能免费领取:
👇👇扫码免费领取全部内容👇👇
2025 年想抓住 AI 大模型的风口?别犹豫,这份免费资料就是你的 “起跑线”!

















 886
886

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









