



系列文章目录
Java常用集合的实现类《HashSet和HashMap》
前言
不管是以后Java实际开发还是我们在刷算法题要想提高算法的时间复杂度其实或多或少都需要用到集合,因此我们要加强集合的使用,这篇文章我先带大家简单的了解一下最常见的集合,一个属于单列集合,一个属于双列集合,下面我们开始进行学习.
一、 集合的好处:
我们最应该先了解的就是集合可以动态的保存任意多个对象,并且集合内部提供了一系列方便操作对象的方法。
二、HashSet是什么?
在我的理解中Hashset就是一种容器,只不过在这个实现类中底层就是用一种数据结构来实现其功能的,只不过在HashSet这个实现类中它实际上是基于HashMap的包装类,复用了HashMap的能力。下面我们开始详细解释HashSet这个实现类:
核心:
HashSet是Set接口的实现类,而且Set接口继承了Collection接口,所以我们可以使用Collection的常用方法如add,remove,contains,size等等方法。
HashSet可以存放null值,但是只能有一个null。
HashSet底层就是维护了一个数组+链表+红黑树(当链表的数量过多,而且table数组大小超过64就会变成红黑树),且HashSet不能有重复元素/对象。
HashSet不保证元素是有序的,取决于Hashcode的值,来确定索引的结果,详细看下面的代码。
// HashSet 源码中的关键字段
private transient HashMap<E, Object> map; // 底层依赖的 HashMap 实例
private static final Object PRESENT = new Object(); // 虚拟值,用于填充 Value下面我们讲一下最重要的添加操作:
先看源码:
// HashSet 的 add() 方法源码
public boolean add(E e) {
return map.put(e, PRESENT) == null; // 调用 HashMap 的 put() 方法
} final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}这是添加元素的最核心代码,下面我们来详细的解释一下子什么事:
1.添加一个元素时,先得到hash值(Hash值并不是直接得到的,而是由一定的算法得到的),通过得到的hash值转化成索引值。
2.找到存储数据表table,看这个索引位置是否已经存放的元素。
3.如果没有,直接加入。
4.如果有,调用equals比较,如果相同,就放弃添加,如果不相同,则添加到最后(记得这里的hashcode()和Equals()都可以由程序员决定进行重写)
最明显的例子也是面试题中最容易出错的就是我们假设new两个String类:
Set set = new HashSet();
//向set中添加两个String对象
set.add(new String("yjy"));
set.add(new String("yjy"));这里包括我最开始都答错了,因为惯性思维我们肯定会想两个new出来的肯定开辟了不同的位置的内存空间,所以地址肯定不一样,所以hashcode值也不同,所以肯定可以添加,但是我们要清楚的是String类已经重写了hashcode()和equals()方法,比较的是内容,而内容又相同,所以肯定添加不了而返回false;
所以未重写之前比较的都是地址,重写之后就不一定了。
关于为什么有去重机制(即重复的元素添加不进去):
底层实现:这里的value是默认固定的虚拟对象
// HashSet 源码简化版
public class HashSet<E> {
private HashMap<E, Object> map;
private static final Object PRESENT = new Object(); // 虚拟值
public boolean add(E e) {
return map.put(e, PRESENT) == null;
// 若 Key (e) 已存在,map.put() 返回旧 Value(PRESENT),此时 add() 返回 false
// 若 Key 不存在,map.put() 返回 null,此时 add() 返回 true
}
}三、HashMap是什么?
1.定义:
HashMap这个实现类是独立实现的,它实现了map的接口,是一个双列集合的一种,HashMap中的key不可以重复(会替换掉)但是value是可以重复的。
details:
Map中的key和value可以是任何引用类型的数据,会封装到HashMap$Node当中。
// HashMap 源码中的关键字段
transient Node<K,V>[] table; // 哈希桶数组,每个元素是链表的头节点或树的根节点下面是我们关于节点的定义:
// 链表节点(单向链表)
static class Node<K,V> implements Map.Entry<K,V> {
final int hash; // 哈希值(扰动后的哈希值)
final K key;
V value;
Node<K,V> next; // 指向下一个节点
}
// 红黑树节点(继承自 LinkedHashMap.Entry)
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {
TreeNode<K,V> parent; // 父节点
TreeNode<K,V> left; // 左子节点
TreeNode<K,V> right; // 右子节点
TreeNode<K,V> prev; // 前驱节点(删除时快速定位)
boolean red; // 颜色标记
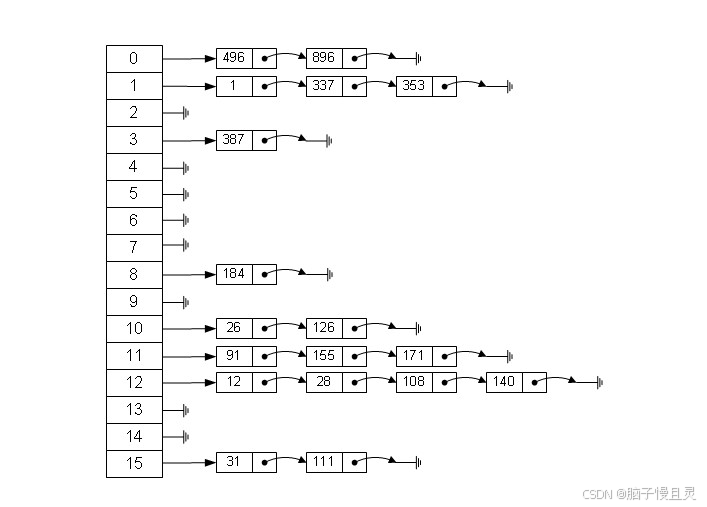
}2.底层扩容机制理解:
扩容触发条件
- 当元素数量超过
容量 × 负载因子(默认负载因子为 0.75)时触发扩容。 - 例如:默认初始容量 16,当元素数量超过 12(16 × 0.75)时扩容。
总结
提示:这里对文章进行总结:
以上就是我们今天要讲的内容,实际上这两个实现类很像,因为HashSet就是基于HashMap来实现的,只不过value是默认的固定虚拟对象,一个是存储唯一元素的无序集合,一个是存储键值对(Key-Value)的无序映射,我们还是要尽量去看看底层的代码来更好的理解
接下来我会开始更新算法题,要不天天都是拖着的,谢谢理解。

















 3347
3347

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









