



堆的基本认识
堆的概念
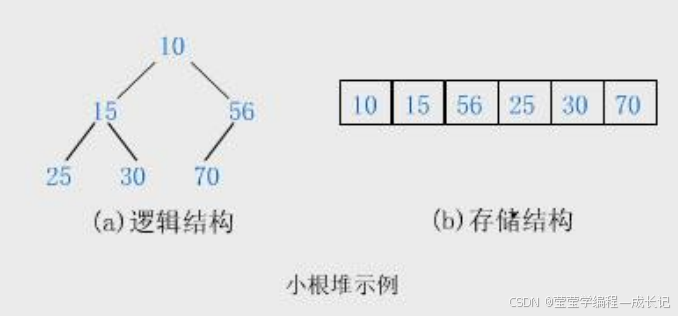
什么是堆?
1.堆总是一棵完全二叉树。
2.堆中某个结点的值总是不大于或不小于其父结点的值;
大堆和小堆:
大堆:1.完全二叉树
2.父亲节点的值>=孩子节点
3.根最大
小堆:1.完全二叉树
2.父亲节点的值<=孩子节点
3.根最小。

堆的定义:
typedef int HPDataType;
typedef struct Heap
{
HPDataType* a;
int size;
int capacity;
}HP;
堆的基本操作
1.堆插入数据
void HPPush(HP* php, HPDataType x)
{
assert(php);
//扩容
if (php->size == php->capacity)
{
int newcapacity = php->capacity == 0 ? 4 : php->capacity * 2;
HPDataType* tmp = (HPDataType*)realloc(php->a, newcapacity * sizeof(HPDataType));
if (tmp == NULL)
{
perror("realloc fail");
return;
}
php->a = tmp;
php->capacity = newcapacity;
}
//直接在size除插入数据
php->a[php->size] = x;
php->size++;
AdjustUp(php->a,php->size-1);//插入数据可能需要调整数据
}
2.向上调整(从某个孩子的位置向上调整)
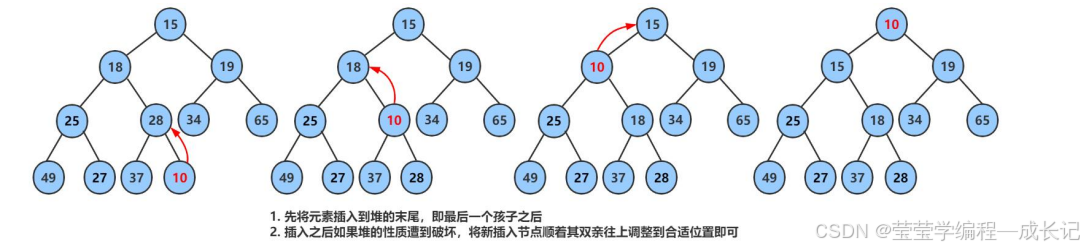
void AdjustUp(HPDataType* a, int child)
{
int parent = (child - 1) / 2;
while (child > 0)
{
if (a[child] < a[parent])//小堆:谁小谁当父亲
{
Swap(&a[child], &a[parent]);
child = parent;
parent = (child - 1) / 2;
}
else
{
break;
}
}
}
拓展:如果有一个数组,如何让它成为一个小堆?
void TestHeap1()
{
int a[] = { 4,2,8,1,5,6,9,7 };
HP hp;
HPInit(&hp);
for (size_t i = 0; i < sizeof(a) / sizeof(int); i++)
{
HPPush(&hp, a[i]);
}
}
int main()
{
TestHeap1();
return 0;
}
调试结果:

3.堆的删除:Pop删除,要求删除堆顶的数据(根位置)
首先,我们要清楚,挪动覆盖删除堆顶的数据,关系全乱了,父子变兄弟……
删除堆是删除堆顶的数据,将堆顶的数据根最后一个数据一换,然后删除数组最后一个数据,再进行向下调整算法。
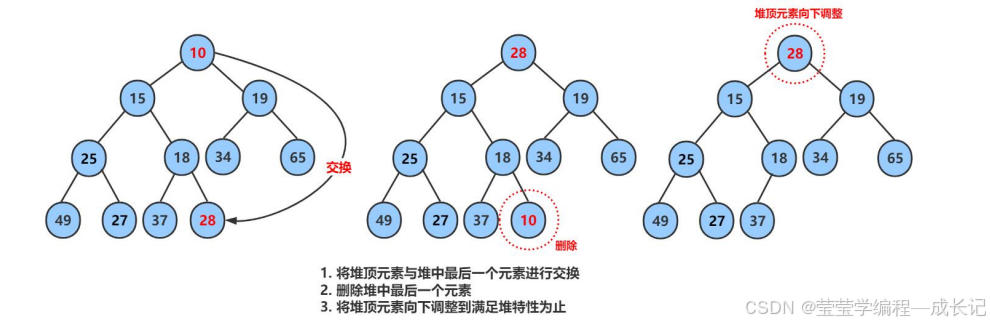
Pop删除
void HPPop(HP* php)
{
assert(php);
assert(php->size > 0);
Swap(&php->a[0], &php->a[php->size - 1]);
php->size--;
AdjustDown(php->a,php->size,0);
}
4.向下调整算法:
void AdjustDown(HPDataType* a, int n, int parent)
{
//要对比左,右孩子的大小
//假设左孩子小
int child = parent * 2 + 1;
//找出小的那个孩子
while (child < n)//chile>=n,越界了
{
if (child + 1<n && a[child + 1] < a[child])//右孩子也要n
{
++child;
}
if (a[child] < a[parent])
{
Swap(&a[child], &a[parent]);
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}
前面我们所说的,堆的删除是删除堆顶的数据,如果我们需要找出最大或者最小的前k个数据,我们就可以通过Pop数据,找出数据,就不需要通过排序来完成。
堆排序
建堆:
1)向上调整建堆:时间复杂度O(NlogN);
for (int i = 1; i < n; i++)
{
AdjustUp(a, i);
}
2)向下调整建堆:优点:时间复杂度O(N)
for (int i = (n - 1 - 1) / 2; i >= 0; i++)
{
AdjustDown(a, n, i);
}
升序建大堆
降序建小堆
堆排序代码:
void CHeap(int *a,int n)
{
//建堆(任选一个)
//向上调整算法
for (int i = 1; i < n; i++)
{
AdjustUp(a, i);
}
//向下调整算法
/*for (int i = (n - 1 - 1) / 2; i >= 0; i++)
{
AdjustDown(a, n, i);
}*/
int end = n - 1;
while (end > 0)
{
Swap(&a[0],&a[end]);
AdjustDown(a, end, 0);
--end;
}
}
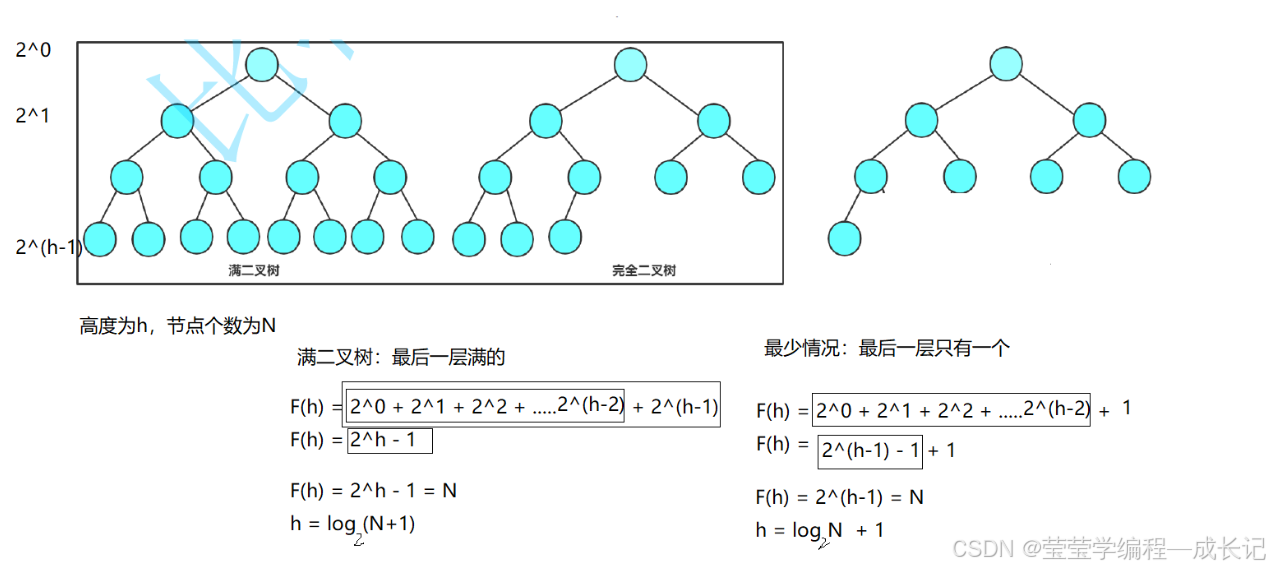
向上调整算法和向下调整算法的时间复杂度分析:
我们先分析满二叉树的时间复杂度范围:
由图可知,满二叉树的时间复杂度度就是O(logN);
拓展:满二叉树最后一排节点数占大约全部二叉树的一半。
向下调整算法的时间复杂度:
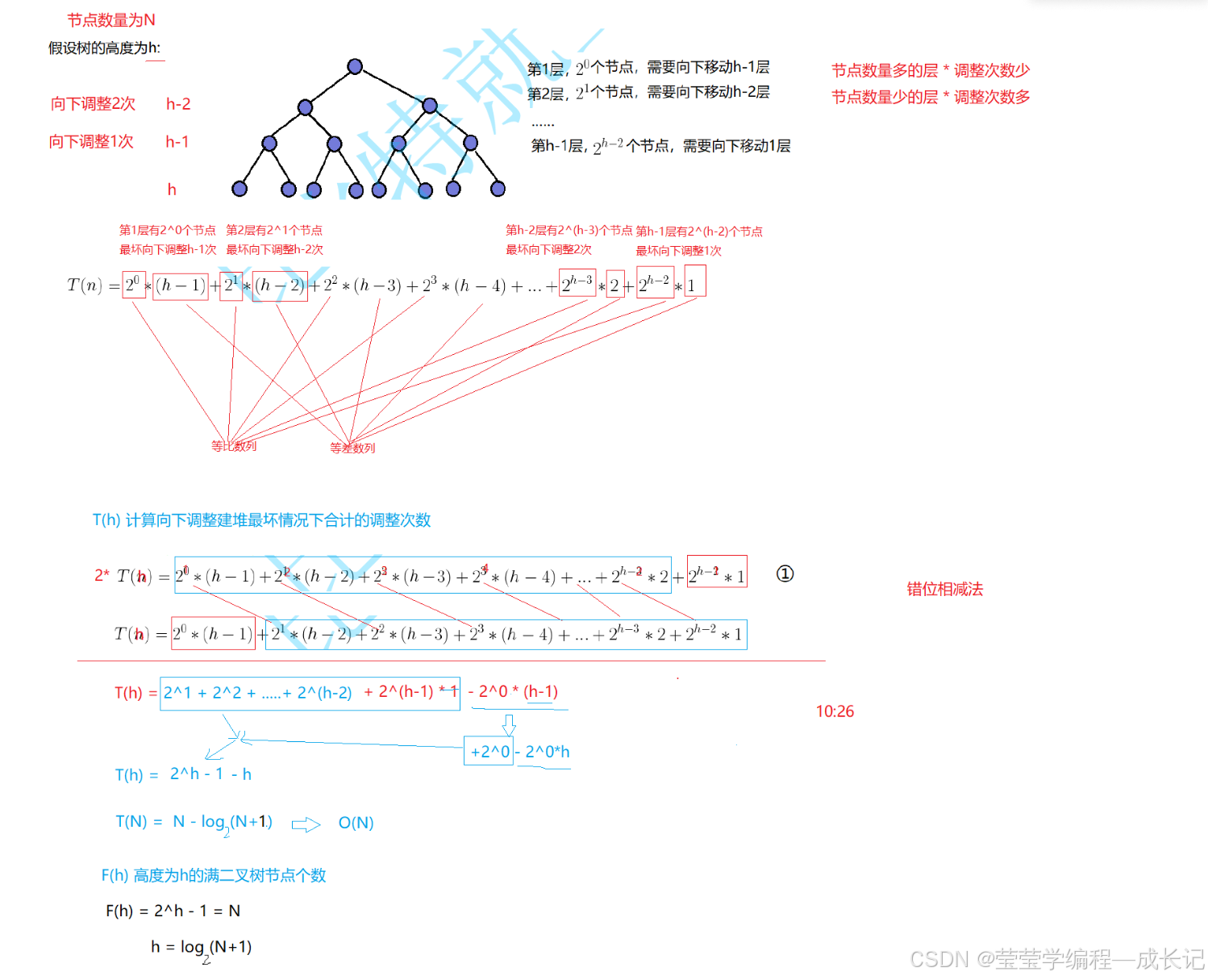
向下调整算法的特点:节点数量多的层 x 调整次数少
节点数量少的层 x 调整次数多
向上调整算法的时间复杂度:
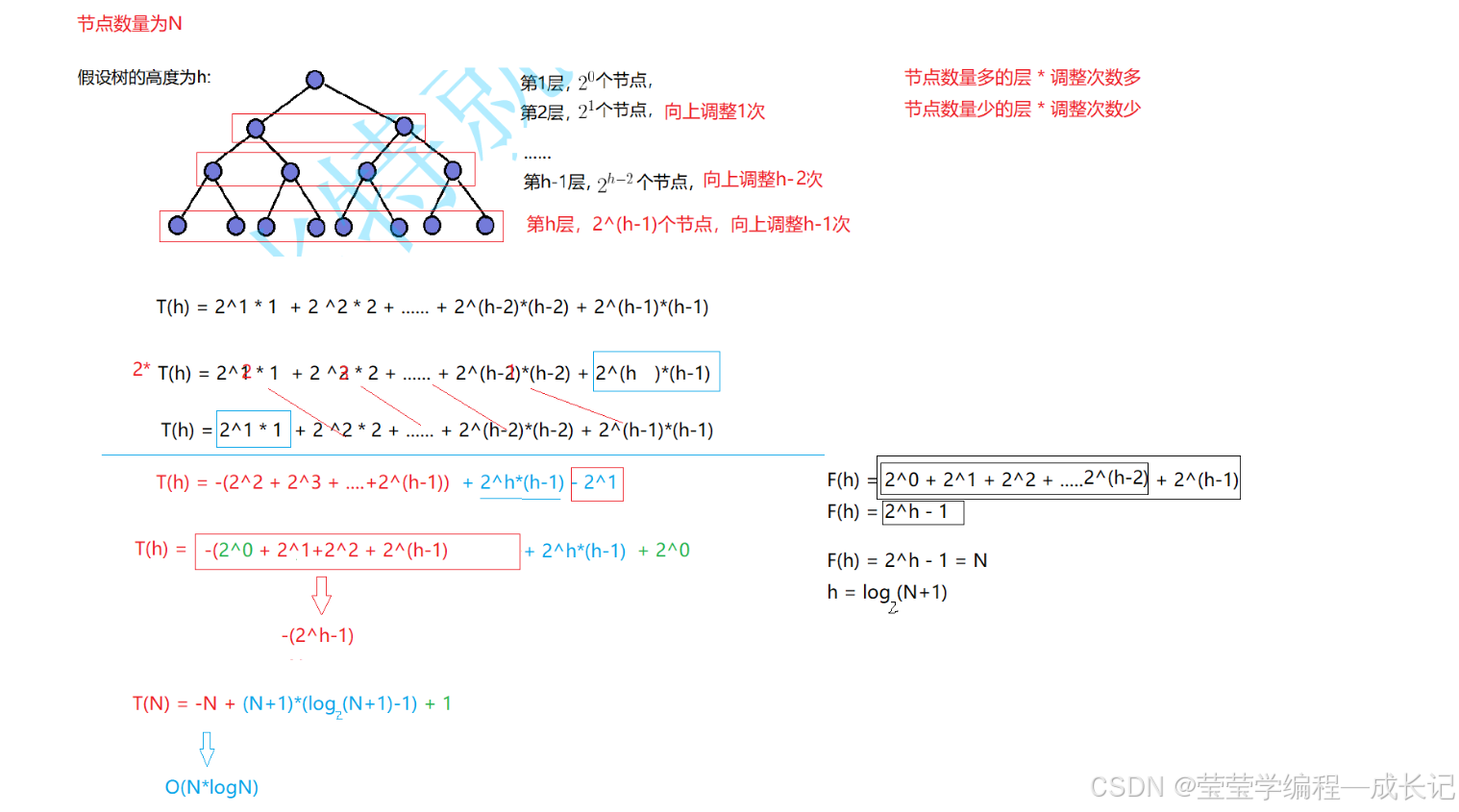
向上调整算法的特点:节点数量多的层 x 调整次数多
节点数量少的层 x 调整次数少
TOP-K问题:N个数找最大的前K个。
方法1:建一个N个数的大堆 ,再Pop k次
致命缺陷:如果N是10亿个整数,在这10亿个数里面找最大的前10个,我们知道,堆是在内存中开辟的,10亿个整数大概需要4G,太耗内存了。
方法2:用前k个数,建一个小堆,剩下数据跟堆顶数据比较,如果比堆顶数据大,就代替堆顶进入堆,(覆盖根位置,然后向下调整),这个小堆中的k个,就是最大的前k个。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









