




1.验证码涉及到的技术:
session: 的数据默认存储在服务器端,通常是在 服务器的内存(如 Tomcat 的 HttpSession 内存存储) 中,或者如果你使用了 分布式会话 方案,它可能会存储在 Redis、数据库或其他持久化存储 中。
默认情况下,Spring Boot 使用 Servlet 容器的 Session 机制(如 Tomcat 提供的 StandardSession)。默认过期时间是30分钟,可以在配置文件改。
什么时候会被清除?
Session 可能会在以下几种情况下被清除:
-
Session 过期:如果用户 长时间没有访问,超过超时时间(默认 30 分钟),Session 会自动失效。
-
手动清除:在代码中可以使用
session.invalidate()立即销毁 Session: -
服务器重启:如果服务器 没有启用分布式会话存储(如 Redis),重启后 Session 会丢失。
-
浏览器关闭(某些情况下):如果 Session ID 是通过 Cookie 传递,并且 Cookie 没有设置
max-age,那么当 浏览器关闭 时,Session ID 也会失效,从而导致 Session 无法找到。
2.邮箱验证码:
给一个邮箱发送验证码后会保存到redis中,防止重复发送。
发送下一个验证码前需要让上一个数据库验证码失效,之后再往数据库中插入数据。需要事物来保证。@Transaction
补充知识:
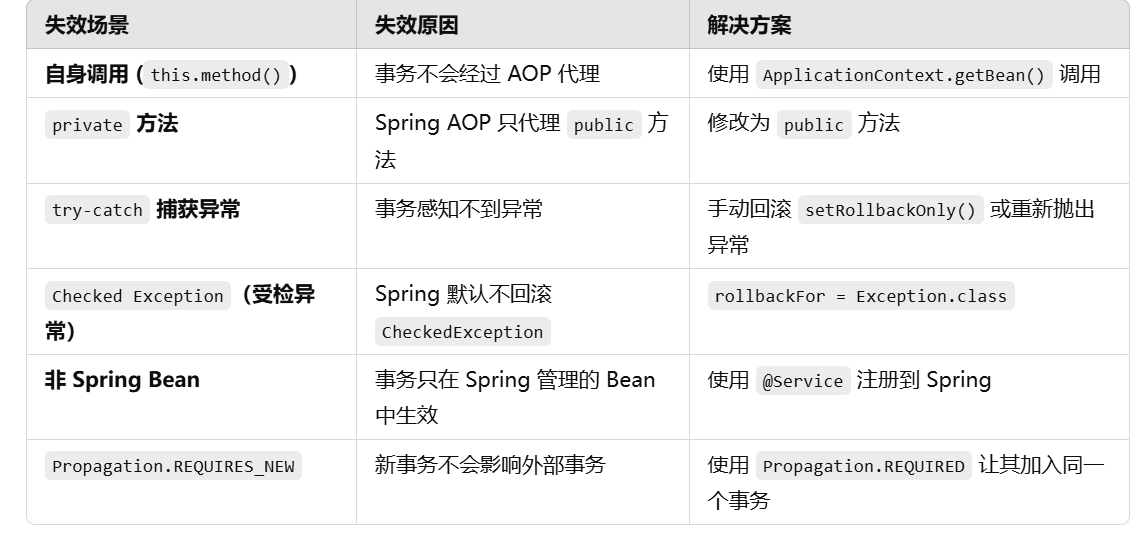
spring中事物失效的场景
因为事物是通过aop实现的,aop依赖动态代理,那么事物失效的本质就是动态代理失效(private),或者是动态代理没有失效但是没有走正常的逻辑(比如自己把异常捕获了,非受检异常)这种情况代理对象感知不到异常所以就没办法回滚。
发送验证码的主要代码:
MimeMessage message = javaMailSender.createMimeMessage();
MimeMessageHelper helper = new MimeMessageHelper(message, true)
//邮件发件人
helper.setFrom(appConfig.getSendUserName());
//邮件收件人 1或多个
helper.setTo(toEmail);3.注册接口:
校验邮箱是否存在、校验邮箱验证码(如果校验成功就讲验证码标记为失效(已使用))、保存用户基本信息(从redis获取容量)。
4.登录接口
执行流程:验证账号密码、更新最后一次登录时间、将用户的总空间和已使用空间存储到redis中、构建用户的基本信息、保存用户信息到session中。
说一下自己整理的session和cookie的思路:
当我们使用浏览器访问后端服务,后端会生成一个session和sessionid。Spring Boot 会在响应头里添加 Set-Cookie,让浏览器存储 JSESSIONID。接下来每次请求浏览器都会携带sessionid,后端服务器会自动拿着这个sessionid去帮我们找到他自己的session,然后我们再对session做一些校验。(也就是说设置和解析都是springboot帮我们做的,我们通过request拿到session对他做一些操作就可以啦)。

5.登录状态验证:
执行流程:当我们执行加了@GlobalInterceptor注解的方法,会使用aop来帮助我们进行登录校验和管理员校验,以及参数的校验。
本文中的登录状态管理使用的session,登录信息校验使用的是aop切面编程加上自定义注解的方式。
知识点回顾:
自定义注解:注解里面只能定义属性,只不过看起来像是一个方法。注解中的属性是用来给注解的使用者提供配置项的,类似于注解的“参数”。这些属性可以设置默认值,也可以在使用注解时指定值。
AOP:
在本项目中,切点使用的是自定义注解,注解是加载方法上的。
那么当spring容器启动的时候扫描到某一个类应用了我们定义的切点(自定义注解),那么就任务该类是需要被增强的,就会根据是否实现了接口(jdk、cglib)选择合适的动态代理方法。
spring容器会将原始的Bean对象替换为增强后的Bean对象,之后调用这个方法实际上调用的是增强后的方法。
- Spring 容器在启动时,会为被切面增强的 Bean 创建代理对象,并将该代理对象注册到容器中。
- 当你通过
@Autowired注入时,拿到的是代理对象,而非原始 对象。

6.参数校验
参数校验也是通过注解的方式,通过@Global..判断是否是要进行参数校验,参数校验分为两个类型(对象类型,基本类型),
基本类型:通过反射获取方法上的参数信息,判断参数上有没有加注解,加注解了要进行校验。
对象类型:如果某一个参数是对象,先通过反射获取对象,然后获取对象的属性,判断对象的属性上是否加了相应直接,如果加了注解,就进行校验。
7.加餐(限速上传实现):
思路:定义一个限速器,限速器里面可以自定义一个chunk( 每次读取的字节数到达Chunk那么就会进行限速判断),通过记录当前已经读取的字节数,上次读取chunk时间,当前时间,这几个进行判断,如果到达限速的时间就会sleep一段时间。接着把累计字节减去一个chunk,并更新上一次处理chunk的时间,进行循环判断。
我们项目中使用的时候,就使用自定义的限速InputStream;
特别注意:因为我们项目中使用了分片上传的方法,所以千万不要把chunk设置的太大,因为我们每一次前端上传的分片大小假设只有512kb,而我们把chunk设置为1MB,那么根本就限制不住。(血泪教训!!找bug找了三四个小时)!!
package com.easypan.utils;
import java.io.IOException;
import java.io.InputStream;
public class LimitInputStream extends InputStream {
private InputStream inputStream;
private BandwidthLimiter bandwidthLimiter;
public LimitInputStream(InputStream inputStream, BandwidthLimiter bandwidthLimiter) {
this.inputStream = inputStream;
this.bandwidthLimiter = bandwidthLimiter;
}
@Override
public int read() throws IOException {
//每次读取一个字节就进行判断是否限速
if (bandwidthLimiter != null) {
bandwidthLimiter.limitNextBytes();
}
return inputStream.read();
}
@Override
public int read(byte[] b, int off, int len) throws IOException {
每次读取len个字节就进行判断是否限速
if (bandwidthLimiter != null) {
bandwidthLimiter.limitNextBytes(len);
}
return inputStream.read(b, off, len);
}
@Override
public int read(byte[] b) throws IOException {
if (bandwidthLimiter != null && b.length > 0) {
bandwidthLimiter.limitNextBytes(b.length);
}
return inputStream.read(b);
}
}
8.日志管理:
本项目中使用的是logbcak和slf4j。
slf4j像是接口,而logback和log4j像是具体的实现类。不推荐直接使用logback和log4j,要配合slf4j进行使用。



在记录日志的时候,有两种方式
1.手动创建Logger实例(本项目中使用的方式)
private static final Logger logger = LoggerFactory.getLogger(ABaseController.class);
2.@Slf4j注解(Lombok提供),编译时通过Lombok自动生成Logger字段
lombook是什么?
Lombok 是一个 Java 库,通过注解的方式在编译时自动生成代码,主要用来减少 Java 开发中的样板代码(boilerplate code),让代码更加简洁。
比如我们常用的@Data,@Getter/@Setter,@Slf4j等。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









