



简介
本文所介绍的VQA模型是一种最简单的VQA多模态交互模型。模型的关键点在于提取图像特征(Image_feature)和文本的特征(qst_feature),然后通过逐元素乘法将两种模态的特征融合到一起。这是一种早期的模态融合方法。
欢迎对多模态感兴趣的朋友来互相学习讨论~
原理
1.Model示意图
图画的不好,还请见谅,下面的具体模型部分会再次讲解。

Fig1:模型示意图
2.图像特征提取部分
Step1:假设训练样本的一张图像是[3,224,224]的,也就是一张图像有三个通道,图像的长和宽均为224,则训练样本为:x = [batch_size,3,224,224]。
Step2:然后经过一个预训练好的VGG19的feature部分(预训练好的vgg分为三个部分,feature部分、avgpool部分、classifier部分。如没特殊声明,后面的VGG19说的都是VGG19的feature部分)。
则经过VGG19后得到的特征为:Features = VGG19(x),其中Features的size为:[batch_size,512,7,7]。
Step3:然后再将Feature经过一些变换(这里做的是展平处理)变成[batch_size,512*7*7],然后再经过一个线性层得到image_feature,其中Image_feature的size为:[batch_size,1024]。
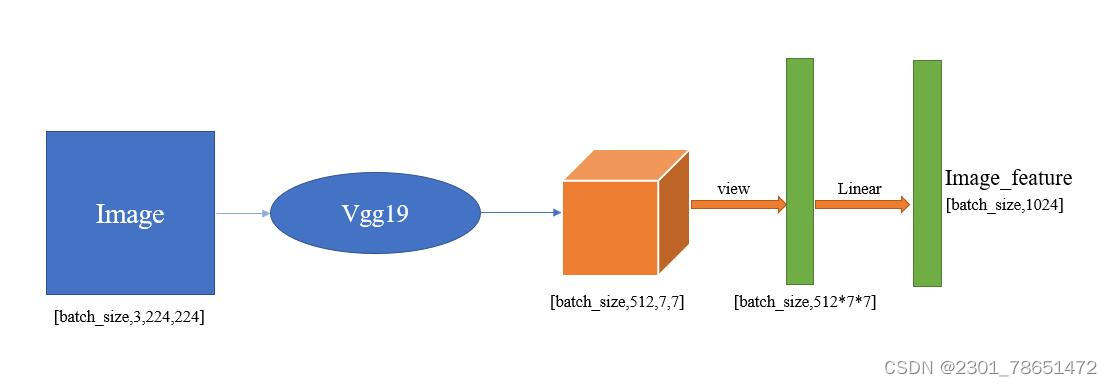
Fig2:图像特征提取示意图
3.文本特征提取部分
Step0:文本部分首先需要将文本映射为向量,这里采用的还是最简单的独热编码来映射。
假设有一句和图像相关的问题:“图像中的小孩穿的什么颜色衣服”。那么我们需要把这句话先编码为一个向量,需要做的是先分词(分词工具可以自行选择一些流行的即可),假设分词后的问题变成:“图像/中/的/小孩/穿/的/什么/颜色/衣服”。然后去vocab里面查询每个词出现的频率,然后为每个词赋予独热编码表示。
Step1:将独热编码的向量进行词嵌入操作。
假设上面那句话经过独热编码后变成了",
",其中每个
代表了一个词,然后
是一个独热编码的向量。
下面的操作就是进行词嵌入,其实非常简单,就是用一个词嵌入矩阵,将每个映射为一个更好的向量。具体来说就是
,得到词嵌入向量。则
Step2:将词嵌入后的向量按顺序依次送入到LSTM层,然后拿到LSTM层的最后一个隐层状态,作为问题的向量表示:qst_feature 。其中qst_feature的size为:[batch_size,1024]。
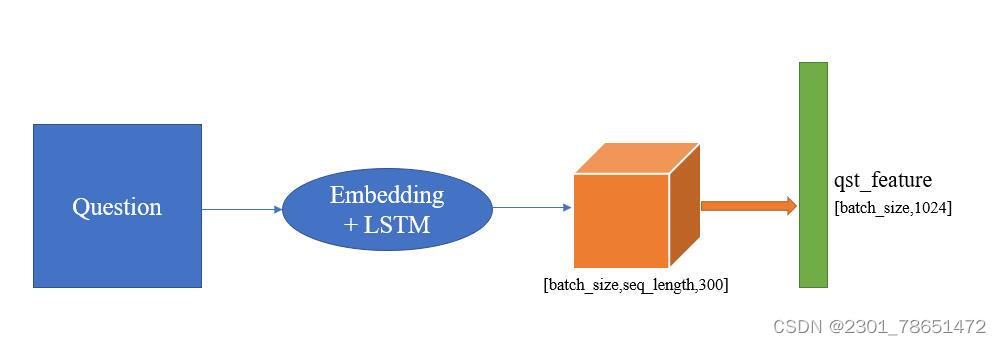
Fig3:文本特征提取示意图
4.模态融合
因为我们图像特征和文本特征最后都是[batch_size,1024]的大小,所以我们可以直接将Image_feature和qst_feature进行乘法,得到融合后的特征向量。
当然这是一种早期的做法,虽然我们现在早已经不用这种粗暴的方式来做特征融合,但是刚刚入门,我觉得还是从最基础的地方来会更容易上手一些。
代码
1.图像特征提取的代码
import torch
import torch.nn as nn
from torchvision import models
class ImageEncoder(nn.Module):
def __init__(self,embed_size):#这里的embed_size就是上面原理说的1024
super(ImageEncoder,self).__init__()
"""
The purpose of the class image encoder is to get the feature vector of the image
"""
vgg19 = models.vgg19(pretrained=True).feature#加载预训练vgg19模型的feature部分
self.cnn = vgg19
self.fc1 = nn.Linear(512*7*7,4096)#这里为了过拟合,所以加一个线性层
self.fc2 = nn.Linear(4096,embed_size)
self.fl = nn.Flatten()
def forward(self,img):
with torch.no_grad():#这里做的目的是为了冻结住vgg19特征提取部分的参数
features = self.cnn(img) #[batch_size,512,7,7]
features = self.fl(features) #展平处理 [batch_size,512*7*7]
features = self.fc1(features) #[batch_size,4096]
img_feature = self.fc2(features) #[batch_size,embed_size=1024]
return img_feature2.问题特征提取的代码
class QuestionEncoder(nn.Module):
"""
The purpose of the class QuestionEncoder is to get vector of the problem
"""
def __init__(self,qst_vocab_size,word_embed_size,embed_size,num_layers,hidden_size):
super(QuestionEncoder,self).__init__()
self.embedding = nn.Embedding(qst_vocab_size,word_embed_size)
#Uniform distributed initialization of the parameters of the word embedding layer
nn.init.xavier_uniform_(self.embedding.weight)
self.tanh = nn.Tanh()
self.lstm = nn.LSTM(word_embed_size,hidden_size,num_layers)
self.fc = nn.Linear(2*num_layers*hidden_size,embed_size)
def forward(self,question):
#Encoding incoming question as word vector
qst_vec = self.embedding(question) #[batch_size,max_qst_length,word_embed_size=300]
qst_vec = qst_vec.transpose(0,1) #[max_qst_length,batch_size,word_embed_size]
_,(hidden,cell) = self.lstm(qst_vec)
qst_feature = torch.cat((hidden,cell),2)
qst_feature = qst_feature.transpose(0,1)
qst_feature = qst_feature.reshape(qst_feature.size()[0],-1)
qst_feature = self.tanh(qst_feature)
qst_feature = self.fc(qst_feature)
return qst_feature3.融合代码
class VqaModel(nn.Module):
"""
The purpose of the class VqaModel is to fusion feature of v and q . Then to make classification
"""
def __init__(self,embed_size,qst_vocab_size,ans_vocab_size,word_embed_size,num_layers,hidden_size):
super(VqaModel,self).__init__()
self.img_encoder = ImageEncoder(embed_size)
self.qst_encoder = QuestionEncoder(qst_vocab_size,word_embed_size,embed_size,num_layers,hidden_size)
self.tanh = nn.Tanh()
self.dropout = nn.Dropout(0.3)
self.fc1 = nn.Linear(embed_size,ans_vocab_size)
self.fc2 = nn.Linear(ans_vocab_size,ans_vocab_size)
def forward(self,img,qst):
img_feature = self.img_encoder(img) #[batch_size,embed_size]
qst_feature = self.qst_encoder(qst) #[batch_size,embed_size]
fusion_feature = torch.mul(img_feature,qst_feature) #[batch_size,embed_size]
fusion_feature = self.tanh(fusion_feature)
fusion_feature = self.dropout(fusion_feature)
fusion_feature = self.tanh(self.fc1(fusion_feature))
fusion_feature = self.dropout(fusion_feature)
y = self.fc2(fusion_feature)
return y讲在最后
这个模型应该是我们学习VQA领域想到的第一个模型,首先它是一个非常简单的将图像特征和文本特征做了个乘法。但是有一个问题,就是文本向量和图像向量之间没有交互,从而导致没有融合到更多的信息。因此我们带着这个问题,会进入下一篇论文,期待下一期继续和小伙伴们一起学习~
制作不易,如果本文对你有帮助的话,那就点个赞和关注吧~~

















 754
754

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









