



目录
本文主要介绍 MySQL 中 InnoDB 存储引擎如何组织存储数据到磁盘当中;
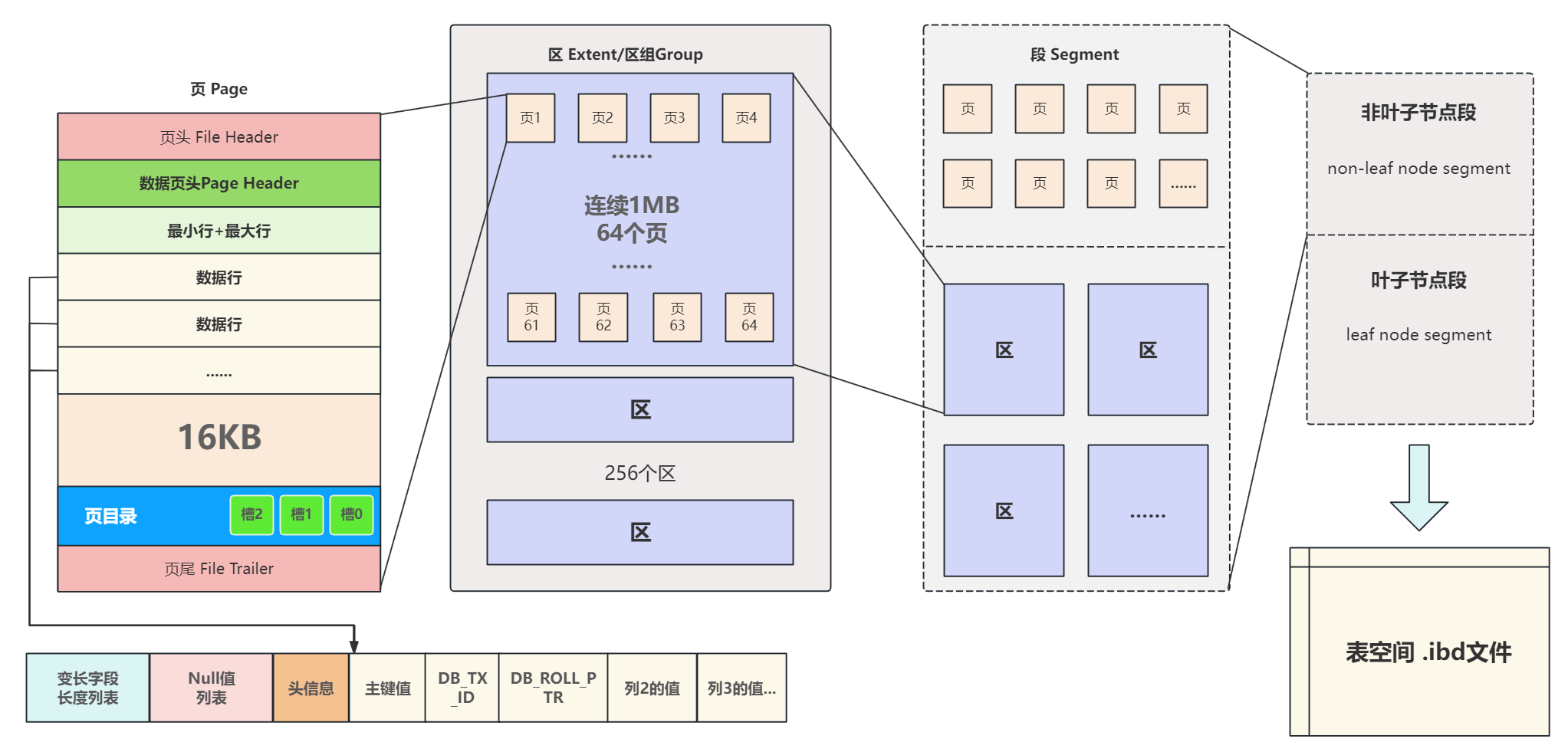
MySQL存储结构主要分为一下几个模块:数据行、数据页、区、区组、段以及表空间;
整体架构:
1. 数据行
数据行主要用于保存用户数据,一条数据对应一个数据行;
如下图:数据行主要分为两大部分,真实数据区和额外信息区;
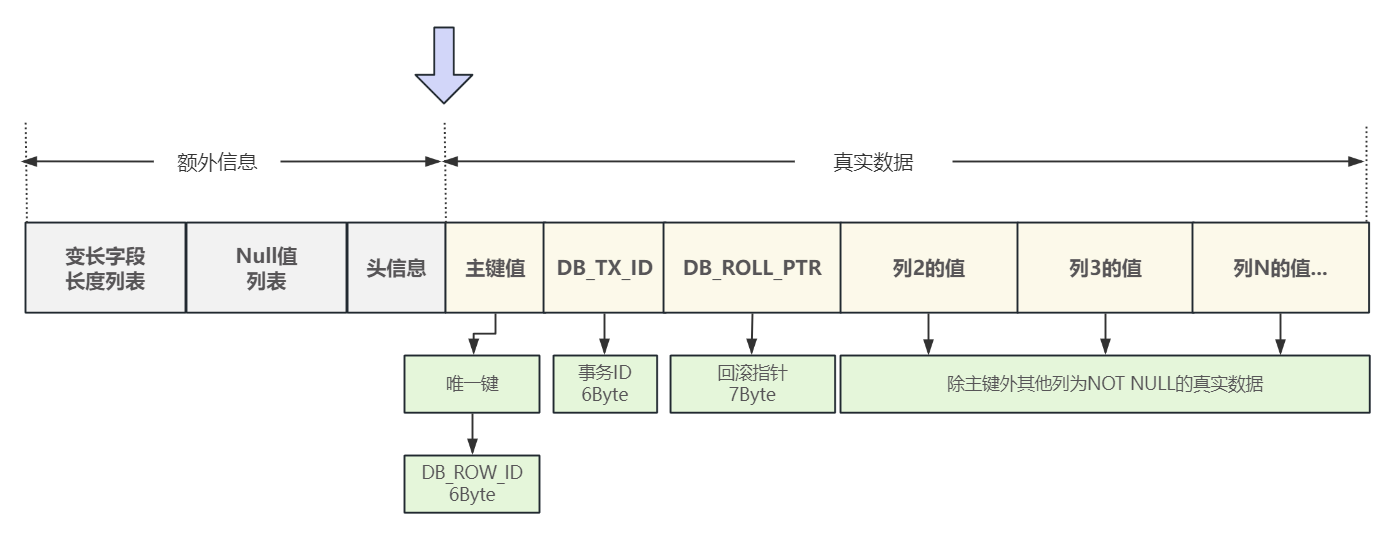
真实数据区存储:主键值、事务的ID、回滚指针(指向undo log)、用户的数据;
额外信息区:变长字段列表、null值列表、头信息;
变长字段长度列表
MySQL中的数据类型包含变长字段类型,比如:varchar、varbinary、text、blob;
由于数据行中的数据是连续存储的,那么为了便于可变长度列的数据读取(列与列之间数据切分读取),以及空间的高效利用,便有了变长字段列表;
每个变长字段分配1~2个字节来存放这些字段的真实大小,放置顺序也是按表中字段的顺序从右至左逆序排列;
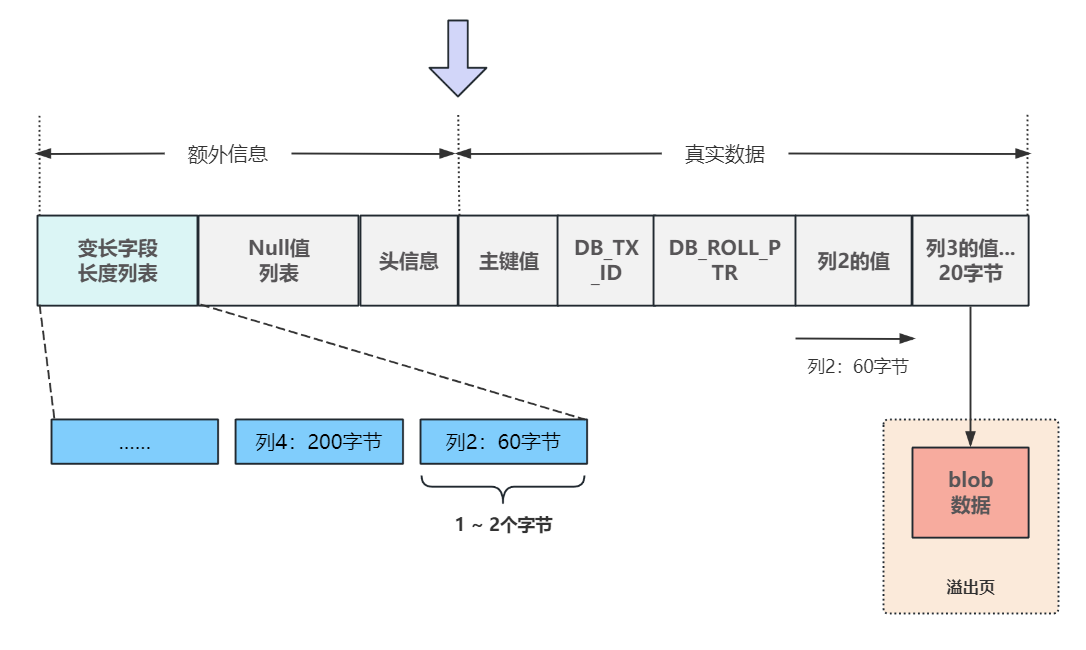
2个字节最大可以表示 65535 个字节,按照最大长度字符串计算,比如:utf8mb4,⼀个字符占用最多4个字节,2个字节最多可以表示 65535/4=16383 个字符,列数据类型varchar的长度上限16383就是根据这个计算来的;
注意:如果text、blob存储的内容过大,一个页已经不够放了,就会把这个列放入一个叫 "溢出页" 的独立间中,在这个数据行对应的真实数据处,只使用 20 个字节来标记这个溢出页的位置信息;
在InnoDB中规定,一个数据页最少存放两个数据行,默认数据页大小16KB,那么一个数据行最大8KB;
如何读取数据?
- 在任何时候都是先读⼀个字节,然后判断这个字节的高位是否为0,如果是0则表示当前用⼀个字节 表示长度,如果是1则表示当前用两个字节表示长度;
- 为1时再读⼀个字节,然后合并在⼀起进行解析得到该字段真实的使用的字节数,而且第二个BIT位 表示是否使用溢出页;
Null值列表
Null 值列表主要来存储数据行中所有列允许为Null 的值从而节省空间,具体的实现方式:用1BIT的大小来表示行中某⼀列是否为空;
对于没有定义 NOT NULL 约束列,也就是可以为 NULL 的列在 NULL值列表中安排了⼀个bit位,按列序号从小到大的顺序从右至左依序安排;
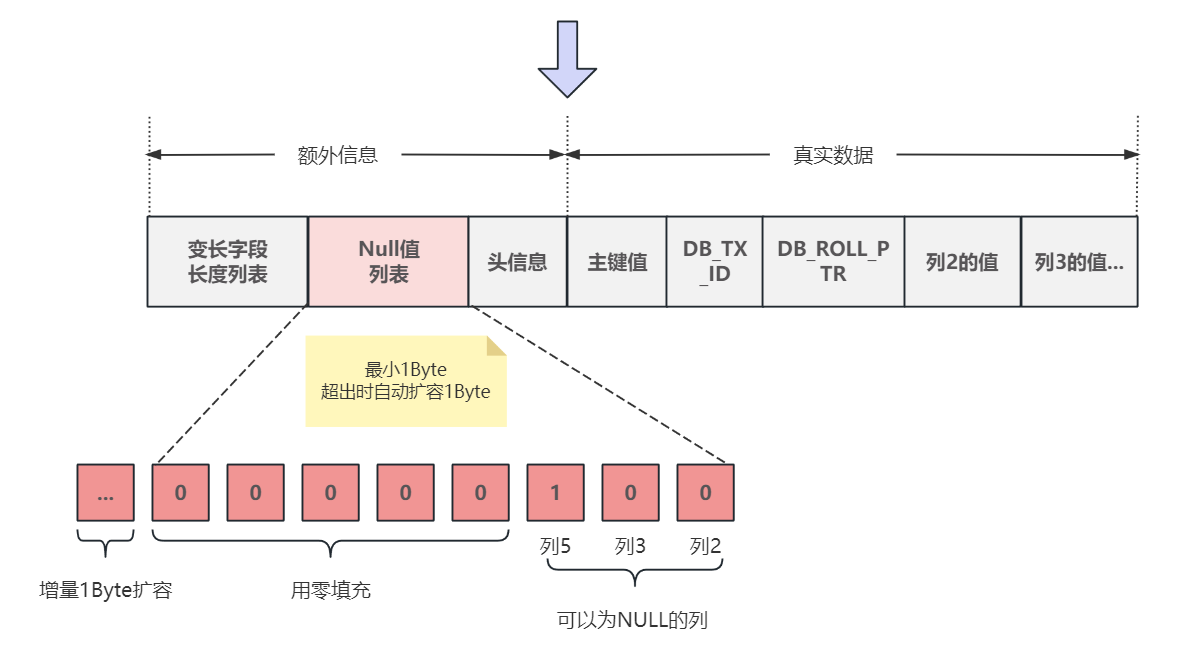
如果某列为空,则 NULL 值列表中对应的bit设置为1,这样只用了1 bit 就存储了NULL列,非常节省空间;
头部信息
头信息区域 固定占5Byte即40个Bit;结构如下:
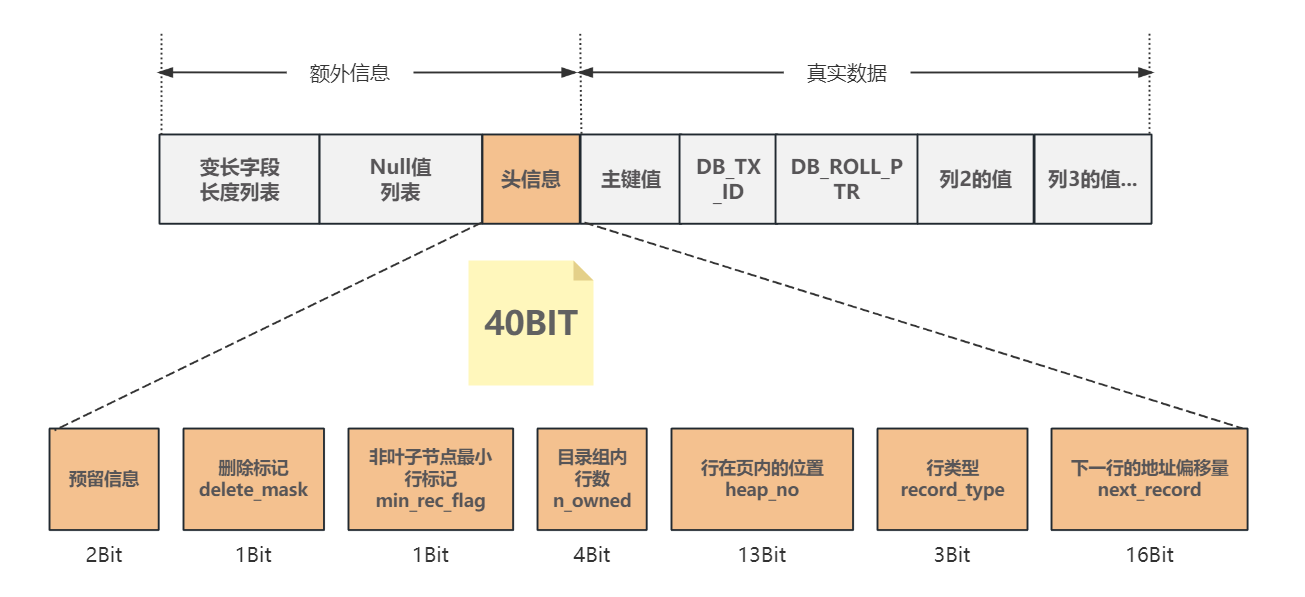
下一行地址偏移量: next_record 占16bit,通过这个信息将所有的行链接成⼀个单向链表;
行类型: record_type 占3bit,包括四种类型:
- 0:普通数据行
- 1:索引目录行
- 2:页内最小行 infimun
- 3:页内最大行 supremun
分组的行数: n_owned 占4bit,只在该行是分组最后⼀行才有值,这样就可以快速查询分组内的行数,而不用⼀条条的累加;
删除标记: delete_mask 占 1bit ,从页中删除数据行时,并不会直接移除,而是修改这个删除标记为 1;
2. 数据页
数据页默认为 16KB ,是操作系统"数据块" 4KB的整数倍,只要保证页的大小 是操作系统 "数据块" 大小的整数倍就可以;可以通过系统变量 innodb_page_size 进行调整与查看;
数据页整体结构:
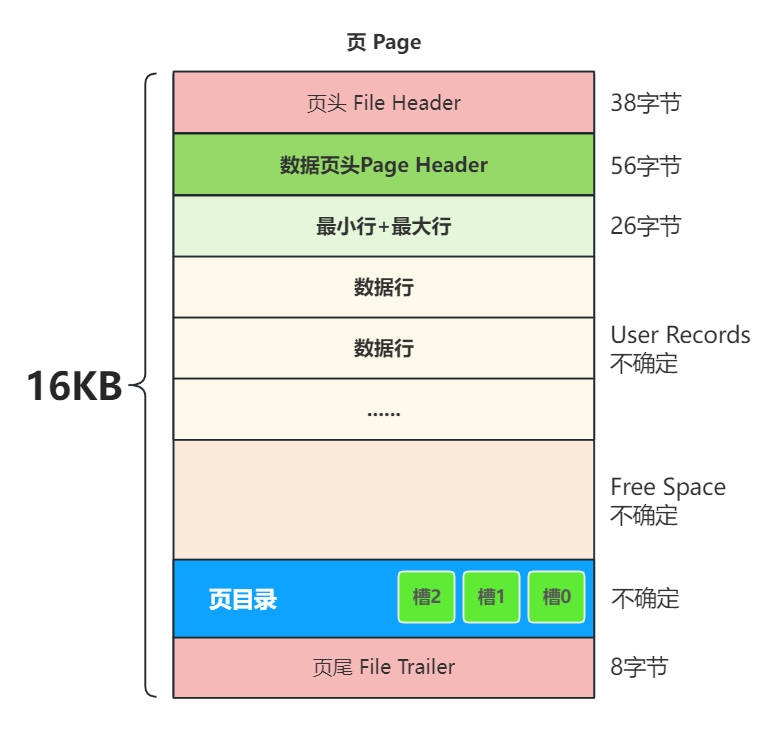
包含:页头、页尾、数据页头、最大行和最小行、数据行以及页目录;
页头和页尾
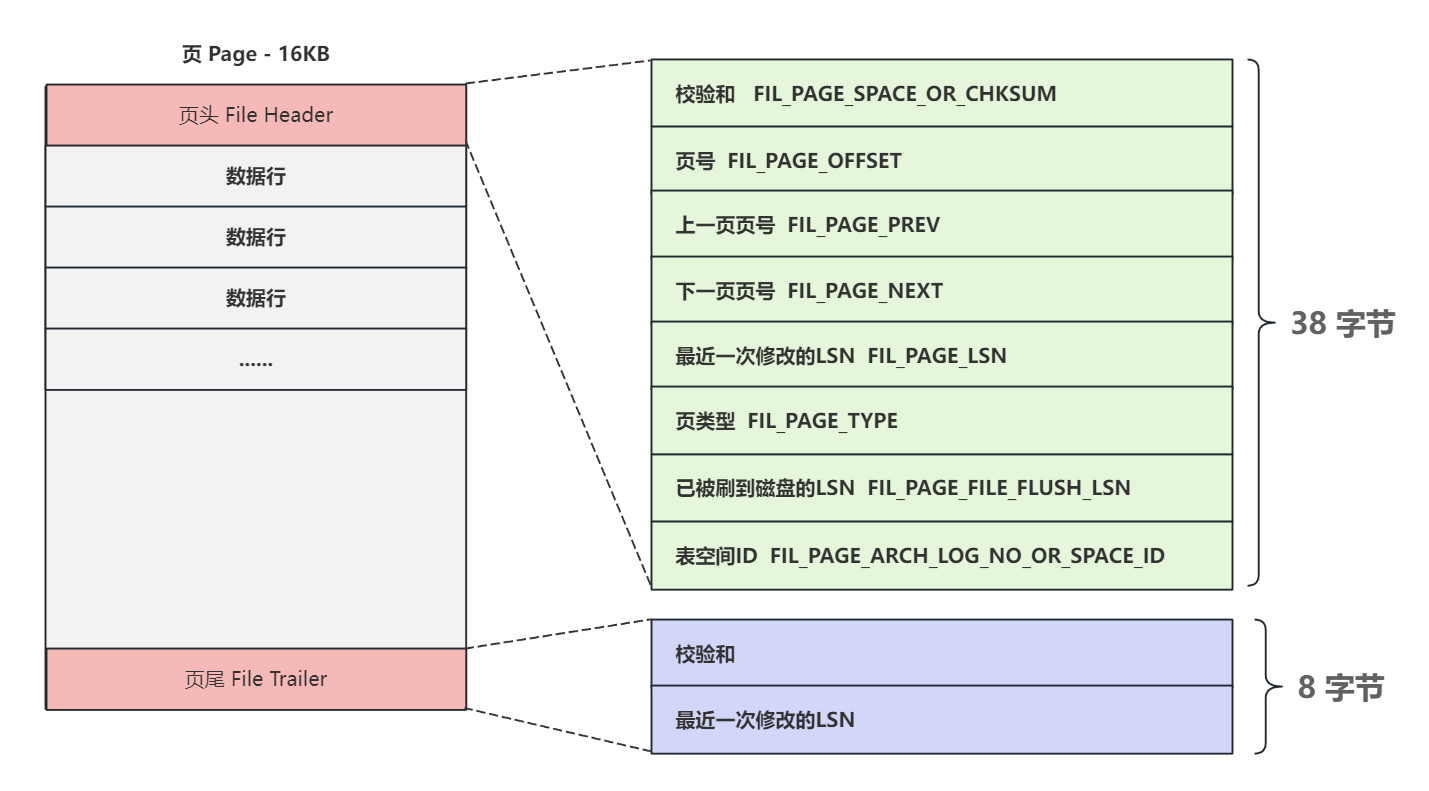
页号: 相当于数据页的身份证号,表空间第⼀个页编号从0开始,之后的页号 分别是1,2,3…依此类推,具体页的偏移量计算公式为:页号 * 每页大小;那么按照每个页默认 16KB大小计算,一个表空间最大容量为 2^(4*8) * 16KB = 64TB ,这也是InnoDB表空间最大容量是64T的原因;
上⼀页页号和下⼀页页号: 多个页通过这两个信息组成双向链表,即使不同的页地址不连续,也可以通过链表连接;
校验和:用于页的完整性校验;
页类型: InnoDB在不同的使用场景定义多种不同类型的页,常用的有:数据页 、Undo Log页 、 Change Buffer页 、 Extent Descriptor(XDES)页 、 InnoDB段信息页等,这里只讨论数据页;
表空间ID: 当前页属于哪个表空间;
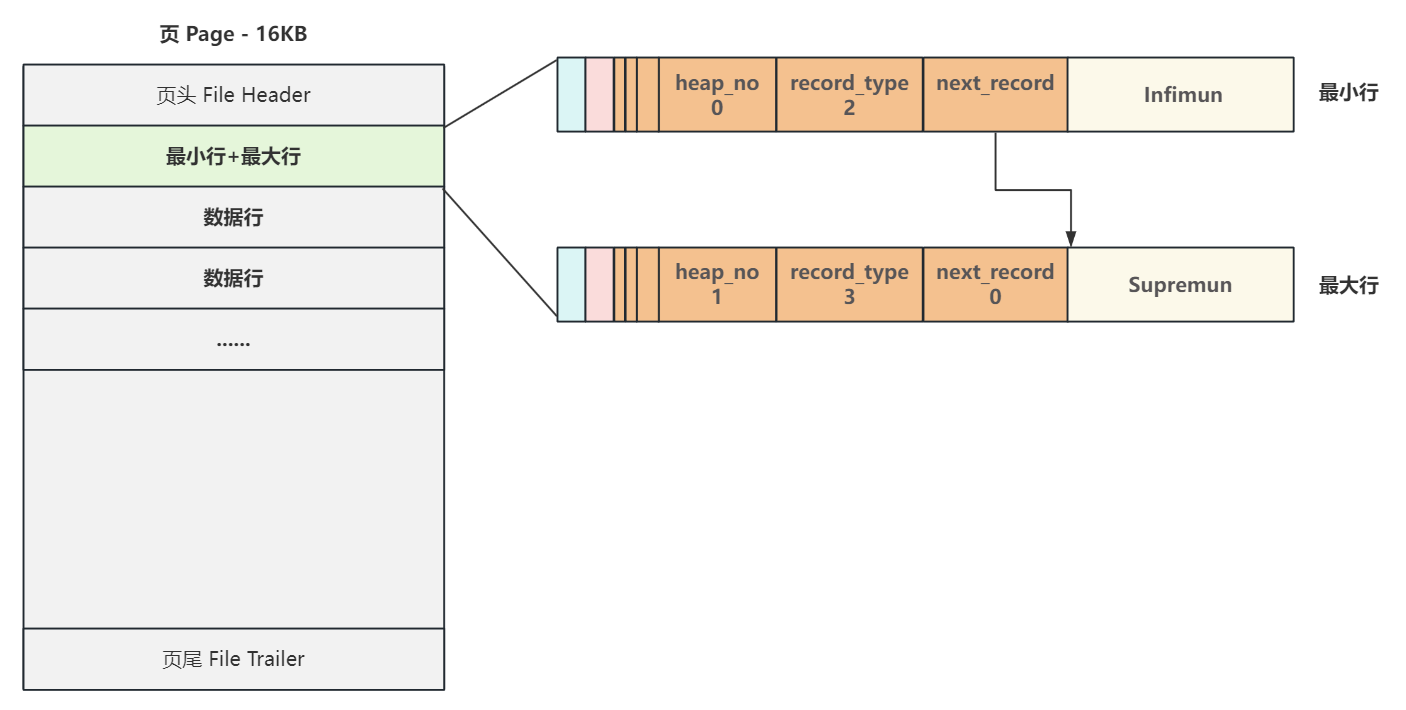
最大行和最小行
用于 标识新页中的第一行 和最后一行;当遍历页中的行时,标识从哪⾥开始到哪⾥结束;
每当创建⼀个新页,都会自动分配两个行,一个是行类型为2的最小行 Infimun ,heap_no 位置固定为0号,和⼀个是行类型为3的最大行 Supremun , heap_no 位置固定为1 号,这两个行并不存储任何真实信息,而是做为数据行链表的头和尾,虽然不存储真实数据,但它们的数据结构和真实数据行完全⼀致,只不过数据区域存储的是代表它们身份的固定字符串 Infimun 和 Supremun ,新页中没有数据时,最小行 Infimun 的 next_record 直接连接 最大行 Supremun ,最大行不连接任何行,它的 next_record 为0;
页目录
一个数据页16KB,通常会存在数百行数据,在查找数据页中的某一行数据时怎么查找?遍历?
显然之间遍历效率并不高;如何提高页内的查询效率?页目录
在每⼀个页中加⼊⼀个叫做页目录 Page Directory 的结构,将页内包括头 行、尾行在内的所有行进行分组,约定头行单独为⼀组,其他每个组最多8条数据,同时把每个组 最后一行在页中的地址,按主键从小到大的顺序记录在页目录中在,页目录中的每⼀个位置称为一 个槽,每个槽都对应了一个分组,这样在插⼊数据行完成链接后,⼀旦最后⼀个分组中的数据行超 过分组的上限8个时,就会分裂出⼀个新的分组,为了快速判断每个分组是否达到了8个的上限,在 每个分组最后⼀行中用 n_owned 记录了这个分组内的行数,与此同时在页目录中创建⼀个新的槽,后续插入的行都遵守这个规则;
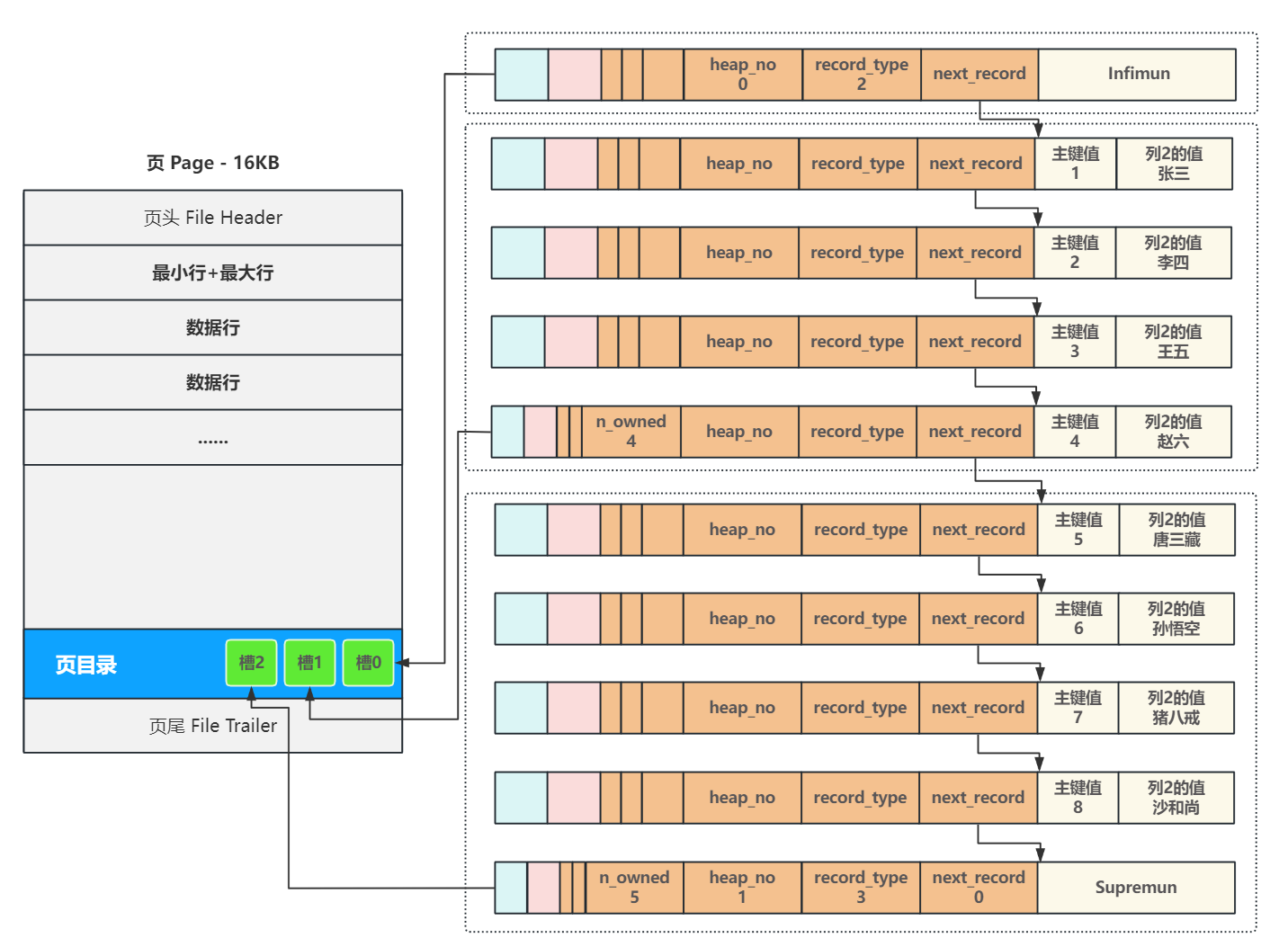
为了提高查询效率,InnoDB采用二分查找来解决查询效率问题。
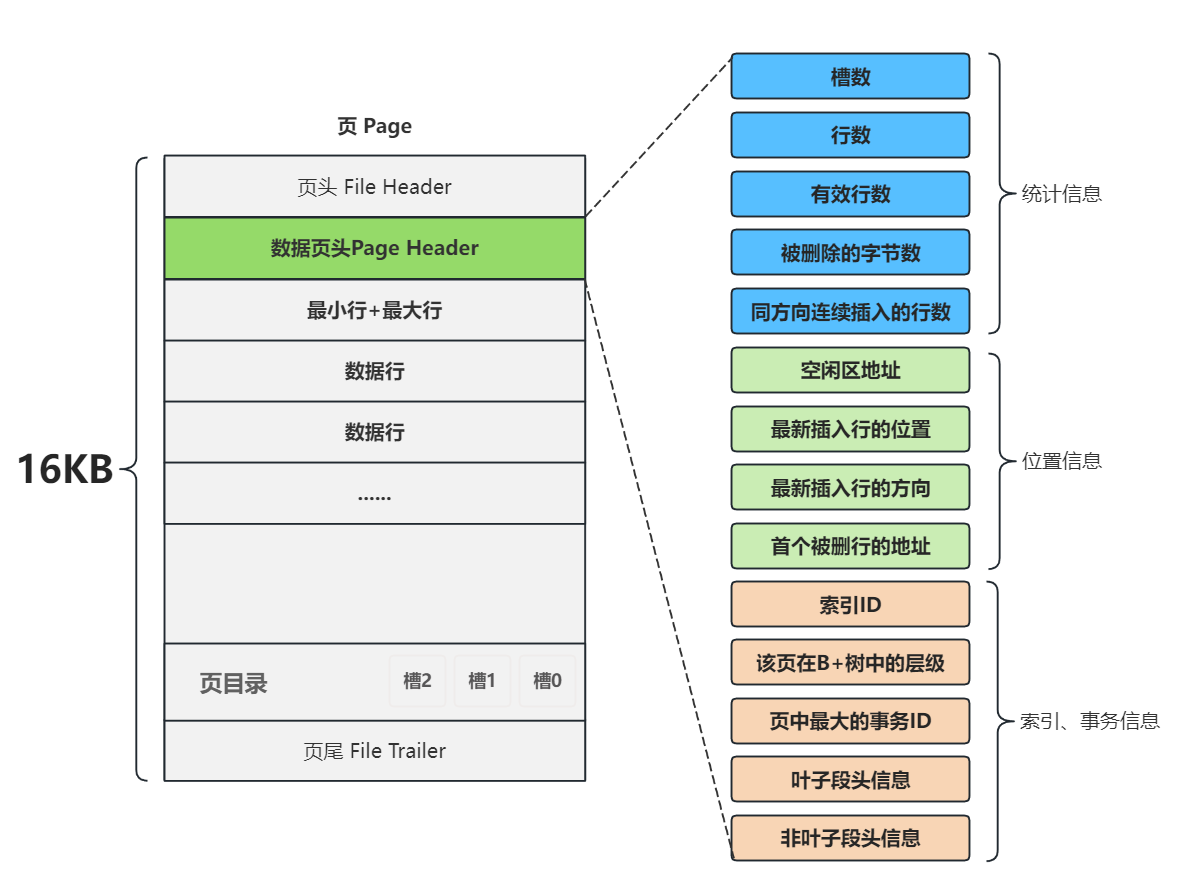
数据页头
索引和事务相关信息怎么存储?
索引和事务信息都存在数据页头中,此外数据页头还存储页内的统计信息、页中的位置信息;
-
索引ID (INDEX_ID):标识这个数据页属于哪个索引。在一个表中,除了主键索引(聚簇索引),还可能存在多个二级索引(辅助索引)。这个ID确保了数据库能准确地将页面与特定的索引关联起来,在进行索引扫描或维护时不会出错。
-
该页在B+树中的层级 (PAGE_LEVEL):这是最关键的字段,它直接定义了该页在B+树结构中的位置(高度),从而决定了页的类型(叶子节点还是非叶子节点)。
-
页中最大的事务ID (PAGE_MAX_TRX_ID):服务于MySQL的MVCC(多版本并发控制)机制。该字段记录了最近修改过此页中数据的一个最大事务ID。当一个事务要读取该页的数据时,会将自己的ID与此值以及系统中的其他信息进行比对,用以判断该页中的数据行对自己是否“可见”(例如,是否是在本事务开始之后才被修改的),从而决定是读取当前版本的数据还是回滚段中的旧版本数据,以实现可重复读(Repeatable Read)等隔离级别。
-
叶子段头信息 (PAGE_BTR_SEG_LEAF) 与 非叶子段头信息 (PAGE_BTR_SEG_TOP):这些是InnoDB存储引擎内部用于管理“索引段”的信息。段是比页更大的存储结构,一个索引由两个段组成:内部节点段(非叶子节点段)和叶子节点段。这些头信息包含了该段所管理的页的链表信息,方便引擎快速定位和扩展索引结构。
如何区分是非叶子节点页还是叶子节点页?
区分方法非常简单直接,就是通过查看 “该页在B+树中的层级 (PAGE_LEVEL)” 这个字段的值。
-
叶子节点页 (Leaf Page):
-
特征:
PAGE_LEVEL = 0 -
内容:这种页位于B+树的最底层。它不存储指针,而是直接存储数据行的实际内容(对于聚簇索引)或索引列值 + 主键值(对于二级索引)。
-
-
非叶子节点页 (Non-Leaf Page / Internal Page):
-
特征:
PAGE_LEVEL >= 1(层级数字越大,越靠近根节点) -
内容:这种页不存储实际的数据行,而是作为索引的导航目录。它存储的是“键值 + 指针”(这里的指针通常是子页的页号),数据库引擎通过比较查找的键值和这些索引项,可以快速定位到下一个层级的页,最终找到目标数据所在的叶子节点页。
-
3. 区
区的作用是为了减少磁盘的随机访问,用区来组织页;区的固定大小1 MB,管理64个页,这些页在磁盘中存储时是连续的;连续存储可以提高磁盘IO的效率;
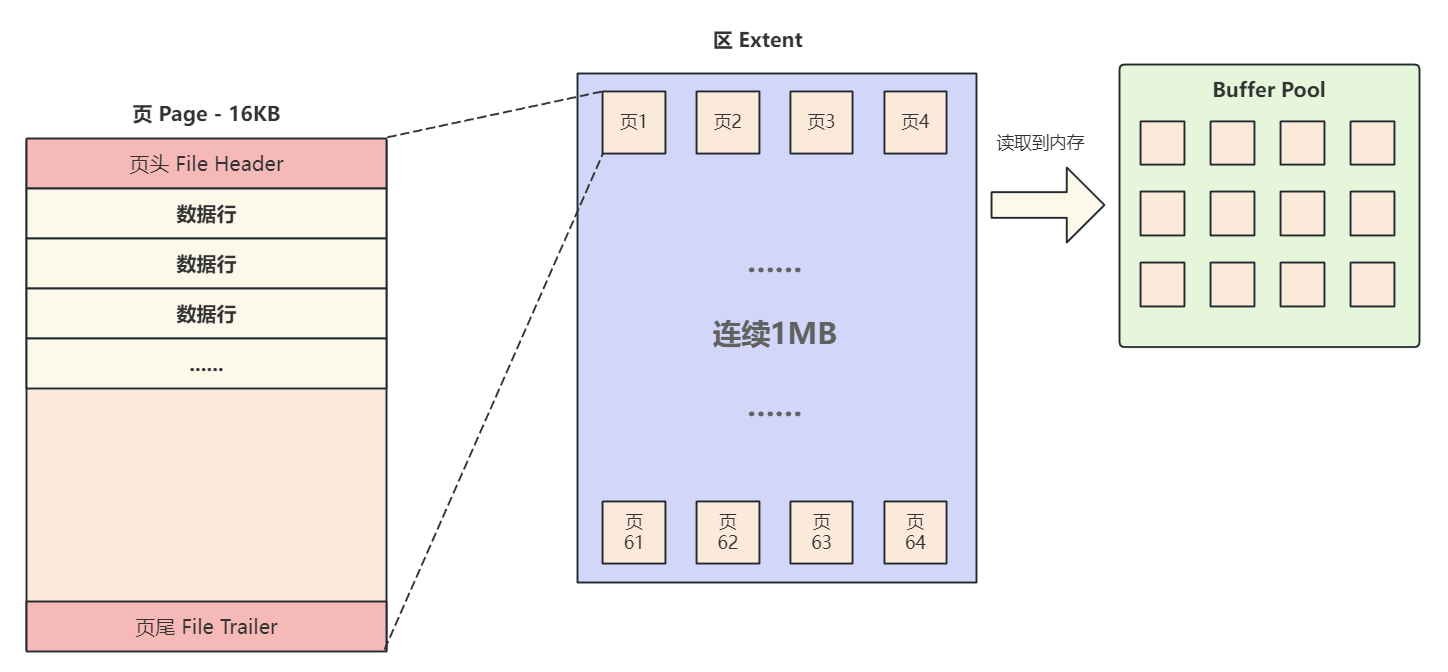
新创建表时没有数据,或者说有的表只有很少的数据,1MB的空间用不 完,那不是就存在空间浪费的问题吗?
表数据少时不会创建一个区,而是创建7个初始页,并保存到碎片区,碎片区达到32个页后申请一个完整的区;
4. 区组
如果访问的数据跨区了怎么办?不同的区在磁盘上大概率是不连续的;区组
使用区组结构有效的管理区,每个区组固定管理256个区即 256MB ,区组条目信息中会记录每个 区的偏移并用双向链表连接。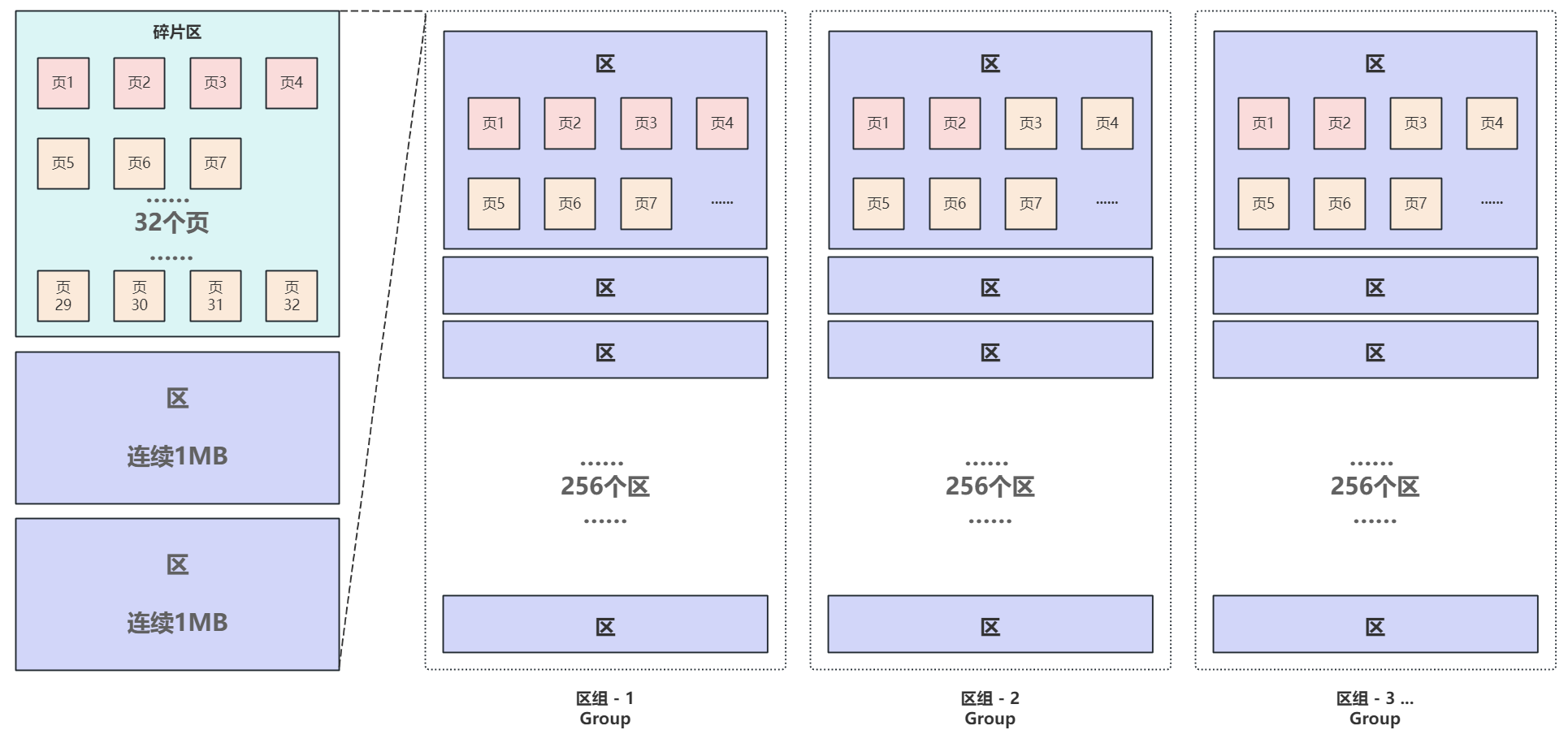
5. 段
数据页是在磁盘文件中存储,如何进一步优化?段
InnoDB使用"段"这个逻辑结构区分不同功能的区和在碎片区中的页,并按功能分 为"叶子节点段"和"非叶子节点段",做为B+树索引中的叶子、非叶子节点,从而进⼀步提升查询效率。
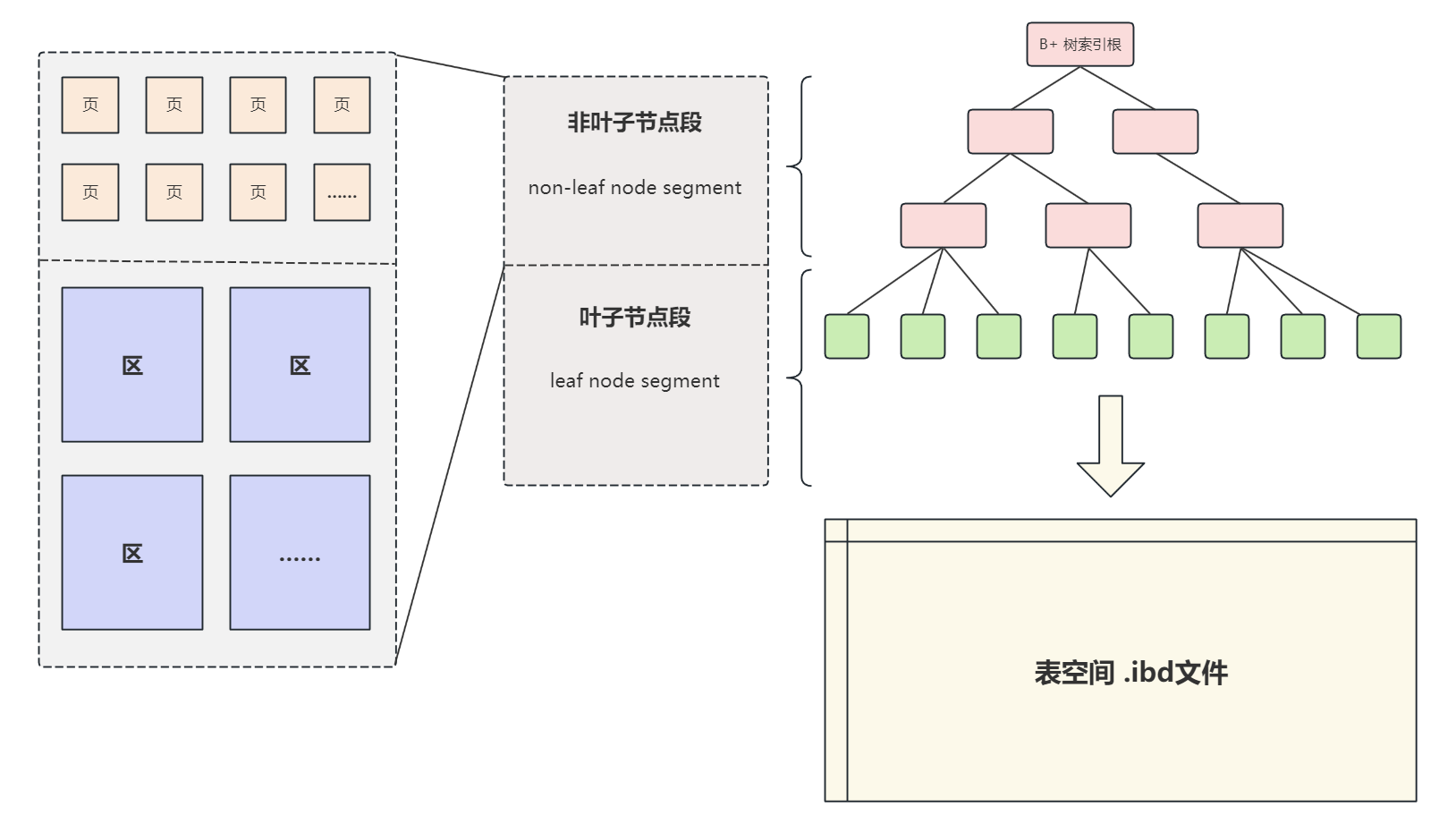
6. 表空间
用于存储用户数据的文件,innodb表空间文件以.idb为后缀;
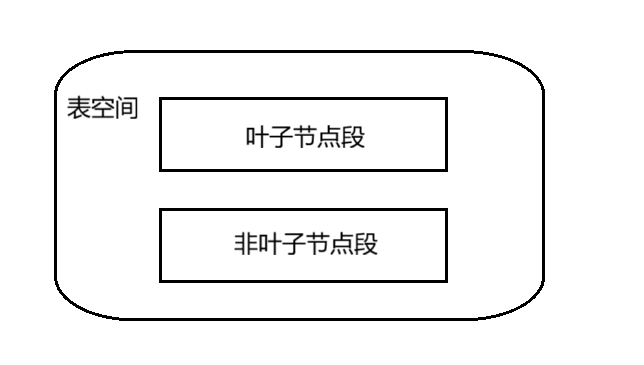
在表空间中存储时将叶子节点段和非叶子节点段区分开存储;

















 1206
1206

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









