





Kathleen Lake, YT, Canada
引言
对于这种案例,你们的处理思路是怎么样的呢,是否真正的处理过,如果遇到,你们应该怎么处理。
我想大多数人都没有遇到过。
最后有相关的社区群,有兴趣可以加入。
开始
案例:emptyDir 磁盘爆满引发的「日志黑洞」
背景与问题场景
在 Kubernetes 集群中,emptyDir 是一种生命周期与 Pod 绑定的临时存储卷,常用于缓存、临时数据处理或日志缓冲。然而,由于其默认不限制存储容量且依赖节点磁盘的剩余空间,一旦配置不当,可能迅速耗尽节点磁盘,引发级联故障。
某金融系统生产环境曾因此类问题导致日志采集中断、节点不可用,最终影响核心业务。以下是完整的故障还原与技术解析。
1. 故障现象:从日志中断到节点崩溃
时间线:15分钟的系统崩塌
- • T+0:
- • 监控系统触发
node_storage_usage告警,显示节点worker-03的/var/lib/kubelet目录磁盘使用率达 95%。 - • 运维团队收到告警但未及时响应(正值夜间值班空窗期)。
- • 监控系统触发
- • T+5分钟:
- • Fluentd DaemonSet Pod 日志出现大量
Errno::ENOSPC (No space left on device)错误。 - • 日志采集完全停止,Elasticsearch 中的业务日志流中断,影响实时风控系统。
- • Fluentd DaemonSet Pod 日志出现大量
- • T+10分钟:
- • 节点上运行的其他 Pod(如支付网关)因无法写入临时卷(
/var/log目录)进入CrashLoopBackOff状态。 - •
kubelet日志报错:"failed to create container: disk I/O error"。
- • 节点上运行的其他 Pod(如支付网关)因无法写入临时卷(
- • T+15分钟:
- • 节点被标记为
NotReady,控制平面触发 Pod 驱逐(Eviction)。 - • 部分有状态服务(如 Redis)因存储卷未正确解绑导致数据短暂不一致。
- • 节点被标记为
关键现象排查记录
# 检查节点磁盘使用情况
$ df -h /var/lib/kubelet
Filesystem Size Used Avail Use% Mounted on
/dev/nvme0n1p2 100G 95G 0G 100% /var/lib/kubelet
# 定位占用最大的 Pod 存储目录
$ du -sh /var/lib/kubelet/pods/* | sort -rh | head -n 3
78G /var/lib/kubelet/pods/7d8e12a3-.../volumes/kubernetes.io~empty-dir/fluentd-buffer
12G /var/lib/kubelet/pods/3fb2a1c1-.../volumes/kubernetes.io~empty-dir/tmp
# 检查 Fluentd Pod 日志
$ kubectl logs fluentd-abcde -n logging
2023-10-01 02:15:03 +0000 [warn]: [output_es] failed to write data: Elasticsearch::Transport::Transport::Error::NoSpace
2023-10-01 02:15:04 +0000 [error]: no space left on device @ dir_write - /var/log/fluentd/buffer/...2. 根因分析:从日志洪峰到存储雪崩
emptyDir 的“沉默杀手”特性
- • 默认无容量限制:
Kubernetes 不会自动限制emptyDir的存储使用量,仅依赖节点磁盘的物理空间。# 错误配置示例:未设置 sizeLimit volumes: - name: fluentd-buffer emptyDir: {} # 隐患点! - • 存储路径集中化:
所有 Pod 的emptyDir数据集中在/var/lib/kubelet,单点故障风险极高。
Fluentd 缓冲机制的致命缺陷
- Buffer 配置详解:
Fluentd 使用文件缓冲(File Buffer)时,会将日志数据暂存到磁盘,直到成功发送到下游(如 Elasticsearch)。<buffer> @type file path /var/log/fluentd/buffer # 挂载到 emptyDir 卷 chunk_limit_size 32MB # 单个块大小 total_limit_size 512MB # 错误!此参数不控制总大小(仅控制内存中的队列长度) retry_max_interval 30s </buffer>- 误区:开发者误认为
total_limit_size会限制磁盘总使用量,实际该参数仅控制内存中的队列长度。 - 后果:磁盘缓冲区可能无限增长,直到占满节点空间。
- 误区:开发者误认为
- 业务日志的异常洪峰:
- 触发条件:某订单处理服务因循环逻辑错误,在 1 分钟内持续打印 DEBUG 日志,生成速率达到 1GB/s。
- 日志内容示例:
[DEBUG] Processing order ID: 12345, details: {"items": [...]} # 单条日志约 10KB,每秒写入 10 万次
故障链推演
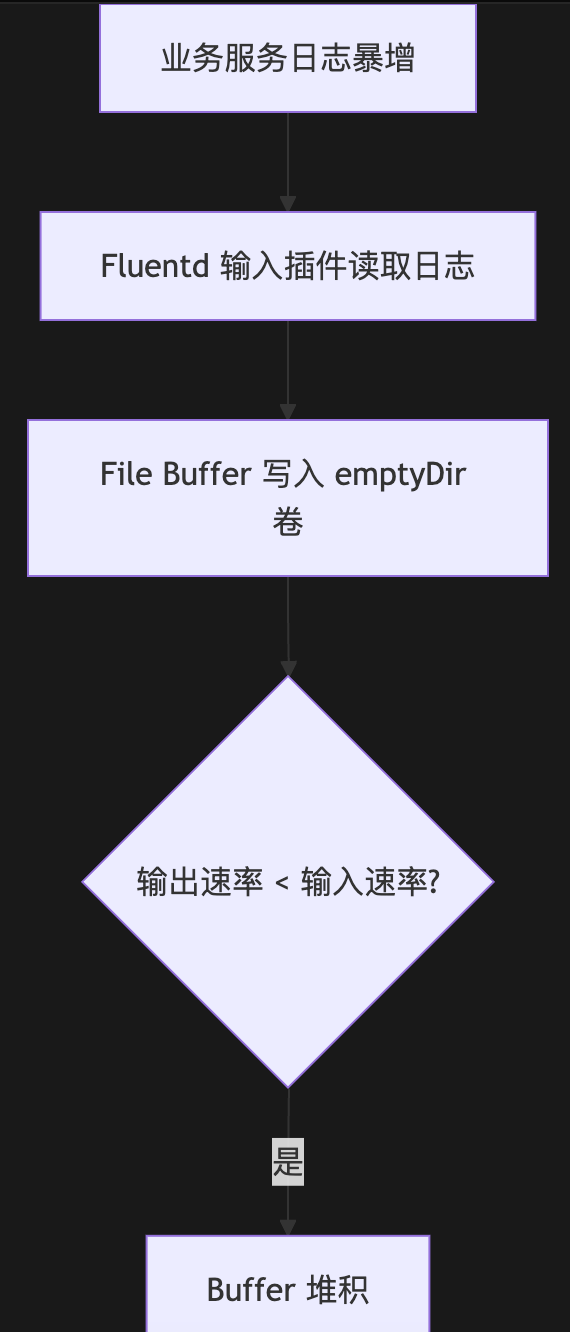
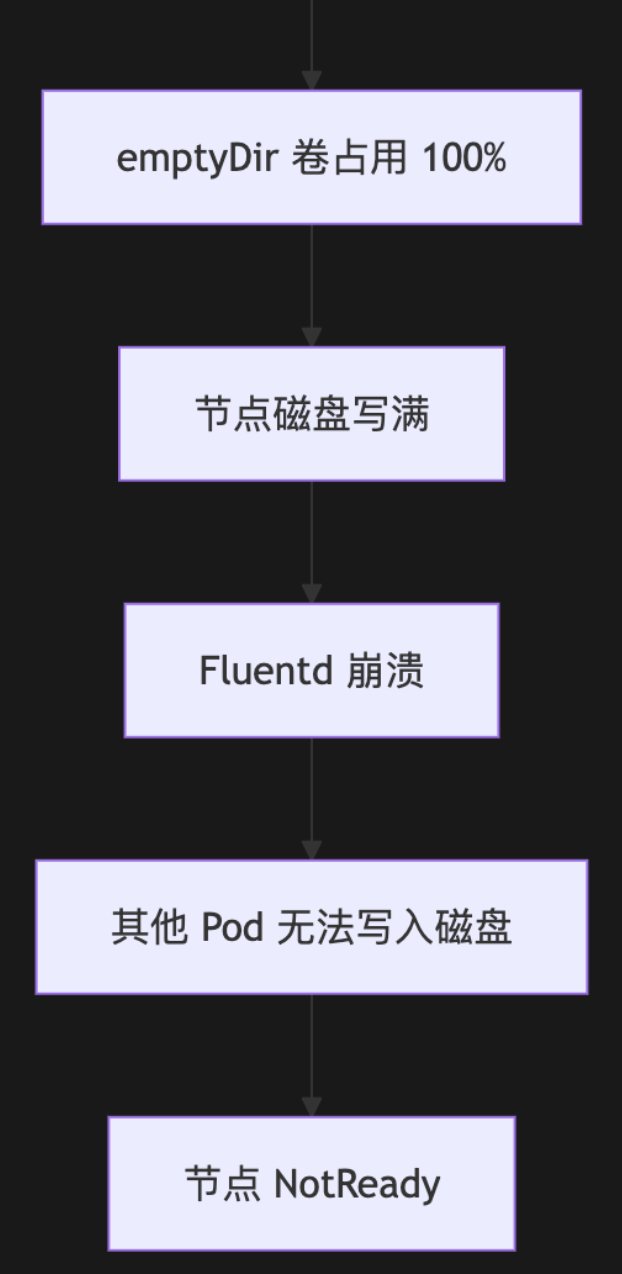
3. 解决方案:分层防御与弹性设计
阶段一:紧急止血(5分钟恢复)
- 快速释放磁盘空间:
- 强制清理:
# 找到占用最高的 emptyDir 目录 du -sh /var/lib/kubelet/pods/* | grep G # 手动删除数据(需确认无关键数据) rm -rf /var/lib/kubelet/pods/<pod-id>/volumes/kubernetes.io~empty-dir/fluentd-buffer/* - 风险:直接删除文件可能导致 Fluentd 数据丢失,需评估日志重要性。
- 强制清理:
- 临时扩容与调度:
- 垂直扩容:临时为节点挂载云盘并扩展文件系统(如 AWS EBS 卷扩容)。
- Pod 迁移:
kubectl cordon worker-03 # 停止调度新 Pod kubectl drain worker-03 --force # 驱逐现有 Pod
阶段二:根因修复(配置与架构优化)
- emptyDir 容量硬限制:
volumes: - name: fluentd-buffer emptyDir: sizeLimit: 10Gi # 关键!超出此限制时,Pod 会被驱逐并自动清理数据- 驱逐机制:当
emptyDir卷超过sizeLimit,Kubelet 会标记 Pod 为Evicted,释放存储空间。
- 驱逐机制:当
- Fluentd 缓冲层加固:
- 启用内存缓冲优先:
<buffer> @type hybrid # 混合缓冲模式 <memory> chunk_limit_size 256MB total_limit_size 8GB # 内存缓冲上限 </memory> <file> path /var/log/fluentd/buffer chunk_limit_size 512MB </file> </buffer> - 流量熔断机制:
<match **> @type elasticsearch # 当日志堆积超过阈值时,丢弃新日志(根据业务需求选择) overflow_action throw_exception # 或降级到本地文件 overflow_action block </match>
- 启用内存缓冲优先:
- 日志管道的弹性设计:

- 动态采样与降级:
<filter app.logs> @type sample interval 10 # 当日志速率超过阈值时,仅每10条记录1条 </filter>
- 引入消息队列:在 Fluentd 与 Elasticsearch 之间增加 Kafka,解耦生产与消费速率。
- 动态采样与降级:
阶段三:防御体系构建(监控与自动化)
- 存储配额与 LimitRange:
apiVersion: v1 kind: LimitRange metadata: name: storage-limiter spec: limits: - type: Container maxLimitRequestRatio: ephemeral-storage: "2" # 限制临时存储超售比例 defaultRequest: ephemeral-storage: "1Gi" - 精细化监控:
- Prometheus 规则示例:
- alert: HighEmptyDirUsage expr: (kubelet_volume_stats_used_bytes{persistentvolume="~empty-dir.*"} / kubelet_volume_stats_capacity_bytes) > 0.7 for: 5m labels: severity: critical annotations: summary: "EmptyDir volume usage exceeds 70% on {{ $labels.node }}" - Grafana 看板:监控每个 Pod 的
emptyDir使用量排名。
- Prometheus 规则示例:
- 混沌测试验证:
- 使用 Chaos Mesh 模拟日志洪峰,验证防御机制是否生效:
apiVersion: chaos-mesh.org/v1alpha1 kind: IOChaos metadata: name: disk-pressure-test spec: action: "latency" volumePath: "/var/lib/kubelet" path: "/var/lib/kubelet/**/*.log" delay: "100ms" duration: "10m"
- 使用 Chaos Mesh 模拟日志洪峰,验证防御机制是否生效:
4. 深度总结:云原生存储的防御哲学
从故障中学到的教训
- “默认安全”并不存在:
- Kubernetes 的灵活性需要显式的防护约束,如
sizeLimit、资源配额等。
- Kubernetes 的灵活性需要显式的防护约束,如
- 日志系统的容错性优先级:
- 日志管道需设计降级策略(如本地缓存、动态采样),避免影响核心业务。
- 监控的颗粒度决定响应速度:
- 不仅要监控节点级指标,还需细化到 Pod 的临时存储使用量。
扩展风险场景
- • CI/CD 流水线:Jenkins Pod 的临时构建目录可能因大文件占满磁盘。
- • 机器学习训练:训练任务的临时模型缓存需限制
emptyDir大小。 - • 临时数据库:Redis 或 SQLite 若使用
emptyDir,需设置存储阈值。
防御体系的金字塔模型
熔断降级
▲
弹性存储架构
▲
资源限制(sizeLimit)
▲
实时监控告警
▲
默认安全配置 通过分层防御,将存储风险从“事后补救”转变为“事前预防”,确保云原生系统的韧性。
结语
以上就是我们今天的内容,希望可以帮助到大家,在面试中游刃有余,主动出击。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









