



通过基于算法变换的结构混淆在消费电子中进行DSP设计保护
摘要
结构混淆提供了一种有效手段,可通过混淆来保护片上电子系统(SoC)中所用知识产权(IP)核的内容。本文提出一种新颖的结构混淆方法,用于在架构综合设计阶段保护数字信号处理器(DSP)IP核。所提出的方法特别针对包含复杂循环的IP核进行保护。采用了五种不同的算法级变换技术:循环展开、循环不变代码移动、树高缩减/增加、逻辑变换和冗余操作移除。每种技术均可生成伪装的功能等效设计。此外,通过多阶段算法变换以及粒子群优化(PSO)驱动的设计空间探索(DSE),所提出的方法还能生成低成本混淆设计。与现有类似技术相比,该方法的实验结果表明混淆程度提升了22%,混淆设计成本降低了55%。
索引术语 —数字信号处理(DSP)核,高层变换,知识产权保护,结构混淆
I. 引言
片上系统(SoC)集成电路被广泛应用于当今的消费电子设备中,包含多个主要系统模块,如存储器(SRAM、Flash)、定制处理器/协处理器、模数转换器、DSP引擎、音视频编解码器、无线调制解调器等。几乎所有现代消费电子产品,从智能手机、平板电脑、机顶盒、智能电视、家庭网关和路由器、智能厨房电器,到最近出现的智能音箱,均基于SoC集成电路。在这些设备中,主片上系统(SoC)中IP核的要求是具有优化的硅面积,从而降低制造成本,并实现低功耗运行。
因此,每个片上系统的核心都是一个DSP内核,这是涉及复杂循环的IP核架构的一个示例。其他消费电子架构——例如摄像头处理流水线、编解码器、无线调制解调器——也将具有类似的复杂循环结构。预计消费电子设备中的未来片上系统将执行复杂的任务,例如在全球随时随地浏览互联网,这将需要大部分时间使用DSP引擎[1][2],[3],[4]。
算法综合可自动完成DSP IP的设计流程,并生成实现DSP设计行为的寄存器传输级(RTL)硬件描述语言(HDL)[5],[6]。然而,当今简化算法综合的设计工具虽然功能先进,但也提供了强大的逆向工程能力,使得IP核的设计容易被轻易解析。因此,对IP核设计者而言,一个重大的新兴威胁是盗版,即通过逆向工程实现对IP的直接窃取/复制并未经许可地重用。盗取者极有可能“悄无声息”地重用该IP,以节省设计/测试成本[7]。
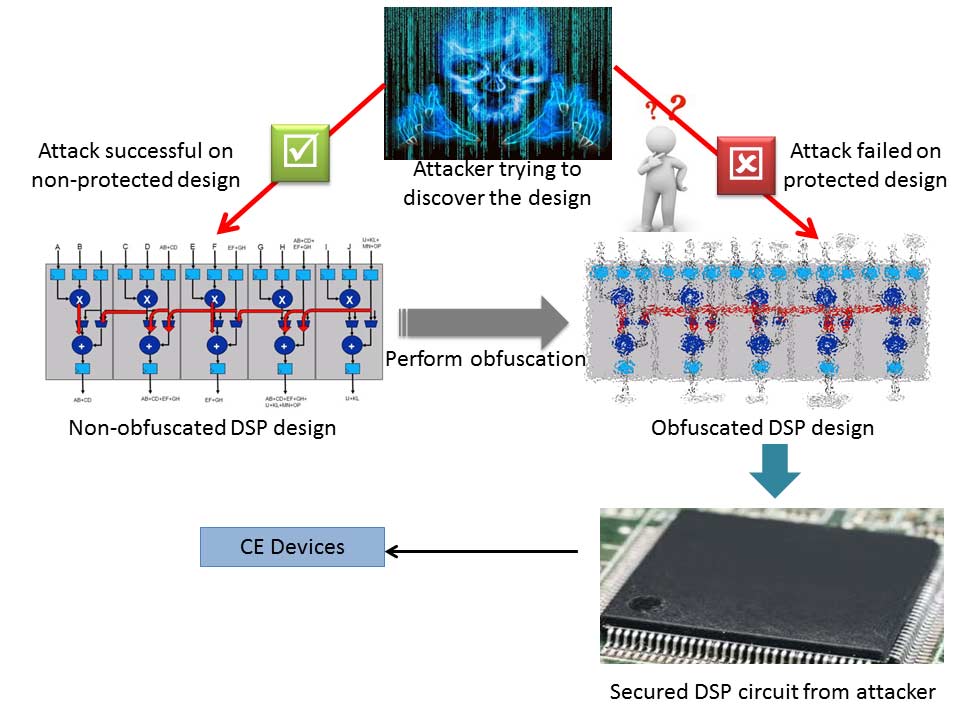
图1展示了DSP应用的典型攻击场景及其保护机制。因此,在便携式消费电子设备中,成功的DSP数据路径设计的关键在于防范逆向工程等威胁的安全性[2],[8],[9],[10],[11],[12],[13],[14]。本文提出了一种新颖的多阶段高层变换驱动的混淆方法,用于消费电子设备中的DSP知识产权核。
本文的其余部分组织如下:在第二节中,我们详细阐述了本文的创新贡献。第三节讨论了主要的相关方法,而第四节描述了我们所提出的基于低成本算法级(高级)变换(HLT)的混淆方法。第五节解释了所提出方法的演示。此外,第六节给出了实验结果,第七节为结论。
II. 创新贡献
本文的主要贡献如下:
- 针对基于循环的控制密集型应用,在DSP架构的算法(体系结构)层面提出了一种新颖的基于混淆的方法。
- 引入多种基于循环的高层变换以增强混淆复杂度。
- 通过方法学优化,满足硬件面积、系统延迟和总体设计成本等关键设计约束。
- 提出一种面向基于循环的控制密集型应用的基于混淆的方法,相较于其他类似方法在混淆能力(PoO)方面提供更高的安全性。
威胁模型 :本文提出的工作通过隐藏IP设计的结构,在RTL综合过程中增加了攻击者进行逆向工程的复杂性,从而提供对知识产权盗用和木马插入的保护。
III. 相关前期研究
消费电子领域的文献中有许多研究涉及数字信号处理器[15],[16],[17]的各个方面。这些研究主要关注消费电子系统特性的不同方面,如能效、高性能和面积效率。然而,它们忽略了CE系统的关键维度(即“安全与知识产权保护”),因此未能全面应对当前社交网络驱动时代中网络安全作为关键设计轴的消费电子设计关键问题。
A. 基于混淆的方法
混淆是过程将原始应用或设计转换为其功能等效形式,以显著增加逆向工程的难度[11]。DSP IP 的混淆可通过两种方式实现:a) 逻辑混淆,b) 结构混淆。逻辑混淆通过在数字信号处理设计中插入附加组件来隐藏其实现。与逻辑混淆不同,结构混淆通过变换和逻辑元件的随机布局来隐藏数字信号处理设计的功能。一种实现方式基于DSP处理器的软件定义数字视频广播(DVB‐T2)调制器和DVB‐H接收机和网关分别在[2]和[3]中实现。这些方法均未隐藏DSP IP的功能,以最小化逆向工程攻击。然而,所提出的方法通过一系列高层变换技术,在低设计成本下对DSP设计进行混淆。
1) 基于源代码的混淆
为了防止攻击者理解硬件描述语言代码,可以通过变换[19]将代码转换为更复杂的形式,或使用某些加密技术[20]对源代码进行加密。在[19], VHDL(超高速集成电路硬件描述语言)代码混淆中,采用不同的变换技术来增加逆向工程的难度。在[20], 中,基于死代码插入技术在加密器上实现源代码的加密。然而,在所提出的方法中,不同于[19] 和[20],通过多种高层变换实现了低成本的数字信号处理设计结构混淆。
2) 逻辑混淆
根据[21],逻辑混淆可分为两种类型:a) 时序,b) 组合。在时序逻辑混淆中,向设计的有限状态机(FSM)中插入额外的无效或阻塞状态[22][23]。该有限状态机的构造方式使得当施加正确密钥时,设计能够正常执行并到达有效状态。在组合逻辑混淆中,通过在电路中引入额外的异或/同或门来保护知识产权核[24][25][26][27],[28]。所有这些基于密钥的混淆技术由于添加了附加组件,增加了设计开销增大的风险。此外,[22][23][24][25][26]未采用任何优化技术来实现低成本的功能性混淆设计。相反,所提出的方法通过采用多种基于变换的结构混淆来保护数字信号处理设计。
3) 结构混淆
在[11],[29]中,针对DSP电路执行了结构混淆。然而,[11]未对DSP设计应用多阶段HLT技术,例如:ROE、LT、THT、LICM、循环展开。此外,[11]未从多种结构混淆设计中探索低成本的混淆设计。而且,[11]中未说明折叠因子的计算方法,导致设计开销较高。进一步地,[29]未处理基于循环的控制数据流图(CDFG)在DSP中的应用,因此无法应用基于循环的HLT技术来混淆设计。此外,在综合过程中未生成混淆设计的等效DSP电路。我们所提出的方法在算法综合期间,针对基于循环的控制数据流图,执行低成本、编译器驱动的多阶段高层综合变换技术,以实现结构混淆。通过由粒子群优化(PSO)驱动的设计空间探索过程,实现了最优成本。
B. 基于认证的方法
在基于数字对称的[30]知识产权保护机制中,IP卖方的签名可使所有权的虚假声明失效,从而防止知识产权侵权[31];而IP买方的签名则可追踪由不可信的IP卖方非法转售或过度制造的知识产权核副本,从而提供专属用户权利。计算法证工程(CFE)是一种非基于签名的IP保护机制。它试图识别生成的IP是否来自熟悉的源[32]。IP计量[23],是另一种非基于签名的IP核保护机制,用于检测IP核的过度制造/重复副本。在硬件计量[33],中,通过编程将唯一生成的ID插入到IP核设计中,从而帮助区分合法制造的IP与其重复/未经授权的副本。
上述所有IP保护机制均为基于认证的方法。这些技术的局限性在于,这些被动保护方法仅能够追踪IP的非法副本,但无法防止IP被窃取[22]。
IV. 混淆IP核设计方法论
所提出的方法在算法综合期间对攻击者隐藏了应用程序(IP)的功能。算法综合的输出是一个可重用IP核的结构混淆的RTL描述(数据路径和控制器设计)。该设计的混淆通过多个阶段的高层变换技术实现,这些技术难以被逆向工程。
A. 所提出方法的概述
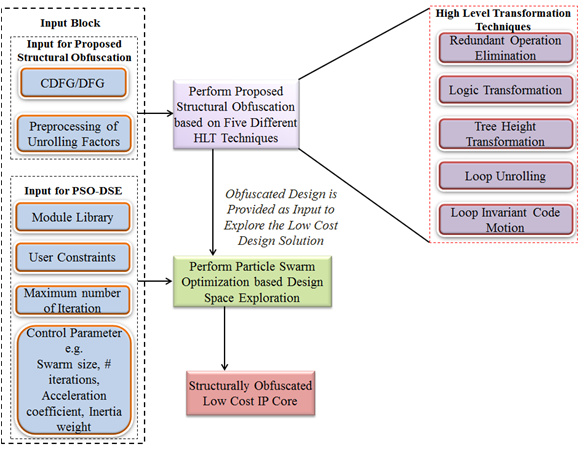
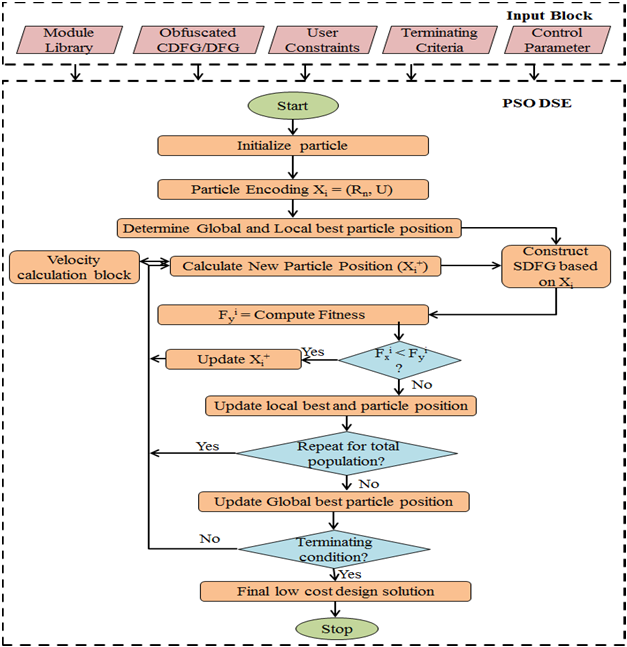
如图2所示,所提出的方法以基于循环的控制数据流图作为输入,并使用五种高层变换技术对原始设计进行混淆,即冗余操作消除(ROE)、逻辑变换(LT)、树高变换(THT)、循环展开(LU)和循环不变代码移动(LICM)。混淆后的设计进一步作为输入,用于执行由粒子群优化驱动的设计空间探索(DSE)。最终生成满足用户给定面积‐延迟约束的结构混淆的低成本IP。基于HLT的多阶段混淆以及由PSO驱动的DSE过程分别在第四节第IV‐C节和第 IV‐D节中详细说明。
B. 问题定义和评估模型
1) 问题定义
给定一个基于循环应用的控制数据流图,探索设计空间以确定最优的结构混淆设计方案。生成的解应尽量降低整体设计成本,同时满足相互冲突的用户给定约束。该问题可表述如下:
Minimize: 混淆设计成本 (AT_OBF, TE_OBF),for 最优 Xi。
Subject to: AT_OBF ≤ A_cons 且 TE_OBF ≤ T_cons,并通过结构混淆实现知识产权保护。其中 Xi 是一个具有循环展开的粒子解的资源集,可表示为:
Xi={N(R1), N(R2),.. N(RD), UF} (1)
其中,N(RD) 表示资源类型 RD 的数量;UF 是基于循环应用的展开因子;AT_OBF 和 TE_OBF 分别表示混淆设计所占用的总硬件面积和总执行时间;A_cons 和 T_cons 分别表示用户指定的面积和时间约束。
2) 面积模型
结构安全的混淆设计所消耗的总面积AT_OBF采用自[30],,可表示为如下:
$$
A_{T_OBF} = \sum_{i=1}^{m} A(R_i) * N(R_i) + A(mux) * N(mux) + A(buffer) * N(buffer)
$$
总面积是硬件资源、互连单元和存储单元所占面积的总和。其中,A(Ri)、A(mux) 和 A(buffer) 分别表示 ith 硬件资源、多路复用器/解复用器和存储单元的面积;N(Ri)、N(mux) 和 N(buffer) 分别表示 ith 硬件资源、多路复用器/解复用器和存储单元的数量。
3) 延迟模型
混淆设计的总延迟 TE_OBF 部分采用自[34],,可以表示为:
$$
T_{E_OBF} = T_{first_OBF} + \left\lceil \frac{I}{UF} \right\rceil * T_{body_OBF}
$$
在上述表达式中,T_body_OBF是执行一次混淆的CDFG循环体的延迟;I是最大迭代次数(循环次数);T_first_OBF是混淆的CDFG第一次迭代的执行延迟。
4) 适应度函数
每个解的适应度根据以下适应度函数计算(考虑硬件面积消耗和执行延迟):
$$
C_f(X_i) = \Phi_1 * \left( \frac{A_{OBF}}{A_{cons}} \right) + \Phi_2 * \left( \frac{T_{OBF}}{T_{cons}} \right)
$$
其中,Cf(Xi) 是解 Xi 的成本;A_max_OBF 和 Tmax_OBF 分别表示混淆设计的最大面积和执行延迟;A_cons 和 T_cons 分别是用户指定的面积和延迟约束。Φ1 和 Φ2 分别是面积和延迟的用户定义权重,其值介于 0 到 1 之间(注意:两者 Φ1 和 Φ2 均设为 0.5,以在探索过程中提供相等的偏好。)
C. 所提混淆方法流程

如图3所示,在算法综合期间,所提出的多阶段 HLT驱动的结构混淆方法通过五种不同的基于编译器的 HLT技术实现。它们是:(1) 冗余操作消除(ROE) (2) 逻辑变换(LT) (3) 树高度变换(THT)(4) 循环展开(LU)(5) 循环不变代码移动(LICM)。我们的方法以基于循环的控制数据流图形式接收应用程序的输入,并应用上述每种高级逻辑变换(HLT)对其进行混淆。
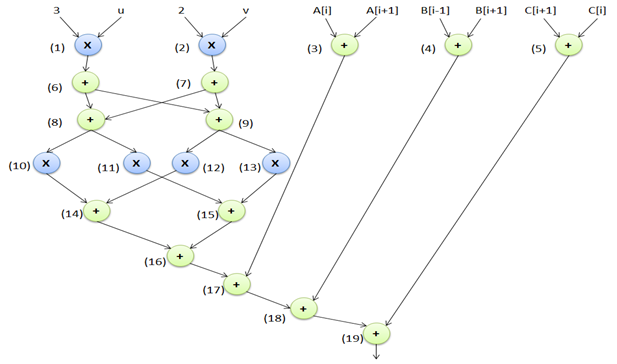
 和4(*)的原始非混淆调度控制数据流图)
和4(*)的原始非混淆调度控制数据流图)
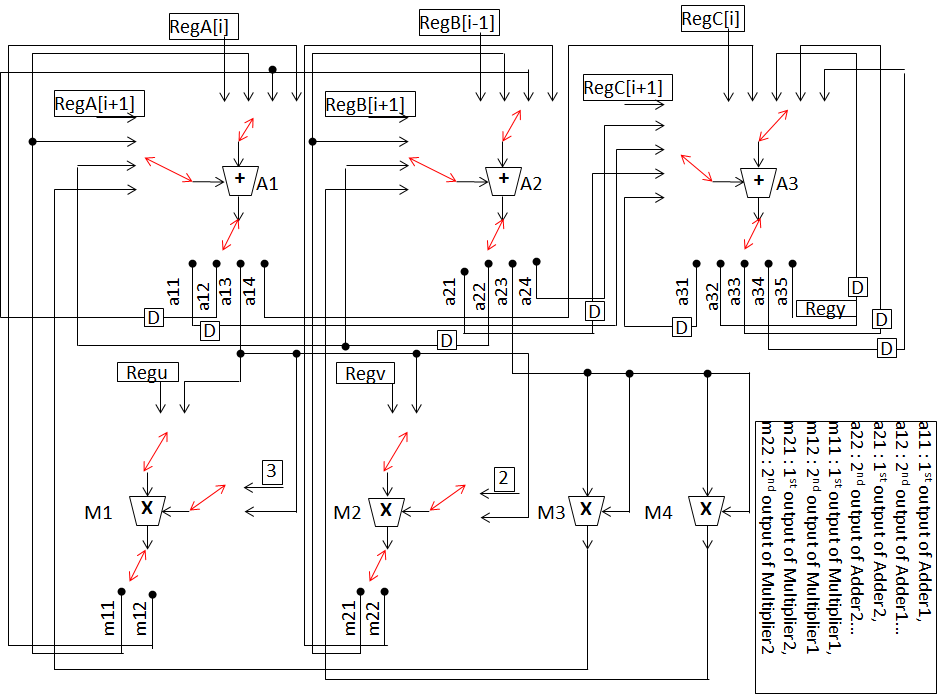
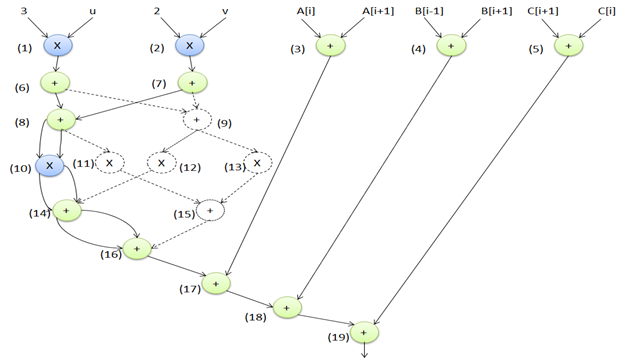
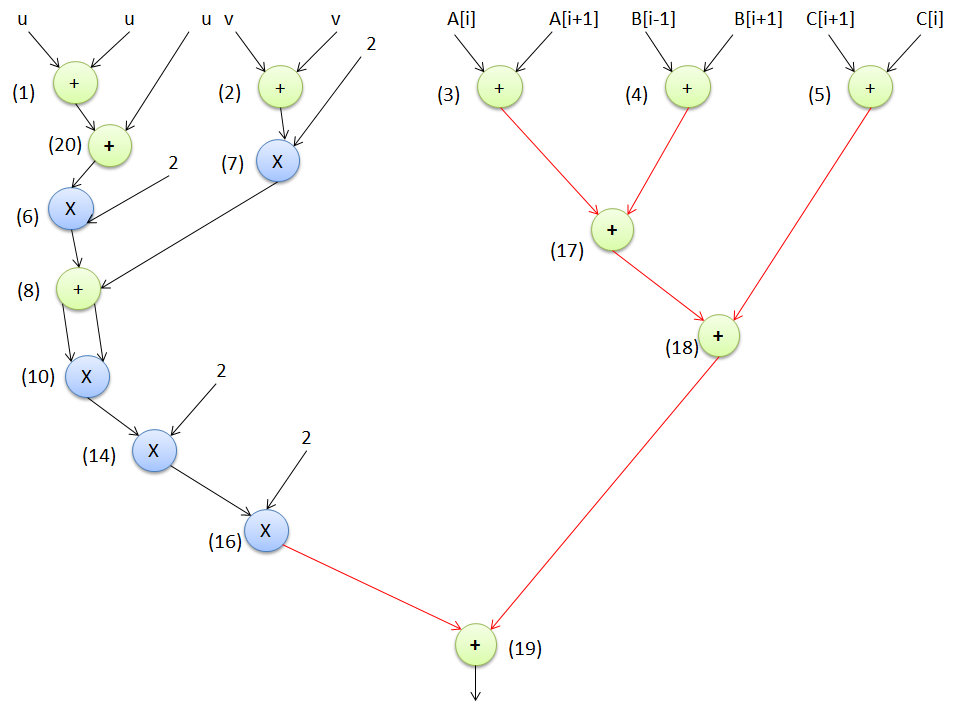
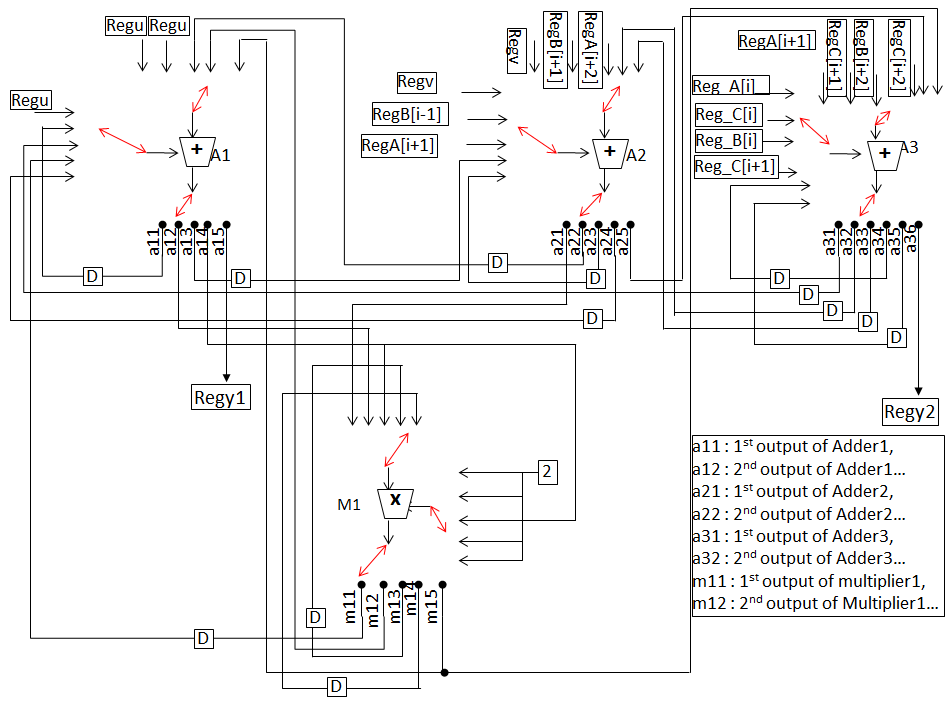
图4展示了一个用于演示的(示例)非混淆原始设计。该设计基于用户定义输入的3个加法器和4个乘法器进行调度。图5显示了该非混淆设计的调度后控制数据流图(CDFG)。等效DSP电路如图6所示。该电路采用了6个4选1多路复用器、4个2选1多路复用器、10个输入寄存器、1个输出寄存器和8个延迟元件。每种高层综合变换技术(HLT technique)的具体过程将在以下小节中通过适当的示例进行说明。
冗余操作消除过程 :一种高层综合变换技术,通过从输入的控制数据流图中移除冗余节点来实现混淆,即冗余操作消除。在输入图中,如果存在另一个节点与其具有完全相同的父节点/输入以及相同的操作类型,则该节点被识别为冗余节点。在所提出的方法中,我们基于节点逐一进行扫描按升序排列。如果发现一对节点具有相同的输入和操作类型,则节点编号较高的节点被识别为冗余节点。这些节点将从图中删除,并进行必要的调整以保持图的正确功能。最后,生成基于ROE的结构混淆图作为输出。例如,在图4所示的原始设计中,冗余操作是节点9、11、12、13、15,通过所提出的方法在图7中将其消除,从而实现设计的结构混淆。为了保持输出的正确性,在基于ROE的混淆设计(图7)中,节点14和16的输入分别来自节点10和14。
1) 逻辑变换过程
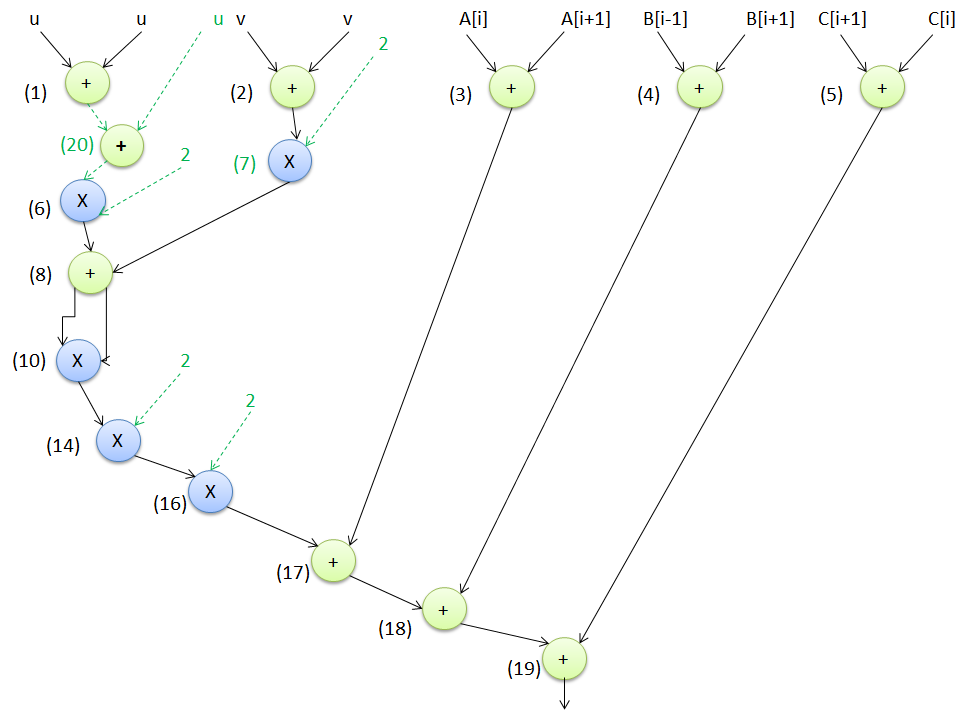
另一种高层综合变换技术,通过对输入的控制数据流图进行修改,使用不同的逻辑等价函数来实现混淆,即逻辑变换。该技术通过改变输入图中的节点,使得生成的图在外观上不同于原始图,但仍能正确保持原有功能。最终输出基于逻辑变换的结构混淆图。
例如,图8 表示输入图(图7)的基于逻辑变换驱动的混淆形式;新添加/修改的节点用绿色标记的节点编号表示,修改后的依赖关系用绿色虚线表示。然而,由于两种设计在功能上是等效的,因此会产生相同的输出。
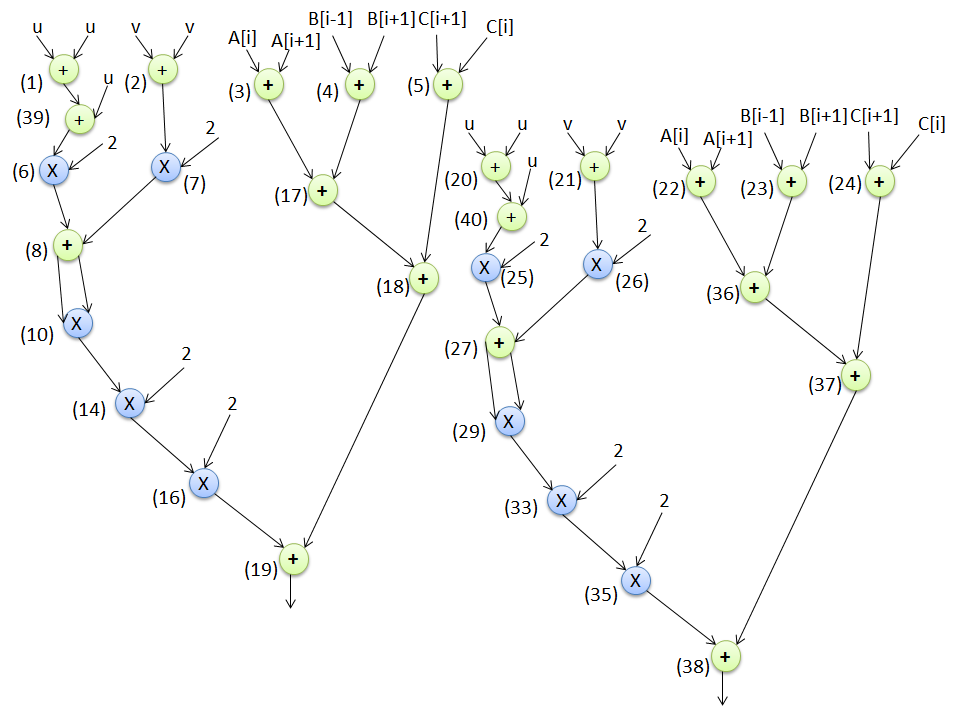
2) 树高变换过程
另一种负责通过增加或减少图的高度来混淆输入控制数据流图的高层综合变换技术是树高变换。它将关键路径依赖划分为临时子计算并进行并行评估,从而生成结构上不同但功能等效的图。最后,输出基于树高变换的结构混淆图。
例如,在图9中,显示了基于THT的输入图结构混淆形式(如图8所示)。与原始设计相比,该形式将混淆图的高度从10减少到8。在混淆设计中,节点17和18的计算先于输入设计执行。混淆图的依赖关系经过调整以保持正确的功能,修改后的依赖关系用红线标出。
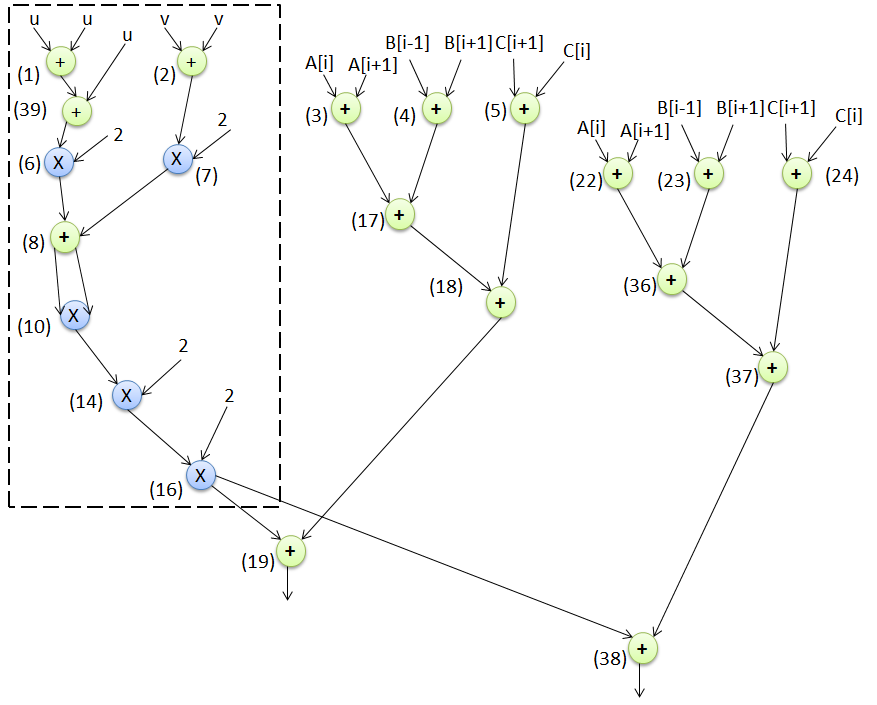
3) 循环展开
一种基于循环变换的高层综合变换技术,通过应用于输入的控制数据流图来实现混淆展开循环即为循环展开。通过将相同的循环体重复多次,可以实现循环展开,从而改善执行延迟。最后,生成基于循环展开的结构混淆图作为输出。
例如,图10将输入的基于循环的控制数据流图循环展开两次。在所提出的方法中,基于由粒子群优化驱动的设计空间探索来寻找最优的展开因子。循环展开既能最小化执行时间,同时又能对设计进行混淆。
4) 循环不变代码移动
另一种在所提出的方法中用于通过将循环无关节点移出循环体来混淆输入控制数据流图的基于循环的高层综合变换技术是循环不变代码移动。该技术将那些在循环内迭代执行或在循环外执行一次都不会产生差异的节点移出循环,从而在保持图表功能正确的前提下加快执行过程。最终生成基于LICM的混淆图作为输出。
例如,图11展示了输入图(如图10所示)基于LICM的结构混淆形式。虚线框表示不依赖于循环的节点。根据图11,当展开因子为2时,循环不变操作执行一次,而循环依赖操作执行两次。
为了在混淆过程中获得更高的鲁棒性,所有上述高层变换技术都在连续的阶段中执行(参见图3)。
D. 探索粒子群优化驱动的低成本混淆设计
在我们所提出的方法中,通过由粒子群优化驱动的设计空间探索实现低成本的混淆IP设计。该方法接受混淆设计(解释如下)在第IV‐C节中,将应用程序以基于循环的控制数据流图、模块库、粒子群优化的终止条件、控制参数(如惯性权重、社会因子、认知因子等)以及用户给定的面积‐延迟约束作为输入,生成低成本优化混淆IP设计作为输出。图12所示的详细PSO‐DSE过程将在以下小节中进行说明。
1) 粒子群优化方法概述
PSO 是一种基于种群的随机优化方法,其中每个单独的解被称为一个粒子。每个粒子的适应度根据待优化的适应度函数进行评估。粒子的速度决定了其移动方向。粒子在搜索空间中通过跟踪当前的全局最优‘gbest’和自身的历史最优位置‘lbest’进行移动。当找到更优的‘gbest’或‘lbest’时,该{i th }粒子会更新其速度和位置。
2) 使用速度的粒子运动
在PSO驱动的设计空间探索过程[34],中,每个粒子的速度(V_d_i)的每个维度(d)根据以下方程进行更新:
$$
V_{d}^{i+1} = \omega V_{d}^{i} + b_1 r_1 (R_{d}^{lbi} - R_{d}^{i}) + b_2 r_2 (R_{d}^{gb} - R_{d}^{i})
$$
其中,V_d_i+ 和 V_d_i 分别是第 ith 个粒子在 dth 维的最新速度和当前速度;R_d_i 是第 ith 个粒子在 dth 维的资源值/展开因子;R_d_lbi 是第 ith 个粒子在 dth 维的局部最优位置;R_d_gb 是 dth 维的全局最优。
3) 终止条件
基于粒子群优化的DSE过程将在以下任一条件满足时终止:a) 达到最大迭代次数(I_max),b) 在δ次迭代中未观察到全局最优的改进,c) 速度值变为零。在我们的方法中,I_max 和δ的值分别取为100和10。
V. 所提方法的演示
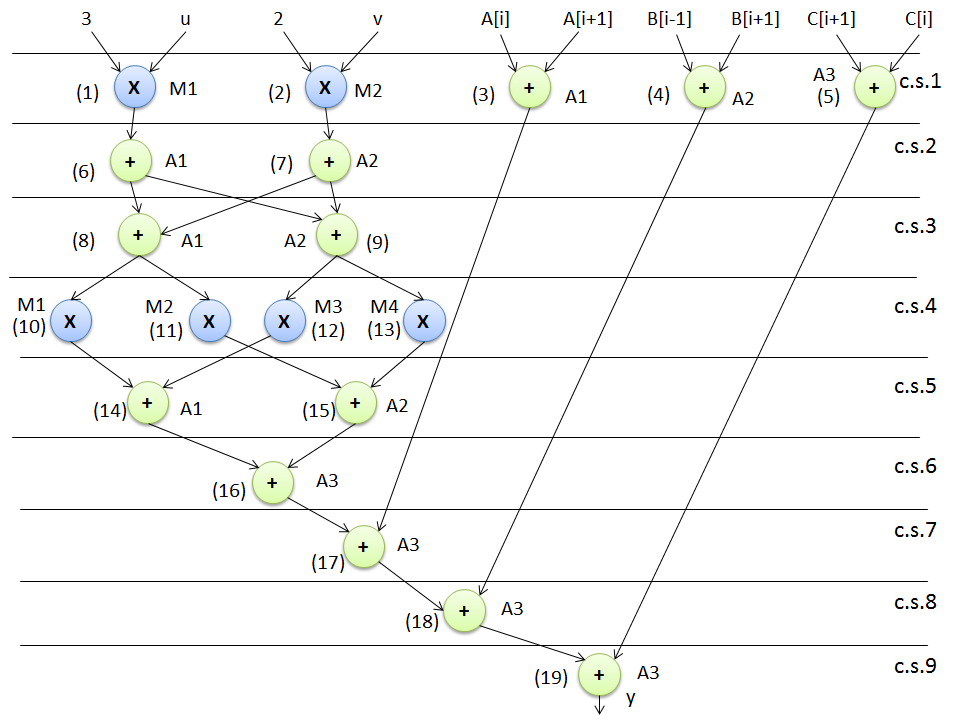
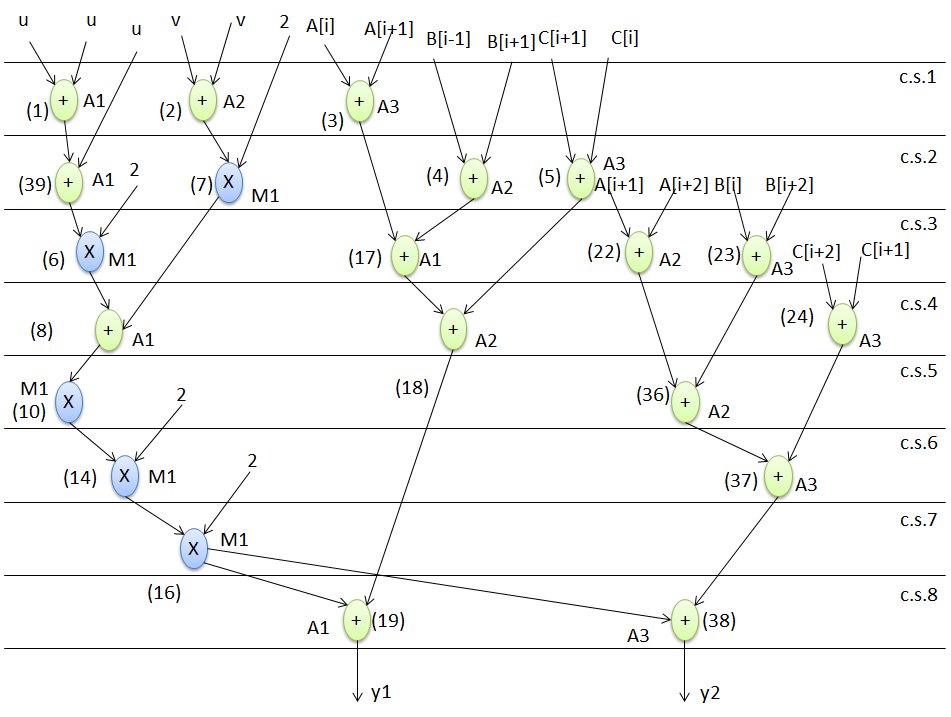
为演示所提出的方法,采用一个原始非混淆控制数据流图(如图4所示)作为输入。图中蓝色节点表示乘法器,绿色节点表示加法器。每个节点旁边的整数值表示相应的节点编号。如图4所示,图的主输入A、B和C表示循环依赖变量,u、v表示循环无关变量,其余为常量值。展开前图中的节点总数为19,包含的循环数量为8,图的高度为9。使用多阶段驱动的高级逻辑变换(HLT)进行混淆的设计如图13所示。基于循环的控制数据流图被展开两次,循环不变节点(标记为黑色虚线框)保留在循环外部,由于冗余删除了节点9、11、12、13、15,由于逻辑变换修改了节点6、7、14、16、39,图的高度从9减少到8,总节点数从19增加到21。该混淆设计进一步与其他必要输入(参见图12)一起作为输入,用于执行由粒子群优化驱动的设计空间探索(PSO driven DSE)过程,以探索最优的混淆IP设计。图14表示基于3个加法器和1个乘法器调度的最终低成本混淆IP设计。等效混淆DSP电路如图15所示。该电路采用8个8选1多路复用器、18个输入寄存器、2个输出寄存器和13个延迟元件。
 和1(*))
和1(*))
VI. 实验结果
我们所提出的方法通过在算法综合期间采用基于多阶段的 HLT驱动的混淆方法,为DSP IP核提供了低成本且可靠的保护。
A. 实验设置与基准
所提出的方法、非混淆的设计和[11]均在Java 8中实现,并在配备4GB DDR73主内存和3.20 GHz处理器频率的计算平台上执行。基于NanGate的15纳米技术尺度用于评估知识产权设计[35]的面积和延迟。在多阶段混淆过程中,按以下顺序对基于循环的控制数据流图应用不同的高级逻辑变换(HLT): 1)循环展开,2)LICM,3)寄存器输出扩展,4)循环展开(LT),5)THT。在PSO‐DSE过程中,Ø1和Ø2均保持为 0.5,以对硅面积和延迟赋予相等的权重,因为对于消费电子设备的数字信号处理设计而言,两者同等重要。为了实现更广泛的优化,设计者可将权重因子调整为不相等的值。然而,这种情况适用于设计者将硅面积的优先级设得高于延迟,或反之。此外,PSO框架采用来自[34]的以下最优设置: ω(惯性权重)=从0.9线性递减至0.1;b1和b2(加速系数) = 2;r1和r2(随机数)= 1;Imax= 100或δ= 10作为停止准则; 种群大小p为= 3或5或7。
B. 所提出的方法在设计成本和安全指标方面的结果
| 基准 | 粒子 Size | 设计方案 | 混淆设计面积(μm²) | 混淆设计延迟(ps) | 混淆设计成本 |
|---|---|---|---|---|---|
| 二维自回归格型滤波器(ARF) | 3 | 4A, 2M | 241.83 | 1900.80 | -0.37 |
| 5 | 4A, 2M | 241.83 | 1900.80 | -0.37 | |
| 7 | 4A, 2M | 241.83 | 1900.80 | -0.37 | |
| FIR(6抽头) | 3 | 2A, 2M,1C, 8UF | 214.99 | 1477.85 | -0.36 |
| 5 | 2A, 2M,1C, 8UF | 214.99 | 1477.85 | -0.36 | |
| 7 | 2A, 2M,1C, 8UF | 214.99 | 1477.85 | -0.36 | |
| 自相关 | 3 | 4A, 8M,1C, 8UF | 726.17 | 3557.15 | -0.46 |
| 5 | 7A, 8M,1C, 8UF | 800.68 | 2940.45 | -0.47 | |
| 7 | 7A, 8M,1C, 8UF | 800.68 | 2940.45 | -0.47 | |
| 微分方程 | 3 | 2A, 3M, 1C, 16UF | 330.99 | 4498.80 | -0.33 |
| 5 | 2A, 3M, 1C, 16UF | 330.99 | 4498.80 | -0.33 | |
| 7 | 2A, 3M, 1C, 16UF | 330.99 | 4498.80 | -0.33 | |
| DHMC | 3 | 4A, 4M, 1C, 6UF | 419.07 | 8581.61 | -0.63 |
| 5 | 4A,4M,1C,6UF | 419.07 | 8581.61 | -0.63 | |
| 7 | 4A,4M,1C,6UF | 419.07 | 8581.61 | -0.63 | |
| 自适应滤波器(噪声消除) | 3 | 4A,1S,1M,1C,30UF | 270.83 | 3120.01 | -0.63 |
| 5 | 4A,1S,1M,1C,30UF | 270.83 | 3120.01 | -0.63 | |
| 7 | 4A,1S,1M,1C,30UF | 270.83 | 3120.01 | -0.63 | |
| 自适应滤波器(最小均方) | 3 | 5A,1S,1M,1C,30UF | 292.26 | 6833.58 | -0.70 |
| 5 | 5A,1S,1M,1C,30UF | 292.26 | 6833.58 | -0.70 | |
| 7 | 5A,1S,1M,1C,30UF | 292.26 | 6833.58 | -0.70 |
表I显示了群体大小变化对混淆设计面积、延迟和成本的影响。从表I可以看出,除了自相关基准外,其他基准在解的质量上均未发现改进。然而,对于自相关基准,当p = 5时设计成本为‐0.4647,优于p = 3时的设计成本‐0.4556;而p = 5和p = 7时的设计成本保持不变。此外,所有基准均满足用户提供的面积‐延迟约束,以根据(4)优化混淆设计成本,从而实现小于0的设计成本值。设计成本是一个数学度量指标,表示数字信号处理设计的硅面积和延迟的归一化值的综合(见(4))。设计成本可能指实现成本,但由于(4)计算的是归一化值,因此是无量纲的。
所提出的混淆方法的鲁棒性通过原始设计与所提混淆设计之间的结构不匹配来衡量。单阶段混淆(p_obf)和多阶段混淆(P_obf)的混淆能力用以下公式表示,其归一化值介于0到1之间:
$$
p_{obf}^i = \frac{n_i}{n_T^i}
$$
$$
P_{obf} = \frac{1}{5} \sum_{i=1}^{5} p_{obf}^i
$$
其中,n_i 是由于第 ith 种 HLT 技术而被修改的节点数量;n_T^i 是在应用第 ith 种 HLT 技术之前的总节点数; N(HLT) 是应用于特定应用的 HLT 技术的总数。P_obf 的值越高,表示该设计的安全性越强。如果一个节点满足以下任一情况,则被视为被修改的节点:
- 混淆的CDFG中某节点的父节点或主输入与其原始版本不同。
- 混淆的CDFG中某节点的子节点与其原始版本不同。
- 混淆的CDFG中某节点的操作类型(加法、乘法等)被更改。
- 原始控制数据流图中的某个节点在对应的混淆的CDFG中不存在。
| 基准 | pobf for ROE | pobf for LT | pobf for THT | pobf for UF | pobf for LICM | 总Pobf |
|---|---|---|---|---|---|---|
| ARF | 0.32 | 0.61 | 0 | – | 0.55 | |
| FIR | 0 | 0 | 0.50 | 1 | - | 0.75 |
| 自动相关系数 | 0 | 0 | 0.49 | 1 | - | 0.75 |
| 差分方程 | 0 | 0.44 | 0 | 1 | - | 0.72 |
| DHMC | 0 | 0.38 | 0 | 1 | - | 0.69 |
| Ada‐NC | 0 | 0.67 | 0.03 | 1 | - | 0.57 |
| Ada‐LMS | 0 | 0.75 | 0 | 1 | - | 0.88 |
表II给出了每种高层综合变换技术(HLT technique)对应的p_i_obf以及应用多阶段高层综合变换(multi‐stage HLTs)后的总 P_obf。例如,对于ARF基准,单独应用每种HLT时,ROE、LT和THT的p_i_obf分别为0.32、0.61和0,而基于多阶段的混淆(multi‐stage based obfuscation)的总归一化P_obf为0.55。
C. 比较视角与讨论
| 基准 | 原始设计 (非混淆的) | 所提混淆的设计 | ||||
|---|---|---|---|---|---|---|
| Area (μm²) | 延迟 (ps) | Cost | Area (μm²) | 延迟 (ps) | Cost | |
| ARF | 241.8 | 2573.5 | -0.26 | 241.8 | 1900.8 | -0.37 |
| FIR | 215.0 | 1661.3 | -0.31 | 215.0 | 1477.8 | -0.35 |
| 自动相关系数 | 736.4 | 3399.2 | -0.48 | 736.4 | 2940.5 | -0.46 |
| 差分方程 | 333.0 | 7246.5 | -0.18 | 333.0 | 4498.8 | -0.33 |
| DHMC | 419.1 | 8872.1 | -0.27 | 419.1 | 8581.6 | -0.63 |
| Ada‐NC | 270.8 | 3330.98 | -0.62 | 270.8 | 3120.01 | -0.63 |
| Ada‐LMS | 292.3 | 12561.3 | -0.61 | 292.3 | 6833.58 | -0.70 |
非混淆设计与其混淆形式在设计面积、延迟和成本方面的比较如表III所示。例如,非混淆FIR基准的设计面积、设计延迟和设计成本分别为214.99平方微米(μm²)、1661.33皮秒(ps)和‐0.31,而混淆FIR基准的设计面积、设计延迟和设计成本分别为214.99平方微米(μm²)、1477.84皮秒(ps)和‐0.35。注意:有时混淆设计的延迟低于非混淆设计,这是因为所提出的方法执行了一系列高层综合优化(如ROE、THT、LT、循环展开等),可能导致图中操作数量减少。因此,在这种特定情况下,调度后的图可能产生更低的延迟。
| 基准 | [11]的设计 | 所提混淆的设计 | ||||
|---|---|---|---|---|---|---|
| Area (μm²) | 延迟 (ps) | Cost | Area (μm²) | 延迟 (ps) | Cost | |
| ARF | 788.8 | 1511.5 | -0.08 | 241.8 | 1900.8 | -0.37 |
| FIR | 399.5 | 1315.7 | -0.25 | 215.0 | 1477.8 | -0.35 |
| AUTO‐CO | 3196.1 | 1144.9 | -0.32 | 736.4 | 2940.5 | -0.46 |
| 差分方程 | 3590.1 | 2326.4 | -0.15 | 333.0 | 4498.8 | -0.33 |
| DHMC | 4818.9 | 2891.1 | -0.28 | 419.1 | 8581.6 | -0.63 |
| Ada‐NC | 2959.0 | 2826.5 | -0.28 | 270.8 | 3120.01 | -0.63 |
| Ada‐LMS | 6075.2 | 4385.8 | -0.30 | 292.3 | 6833.58 | -0.70 |
表IV显示了基于多阶段的混淆设计方法与[11]在设计面积、延迟和成本方面的比较。例如,[11]在FIR基准上的设计面积、设计延迟和设计成本分别为399.50平方微米(μm²)、1315.67皮秒(ps)和‐0.25,而所提出的混淆方法为FIR基准探索出了更优的设计方案(此前已报道)。最后,所提出的方法实现了平均55%的降低所提出的方法在标准基准上的设计成本[36][37],相较于[11]。这是由于所提出的方法中采用基于粒子群设计空间探索的优化进行面积‐延迟权衡而实现的。
| 基准 | Pobf for 建议的 | Pobf for [11] | P_obf 改进百分比 |
|---|---|---|---|
| ARF | 0.55 | 0.43 | 22.36 |
| FIR | 0.75 | 0.50 | 33.33 |
| AUTO‐CO | 0.75 | 0.50 | 32.99 |
| DIF‐EQN | 0.72 | 0.50 | 30.62 |
| DHMC | 0.69 | 0.50 | 27.27 |
| Ada‐NC | 0.57 | 0.33 | 41.18 |
| Ada‐LMS | 0.88 | 0.50 | 42.86 |
所提出的方法与[11],在P_obf方面的比较结果如表V所示。从结果可以看出,基于多阶段的混淆方法提供了更强的知识产权保护,因为在所有测试的基准中,所提出的方法具有更高的P_obf值。此外,所提出的方法平均比[11]强22%。
VII. 结论
本文提出了一种新颖的低成本结构混淆方法,用于在算法综合过程中对基于循环的控制数据流图进行可重用IP核保护。这是首次尝试通过多阶段基于编译器的高层变换技术实现结构混淆。所提出的方法相比[11]具有更低的设计成本和更高的鲁棒性。此外,该方法不仅实现了低设计成本和高知识产权保护,还提供了短实现时间和易于适配任何CAD工具的优点。
我们未来的研究方向包括在算法综合过程中,利用结构和功能混淆来保护可重用IP核。我们计划增加更多变换,以实现更稳健的混淆设计。


















 25
25

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









