



一种基于边缘计算的时空相关性短时交通流量预测方法✩
摘要
准确且快速的短时交通流量预测在未来智慧城市的建设中发挥着至关重要的作用。为解决传统云端方案中存在的带宽消耗大、延迟高的问题,并提高交通预测的准确性与时效性,本文提出了一种新颖的三层云‐边‐端交通流量边缘计算架构,并在此基础上提出了一种基于时空相关性的短时交通流量预测方法(TFPM‐STC)。该方法采用主成分分析(PCA)分析交叉口之间的相关性,并利用卷积门控循环单元(Conv‐GRU)和双向门控循环单元(Bi‐GRU)提取交通流量的时空特征和周期性特征。实验结果表明,与现有方法相比,TFPM‐STC的平均绝对误差(MAE)和均方根误差(RMSE)平均降低了约16.5个点,同时在训练时间和预测时间上也有显著减少。
1. 引言
随着城市交通系统的快速发展,新一代协作式智能交通系统(C‐ITS)凭借移动互联、车路协同、自主高效等特性,已成为未来道路交通管理系统的关键推动力[1]。作为C‐ITS的重要组成部分,准确快速的短时交通流量预测信息不仅有助于人们规划出行路线、节省出行时间,从而减少交通拥堵和资源的不必要浪费,而且对未来智慧城市的建设具有重要作用,助力实现信息感知、深度互联、协同共享、智能处理和开放应用。
目前,短时交通流量预测方法在云中心[2,3],中进行处理,具有按需服务以及灵活可扩展的计算能力等优势[4]。然而,这种集中式模型在面对物联网世界时将面临重大挑战。
• 数据积累的体积和速度 :短时交通流量预测需要物联网设备从边缘设备向远程收集海量的交通数据。以11个交叉口区域为例,地磁传感器每天收集15,840条数据,一年将收集约570.24万条数据。假设每五分钟进行一次短时交通流量预测,如此庞大的数据将持续上传至云中心。
• 由于物联网设备与数据中心之间的距离导致的延迟 :分布在道路两侧的地磁传感器和路侧单元(RSU)距离云端较远。如果物联网设备数量出现指数级增长(这是很有可能的),那么可以想象,高延迟将是一个巨大的挑战。
幸运的是,作为云计算的有力补充,边缘计算可以将部分数据处理置于靠近采集数据的物联网设备的网络边缘,而不是在云中心进行。这不仅缓解了核心骨干网络的网络拥塞,还降低了网络延迟[5,6]。我们将边缘计算的概念引入短时交通流量预测中。然而,在同一区域的众多交叉口中,哪些交叉口会影响观测交叉口交通流量的预测值?影响程度如何?这一点至关重要,但此前的研究却忽视了这一问题。例如,在交通网络中,当某个交叉口发生拥堵时,其邻近交叉口的交通流量也会增加。
为了解决上述挑战,我们提出了一种新颖的三层云‐边‐端交通流量边缘计算架构,如图1所示。此外,受[7],利用空间邻域信息构建邻接图的启发,我们开发了一种基于时空相关性的短时交通流量预测方法(TFPM‐STC),用于发现交叉口交通流量之间的相关性。本文的主要贡献如下:
• 我们提出了一种新颖的交通流量边缘计算架构。利用边缘计算靠近终端且响应实时的优势,在物联网层通过地磁传感器采集数据,而在边缘层由高性能RSU的边缘服务器完成数据预处理和交通流量预测。
• 我们开发了TFPM‐STC,其中首先使用主成分分析(PCA)分析交叉口的相关性,然后利用卷积神经网络(CNN)提取交通流量的空间特征,采用门控循环单元(GRU)提取包含空间信息的时间特征,并使用双向门控循环单元(Bi‐GRU)提取交通流量的周期性特征。最后,通过全连接层融合这些提取的特征。据我们所知,这是首次将Conv‐GRU和Bi‐GRU模型应用于短时交通流量预测。
• 所提出的TFPM‐STC方法具有良好的迁移能力,能够适应不同的交通场景。我们使用真实世界数据集进行了广泛的对比实验。实验结果表明,与其他现有方法相比,TFPM‐STC具有很强的竞争力。
本文的其余部分组织如下。第2节回顾相关工作。第3节描述系统架构。第4节介绍数据预处理的细节。此外,我们在第5节详细阐述用于短时交通流量预测的模型。第6节展示实验结果和讨论。最后,第7节对全文进行总结。

2. 相关工作
在过去的几十年中,学者们提出了许多短时交通流预测方法,主要基于时间序列、统计概率和机器学习。
基于时间序列的交通流量预测方法
Vasantha 等人提出了一种基于季节性差分自回归积分滑动平均(ARIMA)模型的短时交通流量预测方法,用于预测不同季节的交通流量 [8]。陈等人提出了一种结合广义自回归条件异方差的自回归积分滑动平均模型(ARIMA‐GARCH)来预测交通流量 [9]。该方法将线性ARIMA模型与非线性GARCH模型相结合,以捕捉交通流量序列的条件均值和条件异方差性,进而用于交通流量预测。
基于统计概率的短时交通流量预测方法
赵等人提出了一种四阶高斯过程动态模型(GPDM),其中潜在变量为四阶马尔可夫高斯过程。该模型引入了加权K‐最近邻(K‐NN)算法,以有效预测潜在变量,然后利用GPDM和K‐NN预测结果的平均值来估计交通流量[10]。考虑到时间、空间维度以及交通流量的速度,朱等人提出了一种采用线性条件高斯贝叶斯网络模型的方法预测短时交通流量[11]。然而,统计概率方法基于概率论和数理统计,建模与求解过程较为复杂,且该方法对数据分布较为敏感,这也导致了预测模型的稳定性较差。
基于机器学习的短时交通流量预测方法
与传统的单步预测方法相比,张等人提出的基于支持向量机(SVM)的多步交通流量预测方法能够准确预测某一时间点的交通状态趋势[13]。冯等人提出了一种基于时空相关性自适应多核支持向量机(AMSVM‐STC)的预测方法,该方法首先将高斯核与多项式核混合构成AMSVM,然后利用粒子群优化算法优化参数,从而使混合核权重能够根据实时交通流量趋势进行自适应调整,实现对短时交通流量的准确预测[14]。吕等人提出了一种基于堆叠自动编码器(SAE)的预测方法,采用贪婪分层无监督学习算法进行逐层训练,使预测结果更加快速和准确[15]。然而,基于机器学习的预测方法在处理大规模交通数据时存在较大困难。
近年来,深度学习的快速发展为短时交通流量预测提供了更多样化的方法。邵等人提出了一种基于长短期记忆(LSTM)网络的预测方法。该方法利用LSTM捕捉时间序列数据中长期依赖性的固有特征,从而获得适合非线性交通流的预测结果[16]。杨等人提出了一种改进的LSTM方法,将序列时间步中的高影响值连接到当前时间步,并使用注意力机制捕获这些高影响的交通流量值,从而取得了良好的效果[17]。戴等人提出了DeepTrend模型,该模型由一个能够提取交通流量时变趋势的提取层和一个使用LSTM网络计算并输出时变趋势的预测层组成。与单一的LSTM模型相比,该方法可以更准确地预测短时交通流量数据[18]。张等人提出了一种基于 GRU[19]的预测方法。本文使用的模型由于少一个门结构,比LSTM更简单且更快[20]。
由于LSTM和GRU模型只能处理时间序列,因此仅使用LSTM或GRU模型无法全面分析交通流量的时空特征。因此,其交通流量预测精度不如基于时空相关性的方法。参考文献[7]引入了空间邻域的概念,以提取图像中的局部特征并获得样本点之间的相似性。但与[7],不同的是,本文中的时空相关性是通过深度学习中的CNN和GRU提取其空间和时间特征,然后利用全连接层融合时空特征。
罗等人提出了一种KNN‐LSTM方法,其中KNN用于选择与预测站点最相关的邻居,以捕捉空间特征,而双层LSTM网络用于预测交通流量,捕捉交通流量的时间特征[21]。吴等人提出了一种基于CNN和LSTM组合的短时交通流量预测方法,称为CNN‐LSTM方法,该方法使用LSTM提取时间特征和周期性特征,使用CNN提取交通流量的空间特征,并融合上述三种特征以得到最终的预测结果[22]。CNN还可以在遥感[23]领域进行空间信息建模。然而,这种方法的缺点是使用LSTM和CNN模型无法充分整合所产生的交通流量特征。为避免此问题,[24]中提出了卷积长短期记忆网络(Conv‐LSTM),将CNN和LSTM网络集成到一个模型中,并应用双向长短期记忆网络(Bi‐LSTM)来提取交通流量的周期性特征。此外,还有一些其他组合的短时交通流预测方法,例如[25]中的深度置信网络(DBN)。
3. 系统架构
我们将短时交通流量预测部署到三层云‐边‐端交通流量边缘计算架构中,如图1所示。物联网层由配置在每个交叉口的地磁传感器组成,负责采集并上传交通数据至边缘层。在中国的大中型城市,几乎每个交叉口都安装有地磁传感器,因此采集的数据量巨大。部署在关键交通区域的路侧单元构成边缘层。路网被划分为多个独立区域,每个区域包含一个路侧单元或边缘服务器以及约10个交叉口。
如何划分路网并非本文的重点,由于篇幅限制,此处不再赘述。各路侧单元基于获取的交通流量数据,分析交叉口相关性,训练模型并进行交通流量预测。云中心汇集整个路网所有路侧单元提供的数据。当路侧单元发生故障时,云端将替代其完成数据预处理和交通流量预测任务。
TFPM‐STC 包含两个部分:数据预处理和交通流量预测。数据预处理部分包括缺失值和异常值处理模块以及交叉路口相关性分析模块;交通流量预测部分包括时空特征和周期性特征的提取。如图2所示,流程如下:
• 使用均值法和阈值法处理缺失值和异常值。
• 将处理后的原始数据映射到矩阵中,并使用主成分分析来分析交叉口的相关性。
• 相关交叉路口的原始交通流量数据被映射为矩阵后,输入至Conv‐GRU和双向门控循环单元模型,以提取时空特征和周期性特征。
• 使用均方误差函数进行误差分析,持续调整模型,最终预测精确的交通流量数据。

4. 数据预处理
在中国的大多数城市,地磁传感器几乎无处不在,其主要作用是提取各种交通数据(如流量、速度和车道占有率)。由于整体路面沉降或恶劣天气等原因,会导致传感器发生转动、损坏和腐蚀,从而引起数据丢失或异常。因此,在进行交通预测之前,有必要对缺失值和异常值进行处理。地磁传感器每五分钟采集一次交通流量数据,一天共有288个五分钟,因此可以在交叉口 $ r’ $ 采集全天各个时间点的交通流量数据,记为 $ F_{r’} = [f_{r’}^1, f_{r’}^2, f_{r’}^3, …, f_{r’}^{288}] $,其中 $ f_{r’}^i $ 表示交叉口 $ r’ $ 在第i个五分钟的交通流量数据。类似地,我们在上述公式中选择某一时刻 $ t’ $ 作为观测时间点,则 $ t’-1 $ 为前一时间点,$ t’-288 $ 为昨日同一时刻,$ t’-576 $ 为前日同一时刻。
4.1. 缺失值处理
针对缺失值问题,我们采用均值法,该方法适用于交通流量等区间数据集。本文所用数据集的缺失值约占 2.4%−2.8%,而均值法对预测结果的准确性影响较小。其主要思想是:当连续缺失值不超过5个时,使用前两个数据的平均值来填充缺失数据。例如,我们将交通流量的缺失值设为 $[f_{r’}^{t’}, f_{r’}^{t’+1}, …, f_{r’}^{t’+n’}]$,其中 $ r’ $ 是交叉口,$ t’ $ 是时间点(检测器采样间隔为5分钟),$ n’ $ 是[1, 4]中的一个整数,因此第一个缺失值为 $ f_{r’}^{t’} = \frac{1}{2}(f_{r’}^{t’-2} + f_{r’}^{t’-1}) $,第二个缺失值为 $ f_{r’}^{t’+1} = \frac{1}{2}(f_{r’}^{t’-1} + f_{r’}^{t’}) $,依此类推。
对于连续缺失值数量超过5的情况,使用前两天对应时刻交通流量的平均值进行填充,即例如,仍将缺失值设为 $[f_{r’}^{t’}, f_{r’}^{t’+1}, …, f_{r’}^{t’+n’}]$,其中 $ n’> 4 $,第一个缺失值为 $ f_{r’}^{t’} = \frac{1}{2}(f_{r’}^{t’-576} + f_{r’}^{t’-288}) $,依此类推。
4.2. 异常值处理
针对异常值问题,我们确定了一个交通流量阈值。当某一时间的交通数据超过或低于该阈值(即当前交叉口可通过的最大交通流量)时,这些数据被视为异常值并予以剔除。随后,我们采用上述均值法对其进行填充。然而,异常值的定义不能仅以是否超过交叉口可通过的最大交通流量作为唯一判断条件。在实际交通场景中,即使部分交通数据未超过交叉口可通过的最大交通流量,其瞬时交通流量值仍可能显著高于或低于相邻交通流量值。针对这种情况,必须对具体问题进行详细分析,将存在问题的交通流量置于每个具体交通场景中进行探究。关键过程如下:
Step 1 : 我们为每个交叉口设置每小时最大交通流量值 $ Q_{r’}^{\text{max}} $
$$
Q_{r’}^{\text{max}} = \frac{3600}{t’_0} = \frac{1000 \cdot \bar{v}}{l’_0}
$$
其中,$\bar{v}$ 表示通过该交叉口的所有车辆的平均速度,$t’_0$ 表示最小车头时距(秒),即相邻车辆通过交叉口的最小时间差,$l’_0$ 表示与前车前端的最小距离(米),即相邻车辆之间的距离,则每五分钟最大交通流量值为,
$$
Q_{r’}^{\text{5min}} = \frac{Q_{r’}^{\text{max}}}{12}
$$
步骤2 :如果当前交通流量值 $ f_{r’}^{t’} $ 超过最大交通流量值 $ Q_{r’}^{\text{5min}} $,我们认为当前时刻的交通数据为异常值,将其移除并通过缺失值处理进行填充。
步骤3 :如果当前交通流量值 $ f_{r’}^{t’} $ 未超过 $ Q_{r’}^{\text{5min}} $,则下一个时间点 $ f_{r’}^{t’+1} $ 的交通数据范围应为:
$$
f_{r’}^{t’+1} \leq c \cdot \max{f_{r’}^{t’-288}, f_{r’}^{t’-576}, …, f_{r’}^{t’-2016}}
$$
$$
d \cdot \max{f_{r’}^{t’-288}, f_{r’}^{t’-576}, …, f_{r’}^{t’-2016}} \leq f_{r’}^{t’+1}
$$
其中 $ c > 1, 0 < d < 1 $ 和 ${f_{r’}^{t’-288}, f_{r’}^{t’-576}, …, f_{r’}^{t’-2016}}$ 是上周每天同一时刻的交通数据。
如此设置的原因是交通流量是动态的,并会受到多种因素的影响,因此应将阈值调整到更大的范围,以避免因突发事件或不可控因素而导致的 “正确”交通流量值被误删。
4.3. 交叉口相关性分析
尽管可以通过直接观察获得交叉口的相邻关系,但当交叉口不相邻时,我们是否仍能观察到其潜在关系?我们使用主成分分析并非为了证明交叉口之间的直接关系,而是为了充分分析那些无法通过直观感知探索的交叉口之间的潜在联系。主成分分析能够在保证数据信息损失最小的原则下,降低高维变量空间的维度,从而抽象出交叉口之间的相关性,找到相关性最高的交叉口,以准确预测交通流量。
交叉口的相关性分析主要包括交通流量数据的标准化处理、数据样本相关矩阵的计算与建立、主成分的计算以及主成分的提取。
4.3.1. 数据标准化
原始交通流量数据是映射到一个 $ r \times t $ 的矩阵,其中 $ t $ 是交叉口交通流量数据的样本长度 $ n $ 且 $ r $ 是交叉口的数量项。原始交通流量数据矩阵可以表示为
$$
F =
\begin{bmatrix}
f_1^1 & f_1^2 & \cdots & f_1^t \
f_2^1 & f_2^2 & \cdots & f_2^t \
\vdots & \vdots & \ddots & \vdots \
f_r^1 & f_r^2 & \cdots & f_r^t \
\end{bmatrix}
= [f_1, f_2, …, f_r]^T
$$
其中 $ f_r^t $ 表示交叉口 $ r $ 在 $ t $ 时刻的交通流量数据。
为了直接评估指标,需要对数据进行标准化处理。我们使用零均值归一化方法对交通数据进行相应处理,使数据样本的平均值为 0,方差为1,得到的标准化数据样本为
$$
F’ = \frac{F - \mu}{\delta}
$$
其中
$$
F’ =
\begin{bmatrix}
f’
{11} & f’
{12} & \cdots & f’
{1t} \
f’
{21} & f’
{22} & \cdots & f’
{2t} \
\vdots & \vdots & \ddots & \vdots \
f’
{r1} & f’
{r2} & \cdots & f’_{rt} \
\end{bmatrix}
= [f’_1, f’_2, …, f’_r]^T
$$
$$
\mu = (\mu_1, \mu_2, …, \mu_r)^T
$$
其中 $ \mu_1 = \frac{1}{t} f_1, \mu_2 = \frac{1}{t} f_2, …, \mu_r = \frac{1}{t} f_r $ 表示数据样本的均值。
$$
\delta = (\delta_1, \delta_2, …, \delta_r)^T
$$
其中 $ \delta_1 = \frac{1}{t-1}(f_1 - \mu_1), \delta_2 = \frac{1}{t-1}(f_2 - \mu_2), …, \delta_r = \frac{1}{t-1}(f_r - \mu_r) $ 表示数据样本的方差。
4.3.2. 数据样本相关矩阵的计算与建立
标准化数据样本矩阵的协方差矩阵即为相关系数矩阵,它表示样本之间的相关性,交叉口 $ i $ 与 $ j $ 之间的相关系数表示为
$$
\rho_{ij} = \frac{1}{t - 1} \sum_{n=1}^{t} F’
{ni} F’
{jn}, \quad 1 \leqslant i \neq j \leqslant r, \quad 1 \leqslant n \leqslant t
$$
相关系数矩阵表示每个交叉口之间的相关程度,表示为
$$
R = \frac{1}{t - 1} F’ F’^T
$$
当 $ 0 < |\rho_{ij}| \leqslant 1 $ 时,交叉口之间存在线性关系,且当 $ |\rho_{ij}| $ 越接近1时,线性关系越强,反之亦然。当 $ |\rho_{ij}| = 0 $ 时,交叉口之间不存在线性关系。
4.3.3. 主成分的计算
相关系数矩阵 $ R $ 可用于获取特征值 $ \lambda_1 \geq \lambda_2 \geq \cdots \geq \lambda_r \geq 0 $ 和正交特征向量 $ q_1, q_2, …, q_r $,这些特征向量构成矩阵 $ Q $:
$$
Q = [q_1, q_2, …, q_r]^T
$$
我们可以获得 $ r $ 个主成分的信息
$$
Y = [Y_1, Y_2, …, Y_r]^T = Q^T F’^T
$$
特征值 $ \lambda_m (m = 1, 2, …, r) $ 是相应主成分 $ Y_m $ 的方差。方差越大,对总方差的贡献越大,贡献率表示为 $ a_m = \frac{\lambda_m}{r} $。贡献率是选择有效主成分的关键因素。贡献率的值决定了主成分解释其他变量的能力。贡献率越高,主成分解释其他变量的能力越强,反之则越弱。此外,累计贡献率是特征值的总和,因此累计贡献率是
$$
a = \sum_{m=1}^{r} a_m
$$
4.3.4. 主成分提取
通过计算累计贡献率,可以相应地提取主成分。通常情况下,如果前 $ r $ 个主成分的累计贡献率达到85%或以上,则符合PCA算法的规定。前 $ r $ 个主成分被认为反映了 $ r $ 个交叉口大部分的信息,前 $ r $ 个主成分表示为
$$
\begin{cases}
Y_1 = q_1^T (F’_1)^T \
Y_2 = q_2^T (F’_2)^T \
\vdots \
Y_m = q_m^T (F’_m)^T \
\end{cases}, \quad 1 \leq m \leq r
$$
5. 交通流量预测
对于短时交通流量预测,本文使用Conv‐GRU提取交通流量的时空特征,并使用双向门控循环单元提取交通流量的周期性特征,从而充分融合交通流量的时空特征和周期性特征,同时提高模型的收敛速度。
短时交通流量预测部分主要包括数据构建、Conv‐GRU模型和双向门控循环单元模型。
5.1. 数据构建
通过使用主成分分析(PCA)来分析各个交叉口的相关性,我们可以获取与预测交叉口具有较强相关性的交叉口信息。我们将这些交叉口的交通数据映射到一个矩阵中,将预测点的交通数据置于矩阵中心,并根据其他点与预测点之间的距离,用相应位置的交通数据填充该交通矩阵。利用深度学习模型对交通矩阵进行分析,以发现预测点与其他点之间的空间相关性。空间信息矩阵可表示为
$$
F’
{t’} = (f_1, f_2, f_3, …, f
{r’})
$$
其中 $ t’ $ 表示某个时间点 $ 0 \leq t’ \leq 288 $,$ r’ $ 表示一个交叉口 $ 0 < r’ < r $。因此,$ F’_{t’} $ 表示在时间点 $ t’ $ 所有交叉口的交通流量。不同时间点的空间信息矩阵可以组合为
$$
F_{\text{today}} =
\begin{bmatrix}
f_1^1 & f_2^1 & \cdots & f_{r’}^1 \
f_1^2 & f_2^2 & \cdots & f_{r’}^2 \
\vdots & \vdots & \ddots & \vdots \
f_1^{t’} & f_2^{t’} & \cdots & f_{r’}^{t’} \
\end{bmatrix}
$$
矩阵 $ F_{\text{today}} $ 中的 $ f_{r’}^{t’} $ 表示交叉口 $ r’ $ 在时间点 $ t’ $ 的交通流量值。
因此,具有周期性的交通数据可以表示为:
$$
F_{\text{yesterday}} =
\begin{bmatrix}
f_1^{-1} & f_2^{-1} & \cdots & f_{r’}^{-1} \
f_1^{-2} & f_2^{-2} & \cdots & f_{r’}^{-2} \
\vdots & \vdots & \ddots & \vdots \
f_1^{-t’} & f_2^{-t’} & \cdots & f_{r’}^{-t’} \
\end{bmatrix}
$$
$$
F_{\text{week}} =
\begin{bmatrix}
f_1^{-7} & f_2^{-7} & \cdots & f_{r’}^{-7} \
f_1^{-7
2} & f_2^{-7
2} & \cdots & f_{r’}^{-7
2} \
\vdots & \vdots & \ddots & \vdots \
f_1^{-7
t’} & f_2^{-7
t’} & \cdots & f_{r’}^{-7
t’} \
\end{bmatrix}
$$
其中,矩阵 $ F_{\text{yesterday}} $ 中的 $ f_{r’}^{-t’} $ 表示交叉口 $ r’ $ 在昨天同一时刻的交通流量值。矩阵 $ F_{\text{week}} $ 中的 $ f_{r’}^{-7*t’} $ 表示交叉口 $ r’ $ 在上周同一时刻的交通流量值。
5.2. Conv-GRU模型
数据格式化后,交通数据矩阵被输入到深度学习模型中,该模型包括Conv‐GRU模型和双向门控循环单元模型,如图3所示。图4展示了Conv‐GRU模型,其中 $ F_{t’} = (f_1, f_2, f_3, …, f_{r’}) $ 表示预测点在同一时间点邻近区域的其他交通流量值 $ t’ $。使用Conv‐GRU模型提取时空特征的步骤如下:
Step 1 : 使用一维使用多维卷积处理每个元素 $ F’_{t’} $。
通过滑动滤波器在数据矩阵上进行滑动卷积,获取局部感知域中的卷积信息。本文使用的卷积核为3,滑动步数为1。
首先,如图5(a)所示,交通流量数据 $(f_1^1, f_1^2, f_1^3)$,矩阵 $ F_{\text{today}} $ 第一行的前三列,与滤波器 $(\text{filter}_1, \text{filter}_2, \text{filter}_3)$ 逐元素相乘以获得卷积值:
$$
A_1 = f_1^1 * \text{filter}_1 + f_2^1 * \text{filter}_2 + f_3^1 * \text{filter}_3
$$

其次,如图5(b)所示,交通流量数据 $(f_1^2, f_1^3, f_1^4)$,矩阵第一行的第二至第四列,与滤波器 $(\text{filter}_1, \text{filter}_2, \text{filter}_3)$ 相乘以获得卷积值:
$$
A_2 = f_2^1 * \text{filter}_1 + f_3^1 * \text{filter}_2 + f_4^1 * \text{filter}_3
$$
通过一个同理,最终得到整个交通流量数据的卷积值 $ A = (A_1, A_2, A_3, …) $。
步骤 2 :聚合所有卷积值以形成交通流量数据的空间特征。
$$
g(i) = R(A_i w + B)
$$
其中 $ A $ 是输入节点的卷积值,$ w $ 是节点的滤波器权重,$ B $ 是偏置项,$ g(i) $ 是卷积后的空间特征,$ R $ 是激活函数。本文采用 Relu 激活函数。由于Relu函数的求导过程相对简单,其反向传播的收敛速度更快。公式如下:
$$
f(x) = \max(0, x)
$$
步骤3 :使用平均池化技术来合并并减少卷积层中获得的空间特征。
通过平均池化 $ g $ 技术,组合维度大大减少,从而可以消除不必要的信息 $ e $ 滤波器以获得更抽象的 $ t $ 空间特征。平均池化如图6所示。
矩阵中带有空间特征的每一行代表一个时间段,因此第一个和第二个时间点的池化特征是:
$$
C_1 = \frac{g(1) + g(2) + \cdots + g(b)}{b}
$$
$$
C_2 = \frac{g(a) + g(a+1) + \cdots + g(2b)}{2b - a + 1}
$$
类比地,可以在第 $ t’ $ 个时间点池化后的特征得到:
$$
C_{t’} = \frac{g(c) + g(c+1) + \cdots + g(t’b)}{t’b - c + 1}
$$
其中 $ a $、$ b $ 和 $ c $ 均为正整数,且 $ c > b > a $。
步骤4 :将卷积和池化的空间特征输入到门控循环单元模型中,以形成交通流量的时空相关性。
在对交通流量数据进行卷积和池化处理后,我们得到一个具有空间特征的时间序列矩阵 $ C = (C_1, C_2, …, C_{t’}) $,用作门控循环单元模型的输入。
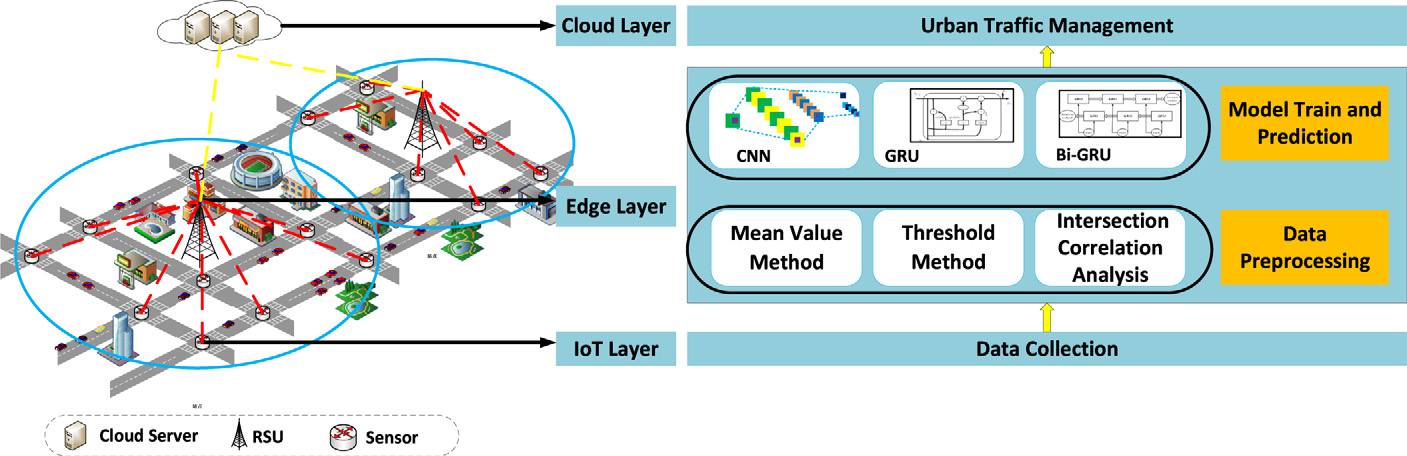
如图7所示,门控循环单元模型结构包含两个门:更新门和重置门。更新门用于控制前一时刻的状态信息带入当前状态的程度。更新门的值越大,带入前一时刻的状态信息越多。重置门用于控制忽略多少当前状态信息。重置门的值越小,被忽略的信息越多。
- 前一时刻的状态信息 $ h_{t’-1} $ 和当前输入 $ x_{t’} $ 到重置门共同决定哪部分信息被丢弃:
$$
\text{reset}
{t’} = \sigma(W
{\text{reset}} \cdot [h_{t’-1}, x_{t’}] + b_{\text{reset}})
$$
其中 $ \text{reset} {t’} $、$ W {\text{reset}} $ 和 $ b_{\text{reset}} $ 分别是重置门的输出、权重和偏置项。
- 将 $ h_{t’-1} $ 和 $ x_{t’} $ 发送到更新门以确定哪部分信息需要更新:
$$
\text{update}
{t’} = \sigma(W
{\text{update}} \cdot [h_{t’-1}, x_{t’}] + b_{\text{update}})
$$
其中 $ \text{update} {t’} $、$ W {\text{update}} $ 和 $ b_{\text{update}} $ 分别是更新门的输出、权重和偏置项。
- 将激活函数Tanh应用于 $ \text{reset} {t’} $ 和 $ x {t’} $,生成候选状态信息 $ \tilde{h}_{t’} $,将其阈值降低至 -1 和 1 之间:
$$
\tilde{h}
{t’} = \tanh(W_h \cdot [\text{reset}
{t’} * h_{t’-1}, x_{t’}] + b_h)
$$
其中 $ W_h $ 和 $ b_h $ 分别是中间状态的权重和偏置项。
- 通过丢弃 $ h_{t’-1} $ 并保留 $ \tilde{h} {t’} $ 来生成当前状态信息 $ h {t’} $:
$$
h_{t’} = (1 - \text{update}
{t’}) * h
{t’-1} + \text{reset}
{t’} * \tilde{h}
{t’}
$$
- 通过对 $ h_{t’} $ 使用sigmoid激活函数,我们可以获得一个聚合了空间相关性的时间特征序列。
$$
y_{t’} = \sigma(W_o \cdot h_{t’})
$$
$$
\sigma = \frac{1}{1 + e^{-x}}
$$
其中 $ \sigma $ 是激活函数,$ W_o $ 是输出周期的权重。

5.3. 双向门控循环单元模型
由于交通流量具有明显的周期性特征,本文使用双向门控循环单元模型来提取交通流量的周期性特征。双向门控循环单元模型需要预测时间点的前后向信息以提高准确性,但只能利用历史数据来预测下一个时间点的交通流量,因此我们选择昨天和上周同一时刻的数据作为模型输入,以提取周期性特征。双向门控循环单元模型如图8所示。
双向门控循环单元模型由向上和向下堆叠的单向GRU模型组成,其原理与单向GRU模型相同。因此,双向门控循环单元模型需要两个时间序列输入,最终输出结果(即交通流量的周期性特征)由前向输出和反向输出共同决定。
5.4. 损失函数
使用上述模型分别提取时空特征和周期性特征,将所有特征按顺序连接到特征矩阵中,并输入全连接层进行预测。在预测训练中,我们采用均方误差(MSE)作为损失函数,以准确描述真实值与预测值之间的差异:
$$
\text{MSE} = \frac{1}{n} \sum_{t’=1}^{n} (F_{\text{prediction}} - F_{\text{true}})^2
$$
其中 $ F_{\text{prediction}} $ 是短时交通流量的预测值,$ F_{\text{true}} $ 是交通流量的真实值。然后我们使用Root Mean Square Prop优化算法来优化深度神经网络。通过设置一个超参数,Root Mean Square Prop优化算法可以自适应地调整学习率,从而防止损失函数在更新时出现大幅波动,并进一步加快函数的收敛。
6. 实验
6.1. 实验环境
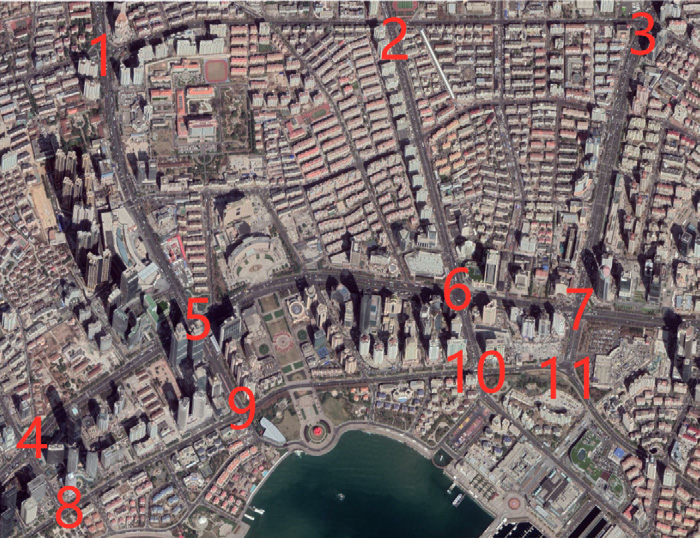
为了验证TFPM‐STC的可行性,我们分析了2019年1月1日至2019年6月30日中国青岛11个交叉口的地磁传感器收集的交通流量数据,其中检测器每五分钟提取一次交通数据。原始数据的格式如表1所示。图9显示了青岛市区南区的部分卫星地图。图中标记的数字1至11代表11个交叉口,对应的名称见表2。
所有测试均在一台配备Intel(R) Xeon(R) CPU E5‐2650 v4@2.20 GHz和250 GB内存的Windows电脑上实现。
| 路口编号 | Time | Flow |
|---|---|---|
| 1 | 2019/1/1 0:00 | 204 |
| 1 | 2019/1/1 0:05 | 229 |
| 1 | 2019/1/1 0:10 | 237 |
| 1 | 2019/1/1 0:15 | 248 |
| … | … | … |
| 2 | 2019/1/1 0:00 | 132 |
| 2 | 2019/1/1 0:05 | 120 |
| 2 | 2019/1/1 0:10 | 145 |
| 2 | 2019/1/1 0:15 | 152 |
| … | … | … |
表1 数据格式
| No. | 交叉口名称 |
|---|---|
| 1 | 山东路和江西路 |
| 2 | 南京路和江西路 |
| 3 | 福州南路和江西路 |
| 4 | 香港西路和延安三路 |
| 5 | 香港西路和山东路 |
| 6 | 香港中路和南京路 |
| 7 | 香港中路和福州南路 |
| 8 | 东海西路和延安三路 |
| 9 | 东海西路和山东路 |
| 10 | 东海西路和南京路 |
| 11 | 东海西路和福州南路 |
表2 对应交叉口
6.2. 结果分析与评价
6.2.1. 交叉口相关性分析
对预处理后的交通流量数据进行分析,并按照第4.3节中的步骤处理,以获得相关系数矩阵、特征值以及由特征值转换得到的累计贡献率和碎石图检验结果。在表3中,交叉口1与交叉口2的相关系数为0.97(接近1),表示二者具有强相关性;而交叉口1与交叉口3的相关系数为 −0.08(接近0),表示二者具有弱相关性。碎石图检验用于确定主成分的数量。主成分的选择可通过直接观察特征的变化来判断。当某个特征值的下降斜率比后续的更快时,对应于此特征值的主成分能够解释更多在附加交叉口上的信息,如图10所示。
根据表4,选择前两个主成分在交叉口进行相关性分析。由于前两个主成分的累计贡献率达到89.208%,已超过85%,因此认为前两个主成分已经能够充分解释其他变量的信息。使用前两个主成分作为横纵坐标,绘制了11个交叉口的相关性分析图,如图11(a)和图11(b)所示。
| 交叉点 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 1.00 | 0.97 | −0.08 | 0.35 | 0.97 | 0.94 | 0.93 | 0.88 | 0.94 | 0.93 | 0.95 |
| 2 | 0.97 | 1.00 | −0.10 | 0.35 | 0.96 | 0.94 | 0.92 | 0.88 | 0.94 | 0.93 | 0.95 |
| 3 | −0.08 | −0.10 | 1.00 | 0.18 | −0.87 | −0.07 | −0.06 | −0.03 | −0.07 | −0.07 | −0.06 |
| 4 | 0.35 | 0.35 | 0.183 | 1.00 | 0.36 | 0.37 | 0.35 | 0.45 | 0.39 | 0.39 | 0.41 |
| 5 | 0.97 | 0.96 | −0.87 | 0.36 | 1.00 | 0.95 | 0.93 | 0.89 | 0.96 | 0.94 | 0.96 |
| 6 | 0.94 | 0.94 | −0.07 | 0.37 | 0.95 | 1.00 | 0.90 | 0.88 | 0.94 | 0.93 | 0.93 |
| 7 | 0.93 | 0.92 | −0.06 | 0.35 | 0.93 | 0.90 | 1.00 | 0.84 | 0.90 | 0.89 | 0.92 |
| 8 | 0.88 | 0.88 | −0.03 | 0.45 | 0.89 | 0.88 | 0.84 | 1.00 | 0.94 | 0.94 | 0.94 |
| 9 | 0.94 | 0.94 | −0.07 | 0.39 | 0.96 | 0.94 | 0.90 | 0.94 | 1.00 | 0.97 | 0.97 |
| 10 | 0.93 | 0.93 | −0.07 | 0.39 | 0.94 | 0.93 | 0.89 | 0.94 | 0.97 | 1.00 | 0.97 |
| 11 | 0.95 | 0.95 | −0.06 | 0.41 | 0.96 | 0.93 | 0.92 | 0.94 | 0.97 | 0.97 | 1.00 |
表3 每个交叉口的相关系数
| 成分 | 总计 | 方差 | CCR |
|---|---|---|---|
| 1 | 8.663 | 78.752 | 78.752 |
| 2 | 1.150 | 10.456 | 89.208 |
| 3 | 0.689 | 6.268 | 95.476 |
| 4 | 0.200 | 1.819 | 97.295 |
| 5 | 0.088 | 0.803 | 98.098 |
| 6 | 0.066 | 0.597 | 98.695 |
| 7 | 0.046 | 0.422 | 99.117 |
| 8 | 0.031 | 0.282 | 99.399 |
| 9 | 0.027 | 0.244 | 99.643 |
| 10 | 0.021 | 0.191 | 99.834 |
| 11 | 0.018 | 0.166 | 100.000 |
表4 累计贡献率和主成分提取
从图11(a)可以看出,交叉口3和交叉口4远离其他9个交叉口,因此它们之间的相关性较小。图11(b)显示交叉口1与交叉口5、交叉口9与交叉口10彼此非常接近,表明它们各自具有高度相关性。为了验证结果分析的合理性和真实性,我们选取了2019年1月7日交叉口5、交叉口1和交叉口3的交通流量,以及4月13日交叉口9、交叉口10和交叉口4的交通流量。
图12和图13验证了应用主成分分析来分析交叉口相关性是可行的。我们可以看到,交叉口5(或9)的交通流量变化与交叉口1(或10)非常相似,但与交叉口3(或4)有很大差异。
6.2.2. TFPM-STC的性能
为了评估我们方法的准确性,我们使用两个评价指标,即平均绝对误差和均方根误差来评估预测结果。
$$
\text{MAE} = \frac{1}{n} \sum_{t’=1}^{n} |F_{\text{prediction}} - F_{\text{true}}|
$$
$$
\text{RMSE} = \sqrt{\frac{1}{n} \sum_{t’=1}^{n} (F_{\text{prediction}} - F_{\text{true}})^2}
$$
为了验证使用主成分分析(PCA)的有效性,我们选择了与交叉口6相关性较高的交叉口1、2、5、9、10和11,用于预测交叉口6的交通流量。同时,我们还采用了另外六种方法进行对比:卷积长短期记忆网络、卷积神经网络‐门控循环单元、卷积神经网络‐长短期记忆网络、门控循环单元、长短期记忆网络和自编码器。如表5–7所示,TFPM‐STC在平均绝对误差和均方根误差上低于卷积神经网络‐长短期记忆网络、卷积神经网络‐门控循环单元、门控循环单元、长短期记忆网络和自编码器,并且与卷积长短期记忆网络基本相当。
| 方法 | MAE | RMSE |
|---|---|---|
| TFPM‐STC | 20.583512 | 34.672275 |
| 卷积长短期记忆网络 | 21.521886 | 34.879082 |
| 卷积神经网络‐门控循环单元 | 26.330207 | 42.756271 |
| 卷积神经网络‐长短期记忆网络 | 27.573333 | 44.387996 |
| GRU | 29.296396 | 48.180921 |
| LSTM | 29.077977 | 48.033351 |
| SAE | 31.001886 | 50.674397 |
表5 工作日交通流量预测中不同方法的性能
| 方法 | MAE | RMSE |
|---|---|---|
| TFPM‐STC | 19.685774 | 33.469362 |
| 卷积长短期记忆网络 | 19.870233 | 34.180574 |
| 卷积神经网络‐门控循环单元 | 26.282439 | 42.114516 |
| 卷积神经网络‐长短期记忆网络 | 28.538098 | 43.694584 |
| GRU | 30.161169 | 48.344626 |
| LSTM | 31.599086 | 53.343580 |
| SAE | 33.469120 | 54.360400 |
表6 不同方法在周末交通流量预测中的性能
| 方法 | MAE | RMSE |
|---|---|---|
| TFPM‐STC | 17.326838 | 30.509516 |
| 卷积长短期记忆网络 | 18.650344 | 31.131684 |
| 卷积神经网络‐门控循环单元 | 22.444296 | 35.747940 |
| 卷积神经网络‐长短期记忆网络 | 22.632027 | 36.241269 |
| GRU | 27.971130 | 40.533122 |
| LSTM | 28.701338 | 40.851350 |
| SAE | 30.656198 | 45.687741 |
表7 不同方法在节假日交通流量预测中的性能
为了更直观地展示预测结果的准确性,我们将TFPM‐STC与卷积神经网络‐长短期记忆网络、长短期记忆网络和自编码器进行比较。预测时间为2019年6月11日00:00至24:00、2019年6月22日00:00至24:00以及2019年5月1日(国际劳动节)00:00至24:00,如图14–16所示。
通过分析可知,TFPM‐STC在预测工作日和周末的交通流量时,其预测结果比CNN‐LSTM、LSTM和SAE方法更为准确。由于TFPM‐STC将卷积神经网络(CNN)和门控循环单元(GRU)集成到一个模型中,能够充分提取短时交通流量数据的时间和空间特征,而CNN‐LSTM方法无法做到这一点。此外,TFPM‐STC采用双向门控循环单元模型提取周期性特征,使得其预测结果比CNN‐LSTM方法更加准确。
长短期记忆网络仅适用于提取时间序列特征,不适合处理空间特征。TFPM‐STC能够处理时间特征、空间特征和周期性特征,因此其预测结果优于仅使用LSTM模型的方法。
在所有方法中,自编码器采用分层无监督学习算法进行训练,因此无法实现对交通特征的全局优化。并且每一层的训练方法相同,导致自编码器在训练多个神经层后出现多层增量失效。换句话说,随着训练层数的增加,其性能会迅速下降。因此,自编码器的预测精度相对较低。
根据图17和图18,TFPM‐STC结合PCA与卷积长短期记忆网络方法在预测性能和预测结果方面没有显著差异。然而,当两种方法的性能和预测结果相差不大时,TFPM‐STC结合PCA的每次迭代的训练时间和预测时间均少于卷积长短期记忆网络。其中,TFPM‐STC结合PCA在工作日数据、周末数据以及节假日数据上的训练时间相比卷积长短期记忆网络均有所减少,分别降低了26%、21%和23%。此外,与卷积长短期记忆网络相比,我们的方法在预测工作日、周末和节假日的交通流量时分别节省了18%、30%和38%的时间。主要原因是,与LSTM模型相比,门控循环单元模型少一个门控单元,这意味着门控循环单元模型的向量乘法运算少于LSTM。此外,我们的方法还使用主成分分析来分析交叉口之间的相关性,并提取出与待预测交叉口高度相关的其他交叉口作为预测数据。这不仅能够消除冗余数据的干扰,还能节省训练时间和预测时间。
7. 结论与未来工作
短时交通流量预测是交通出行引导和智能交通信号灯调控的关键。本文提出的基于边缘计算架构的短时交通流量预测方法,通过在网络的边缘层进行并行预处理和分析,满足了位置感知和低延迟的要求。此外,实验结果表明,该方法在准确性与响应速度方面均具有优势,即显著减少了训练数据量,缩短了训练时间和预测时间。
该方法具有巨大潜力,可帮助交通管理部门监控和控制交通状况以及自适应调节交通信号灯。未来工作可以考虑更多因素,如天气、社会活动和自然灾害,以进行更全面的预测。


















 646
646

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









