




 文章讲述了链表末尾插入节点的方法,迭代反转链表的两种策略,包括通过更改数据位和地址位,以及递归遍历和反转的思路和代码实现。讨论了各自的优缺点和注意事项。
文章讲述了链表末尾插入节点的方法,迭代反转链表的两种策略,包括通过更改数据位和地址位,以及递归遍历和反转的思路和代码实现。讨论了各自的优缺点和注意事项。
上一次的笔记:链表的插入和删除 👇
https://blog.youkuaiyun.com/Swillow_/article/details/131482366?spm=1001.2014.3001.5501
这次是P9-P11的笔记(超长文章预警!!!)
视频课程地址:👇
https://www.bilibili.com/video/BV1Fv4y1f7T1?p=11&vd_source=02dfd57080e8f31bc9c4a323c13dd49c
目录
链表末尾插入节点
之前我们说过在链表头部插入节点,在任意位置插入节点,接下来再写一种从链表末尾插入节点。以应对一些特殊需要。在之前的基础上,这个思想应该是很好理解的。
插入函数的思想: 想从末尾插入,就要找到链表中的最后一个节点,然后将插入的节点赋给最后一个节点的next,建立联系即可。
注意:当链表为空时,要做特殊处理(避免非法访问),如果为空,直接将新创建的节点赋值给head即可。
然后讨论一般情况:就要先创建一个新的节点 (局部变量) 来代替头节点进行链表的遍历 (这样避免头节点被修改导致丢失链表),以查找到最后一个节点,进行新的赋值。
#include <iostream>
using namespace std;
struct Node
{
int data;
Node *next;
};
struct Node *head;
void Insert(int x)
{
//创建该节点
struct Node *temp1 = new Node();
temp1->data = x;
temp1->next = NULL;
//如果链表为空,直接更新即可。如果不单独把链表为空的情况做特殊处理,访问地址会崩溃(非法)
if (head == NULL)
head = temp1;
else
{
//创建一个新的节点,遍历链表中的节点直到找到下一个地址为空的节点为止
Node *temp2 = head;
while (temp2->next != NULL)
temp2 = temp2->next;
//更新 插入的节点
temp2->next = temp1;
}
}
void Print()
{
Node *temp = head;
if (temp == NULL)
return;
while (temp != NULL)
{
cout << temp->data << " ";
temp = temp->next;
}
}
int main()
{
head = NULL;
Insert(2);
Insert(6);
Insert(7);
Print();
return 0;
}ok链表的插入算是各种情况都写过啦。
迭代反转链表
意思很好理解,就是想把链表中的数据逆序一下。
如下图,是我们想要的功能 (视频课程截图)
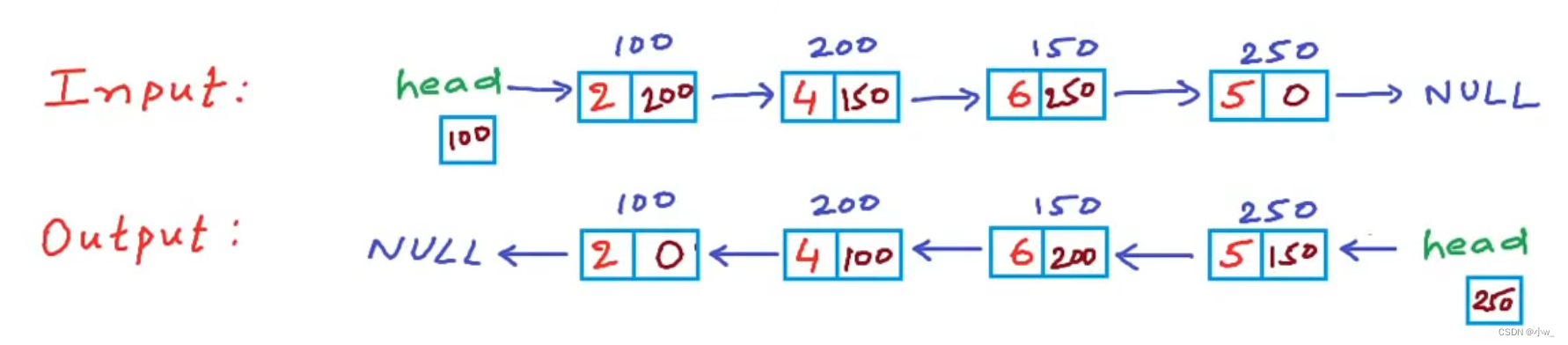 注意我们并不是通过更改每个节点数据的顺序来实现逆序,而是通过更改每个节点的地址位的地址指向来反转链表的。
注意我们并不是通过更改每个节点数据的顺序来实现逆序,而是通过更改每个节点的地址位的地址指向来反转链表的。
如下我将链表的两个元素称为数据位和地址位,分别解释两种方式:
更改数据位:
思路:
思想:如果想要把数据逆序,也就是,原来在第一位的,现在与最后一位n交换位置,原来在第二位的与第n-1位的数据进行交换...最终实现链表的逆序。...好丑
这样的话,我们首先要经过一个while循环,遍历整个链表,用于确定链表的长度,因为我们需要知道链表中有多少个节点,才能确定哪些节点需要交换数据。
第二次遍历用于实际交换数据。我们使用两个指针(p1 p2)来分别指向需要交换数据的两个节点。然后交换这两个节点中的数据,并将两个指针向中间移动一步,直到遍历完整个链表。
两个数据交换的写法我们已经很清楚了(借用一个局部变量,3个语句,实现两个数据的交换)。
两个指针向中间移动一步:这步操作是有点复杂的。左边的指针是往后更新,右边的指针是不断往前更新。第一个数据我们可以从head头节点开始,然后向后更新即可,而另一个节点的更新,将要更改为链表中的第 n-i 个节点( i 表示左半部分的节点),但是我们又没办法直接倒着得到这个节点的地址,所以我们只能令其初始位置为head,通过for循环得到,而循环条件就是从 i +1开始(因为我们想找到的是下一个交换数据的节点),到 i<n-i-1 即得到了我们想要的节点。
代码如下:
void reverse() {
//计算链表长度
int len = 0;
Node* temp = head;
while (temp != NULL) {
len++;
temp = temp->next;
}
if (len <= 1) return;
//创建两个指针
Node* p1 = head;
Node* p2 = head;
//右边指针初始位置是链表末尾
for (int i = 0; i < len - 1; i++) {
p2 = p2->next;
}
//由于都是向中间靠拢,所以判断条件是一半
for (int i = 0; i < len / 2; i++) {
//交换数据“三段式”
int t = p1->data;
p1->data = p2->data;
p2->data = t;
//更新左指针
p1 = p1->next;
//更新右指针
p2 = head;
for (int j = i + 1; j < len - i - 1; j++) {
p2 = p2->next;
}
}
}
优缺点:(bing的结果)
这种方法的优点在于它相对容易理解和实现。我们只需要遍历链表并交换数据,而不需要对链表结构进行修改。此外,这种方法也不需要额外的指针变量来存储链表中的地址信息。
然而,这种方法也有一些缺点。首先,它需要遍历整个链表两次:一次用于确定链表的长度,另一次用于交换数据。这会增加算法的时间复杂度。其次,当数据类型较大时,交换数据可能会比较耗时。此外,如果链表中的节点包含指向其他数据结构(如树或图)的指针,则通过交换数据来反转链表可能会破坏这些指针之间原有的关系。
更改地址位:
思路:
链表之间是通过地址位的指向来建立起联系的,那么我们通过更改这些地址之间的联系就可以实现反转链表。
思想:创建三个指针 prev(表示上一个节点) ,current(表示当前所在节点),next(表示下一个节点) 我们最终反转后的链表是存在prev里的。整体思路是,current从头节点开始遍历,那么prev的初始值应该是NULL (因为头节点的前一个节点就是空嘛),为了避免直接更改current之后丢失current后的数据地址 (导致无法遍历链表),我们要先将current->next的值赋给next,先存起来,然后将current与下一个节点之间的联系切断,建立起current和前一个节点之间的联系,接着要将上一个节点向后更新一位 (这样更新之后的current [是反转的] 就赋值给了prev),最后再把current向下更新一位。遍历完整个数组即可。我们将head指针指向原链表(prev)的最后一个节点,即新链表的第一个节点。
写的很长,但这就是反转链表核心程序的过程。想一想可以理解哦。
!!注意
我这里是把头节点定义为了局部变量(因为老师这样讲的hhh),所以函数的调用需要多一个参数传入链表的头节点 (获取链表),在函数内部对链表进行更改之后,比如:插入函数 (这里使用的是从链表头部插入数据) 就需要一个节点返回值,这样才能保证对初始链表的实际更改;反转函数需要返回反转之后的节点,这样才能保证实际链表真正被反转。
另外我写了一下定义为全局变量,其实也是可以的,只是我们反转函数中要通过 & 引用传入,这样就保证更改的是实际的链表,而不仅仅是局部变量。
这里就只展示局部变量的写法。
代码如下 :
#include <iostream>
using namespace std;
// 创建节点结构体
struct Node
{
int data;
struct Node *next;
};
// 从头部插入数据
struct Node *Insert(struct Node *head, int x)
{
struct Node *newnode = new Node();
newnode->data = x;
newnode->next = head;
head = newnode;
return head;
}
// 反转函数
struct Node *Reverse(struct Node *head)
{
// 上一个节点 当前节点 下一个节点
struct Node *prev, *current, *next;
current = head; // 当前节点初始为头节点
prev = NULL; // 头节点的上一个节点是null
while (current != NULL)
{
next = current->next; // 先记录下下一个节点的地址,避免丢失
current->next = prev; // 将当前节点的地址位更改为前一个节点,达成链接
prev = current; // 将 前一个节点 往后更新一位
current = next; // 将 当前节点 往后更新一位
}
head = prev; // 将head更新为反转后的链表
return head;
}
// 打印函数
void Print(struct Node *node)
{
while (node != NULL)
{
cout << node->data << " ";
node = node->next;
}
cout << endl;
}
int main()
{
// 创建头节点 (局部变量)
struct Node *head;
// 插入数据
head = Insert(head, 2);
head = Insert(head, 4);
head = Insert(head, 6);
head = Insert(head, 8);
Print(head);
Print(Reverse(head));
return 0;
}优点:
可以避免额外的内存开销,并且能够保留节点中原有的数据关系。
递归遍历打印
迭代方法(从前到后遍历)通常更快,更节省空间,但代码可能不如递归方法简洁易懂。递归方法通常更容易理解和实现,但可能会导致栈溢出,并且时间复杂度和空间复杂度通常都比迭代方法高。
额,我的理解是这个知识点的存在是让我们知道有这样的写法 (如果有更深的意义,求指点!!)
因为这个不是很复杂,一些主要的思路和注意点我就标在注释里了,不再详细说啦。
直接上代码吧
#include<iostream>
using namespace std;
struct Node{
int data;
Node* next;
};
struct Node* head;
//从任意位置插入节点
void Insert(int situation,int data)
{
struct Node* temp1=new Node();
temp1->data=data;
temp1->next=NULL;
if(situation==1)
{
temp1->next=head;
head=temp1;
return;
}
struct Node* temp2=head;
for(int i=0;i<situation-2;i++)
{
temp2=temp2->next;
}
temp1->next=temp2->next;
temp2->next=temp1;
}
//传统迭代写法
void Print1()
{
//遍历
struct Node* temp=head;
while(temp!=NULL)
{
cout<<temp->data<<" ";
temp=temp->next;
}
cout<<endl;
}
//正向递归打印链表
void Print2(struct Node* temp)
{
//一定要判断链表是否为空,这是递归的出口!!
if(temp==NULL)return;
cout<<temp->data<<" ";
Print2(temp->next);
//cout<<endl;
}
//反向递归打印链表(这里只是逆序打印,并没有真正的反转链表)
void Print3(struct Node* temp)
{
if(temp==NULL)return ;
Print3(temp->next);
cout<<temp->data<<" ";
}
int main()
{
head=NULL;
Insert(1,2);
Insert(2,5);
Insert(3,9);
Print1();
Print2(head);
cout<<endl;
Print3(head);
return 0;
}疑问:
Print3()反转打印函数我最开始是这样写的
错误代码
void Print3(struct Node* temp)
{
while(temp!=NULL)
{
Print3(temp->next);
cout<<temp->data<<" ";
}
}好像是会死递归。但是为什么呢?while里面的判断条件不是递归的出口么? 而且我的理解是这里temp是局部变量,每次递归之后也就是temp->next作为temp来执行递归,到底为什么还会出现死递归呢?希望有大佬指点,非常感谢。
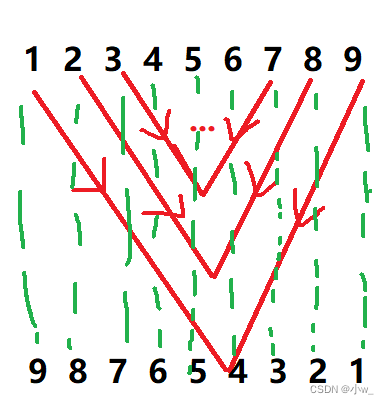
下面是我实现递归的图,实在是不知道哪里死循环了[秃]

递归反转
思路:
思想:从最后一个递归开始不断往前执行,最后一个节点先被赋给了头节点,接着返回上一个递归,实现将当前节点与新链表的第一个节点建立联系,与其后一个节点(递归的最后一个节点)切断联系,嗯,这里我感觉不是很好理解。有两种写法:
创建新节点存储当前节点(倒数第二个)的下一位节点(其实也就是最后一个节点,也就是在新链表中的第一个节点)
Node *q = p->next;//建立联系
q->next = p;//将原链表中的 需要递归的下一个节点 更新为当前节点这两行代码的作用是将当前节点 p 的下一个节点 q 的 next 指针指向当前节点 p,从而实现链表的反转。第一行代码 Node *q = p->next; 定义了一个指针变量 q,并将其初始化为指向当前节点 p 的下一个节点。第二行代码 q->next = p; 将当前节点的下一个节点 q 的 next 指针指向当前节点 p。这样,在回溯的过程中,每个节点的指针方向都被修改了,从而实现了链表的反转。
感觉这个不好懂👆
p->next->next=p;我更容易理解这个,首先p->next 表示原链表当前节点的后一个节点,然后再next 这样表示的就是原链表当前节点的后一个节点 即 新链表第一个节点的后一个节点 的值。
呜呜这个图挺不好画的[哭] (以正序 3 5 9 0 为例)

代码如下
#include <iostream>
using namespace std;
struct Node
{
int data;
Node *next;
};
struct Node *head;
//在链表末尾插入节点
void Insert(int x)
{
struct Node *temp1 = new Node();
temp1->data = x;
temp1->next = NULL;
if (head == NULL)
head = temp1;
else
{
Node *temp2 = head;
while (temp2->next != NULL)
temp2 = temp2->next;
temp2->next = temp1;
}
}
//递归反转
void Reverse(struct Node *p)
{
//首先就是考虑递归出口。当 当前节点的下一个节点为NULL的时候,说明链表只有一个节点,直接赋值return即可
if (p->next == NULL)
{
head = p;//这是最后一个递归,我们把head改成了p:最后一个节点成了新链表的头节点
return;
}
//如果链表中不止一个节点,那么执行递归
Reverse(p->next);
//当最后一个递归执行完之后,会接着执行倒数第二个递归中 递归之后的程序,也就是现在这个位置。后面的以此类推
/*
创建新节点存储当前节点(倒数第二个)的下一位节点(其实也就是最后一个节点,也就是在新链表中的第一个节点)
Node *q = p->next;//建立联系
q->next = p;//将原链表中的 需要递归的下一个节点 更新为当前节点
*/
p->next->next=p;//新链表中建立联系
p->next = NULL;//原链表切断联系
}
void Print(struct Node *temp)
{
if (temp == NULL)
return;
cout << temp->data << " ";
Print(temp->next);
}
int main()
{
head = NULL;
Insert(3);
Insert(5);
Insert(9);
Insert(0);
Reverse(head);
Print(head);
return 0;
}嗯,感觉这个不是很好理解,需要再琢磨琢磨。
好啦今天就写到这里啦。
如果有问题欢迎指出,非常感谢!!
也欢迎交流建议哦。

















 342
342

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









